-

Figure 1.
Sample images of different vehicle models from (a) the VehicleID and (b) VeRi-776 datasets.
-

Figure 2.
The pros and cons of the VehicleID dataset: (a) visible faces, (b) noisy red time stamp, (c) only two directions. (The images were captured in high quality).
-
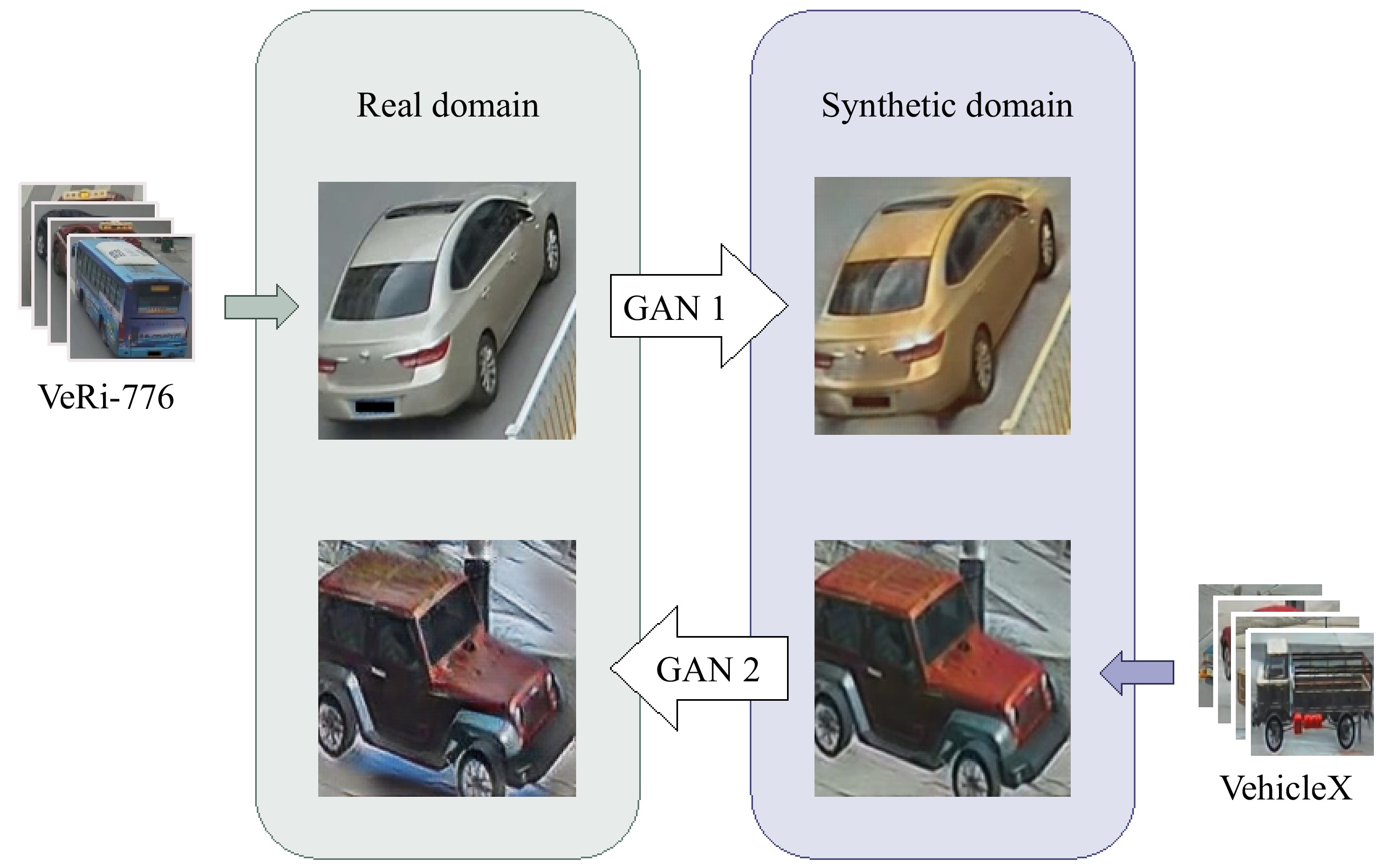
Figure 3.
CycleGAN model architecture transferring between VeRi-776 (real domain) and VehicleX (synthetic domain).
-

Figure 4.
Left: faces are blurred out, such that the privacy of the driver is ensured; Right: the timestamps in red are (partially) erased.
-

Figure 5.
Generated views by CycleGAN.
-

Figure 6.
Left: background removal; Right: cropped vehicles still look like vehicles.
-

Figure 7.
I spy with my convoluted eyes: (a) a taxi, (b) a bush, (c) an abstract self portrait, (d) a fence.
-

Figure 8.
VeRi-776: samples of (a) taxis and yellow fence, and (b) vehicles captured behind bushes and non-blackened out license plates.
-

Figure 9.
Comparing the two experiments: the outcomes of B are qualitatively more reliable than A.
-

Figure 10.
Generator loss, discriminator loss and forward cycle consistency loss curves per epoch for VCGAN-A and VCGAN-B.
-
VehicleID VeRi-776 VCGAN-A 37,778 37,778 VCGAN-B 113,346 37,778 Table 1.
Training data sizes for VCGAN-A and VCGAN-B.
Figures
(10)
Tables
(1)