-
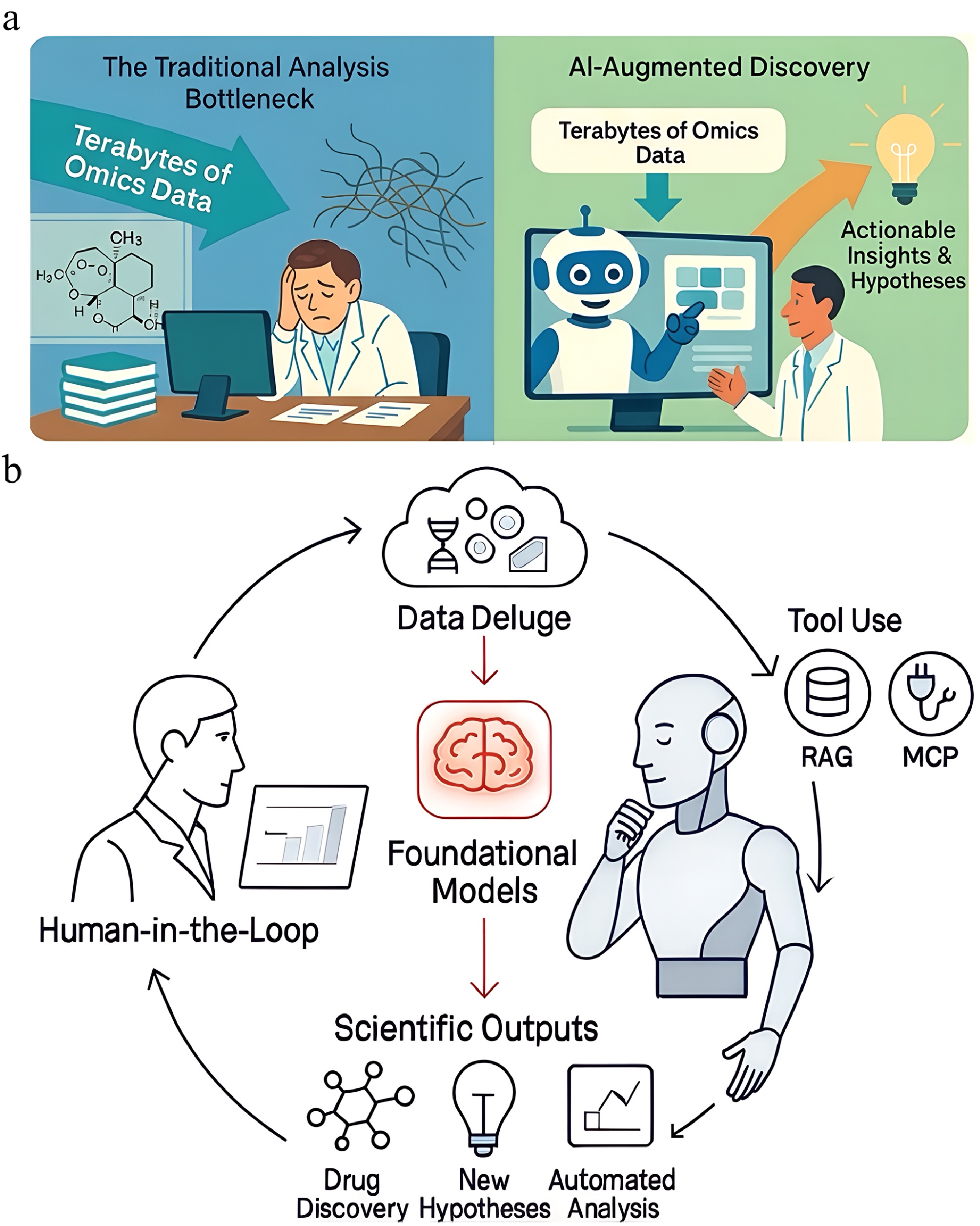
Figure 1.
The dawn of the digital biologist: a new paradigm for scientific discovery. (a) The shift from the traditional analytical bottleneck to AI-augmented discovery. On the left, a human scientist is overwhelmed by the complexity and scale of modern omics data, leading to a bottleneck that slows the pace of discovery. On the right, an AI agent acts as a collaborative 'digital biologist', empowering the human scientist by processing the same terabyte-scale data to generate actionable insights and testable hypotheses, thereby accelerating the research cycle. (b) A schematic of the iterative and collaborative workflow powered by AI. The cycle begins with the 'data deluge' from modern experiments, which is interpreted by 'foundation models' that serve as the core reasoning engine. The AI agent, operating within this framework, leverages specialized tools, such as those enabled by technologies like Retrieval-Augmented Generation (RAG) for accessing up-to-date knowledge and the Model Context Protocol (MCP) for interfacing with software to produce diverse 'scientific outputs'. These specific technologies (RAG, MCP) represent key opportunities for the field and will be detailed later in this review. These outputs can include automated data analysis, the generation of new hypotheses, and candidates for drug discovery. The 'human-in-the-loop' guides the process, evaluates the results, and refines the objectives, creating a powerful, cyclical partnership between human intuition and artificial intelligence.
-
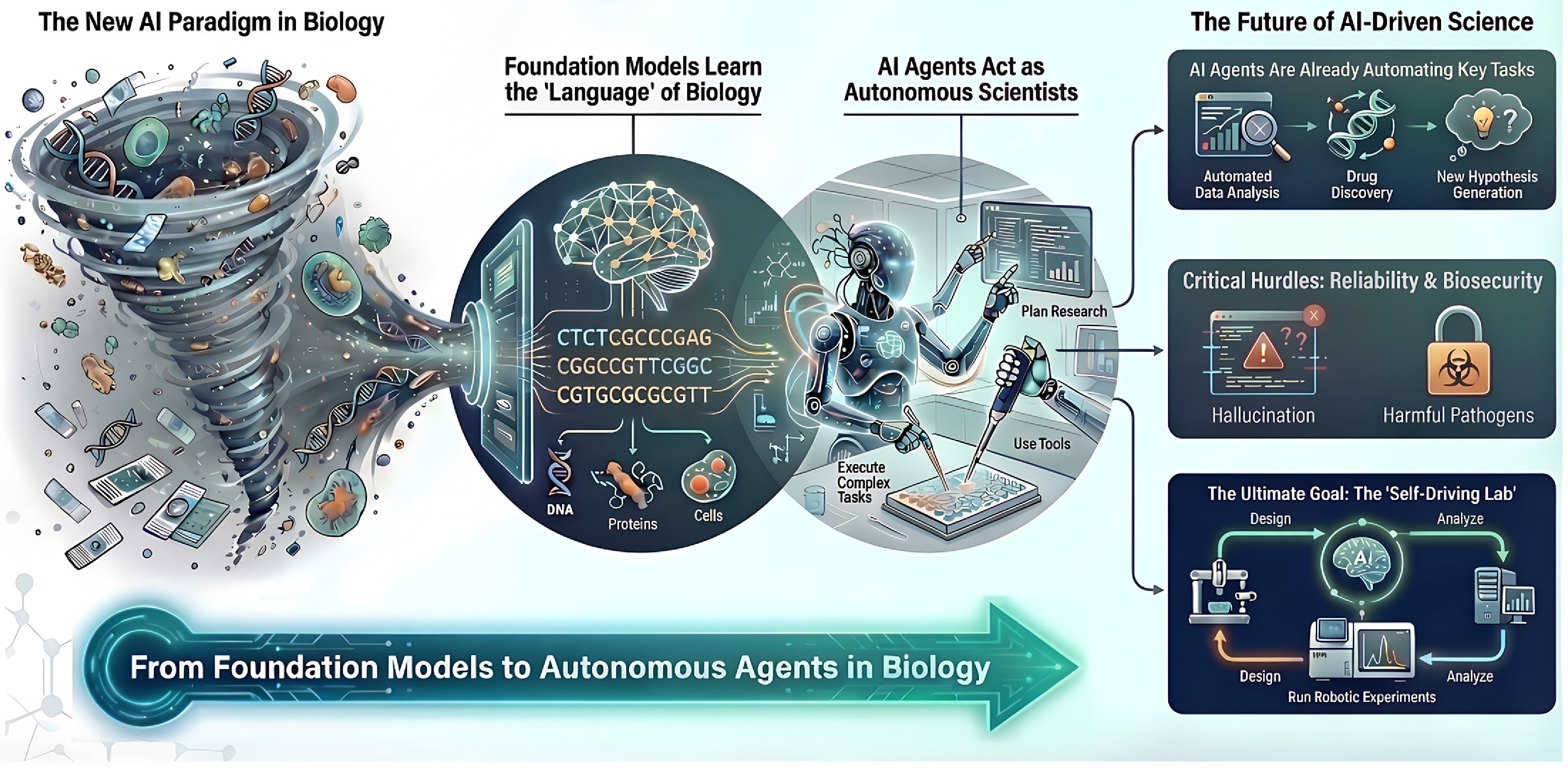
Figure 2.
Strategic roadmap for the era of AI-driven biology. This diagram outlines the structure of this review and the evolutionary trajectory of the field. The journey begins with foundation models (left), which ingest the 'data deluge' to learn the languages of sequences and cells. It progresses to autonomous agents (center), which leverage these models to act as active scientists capable of planning, tool use, and hypothesis generation. Finally, it points towards the future of discovery (right), addressing critical hurdles such as reliability and biosecurity, and envisioning the 'self-driving lab', where AI and robotics close the loop on scientific experimentation.
-
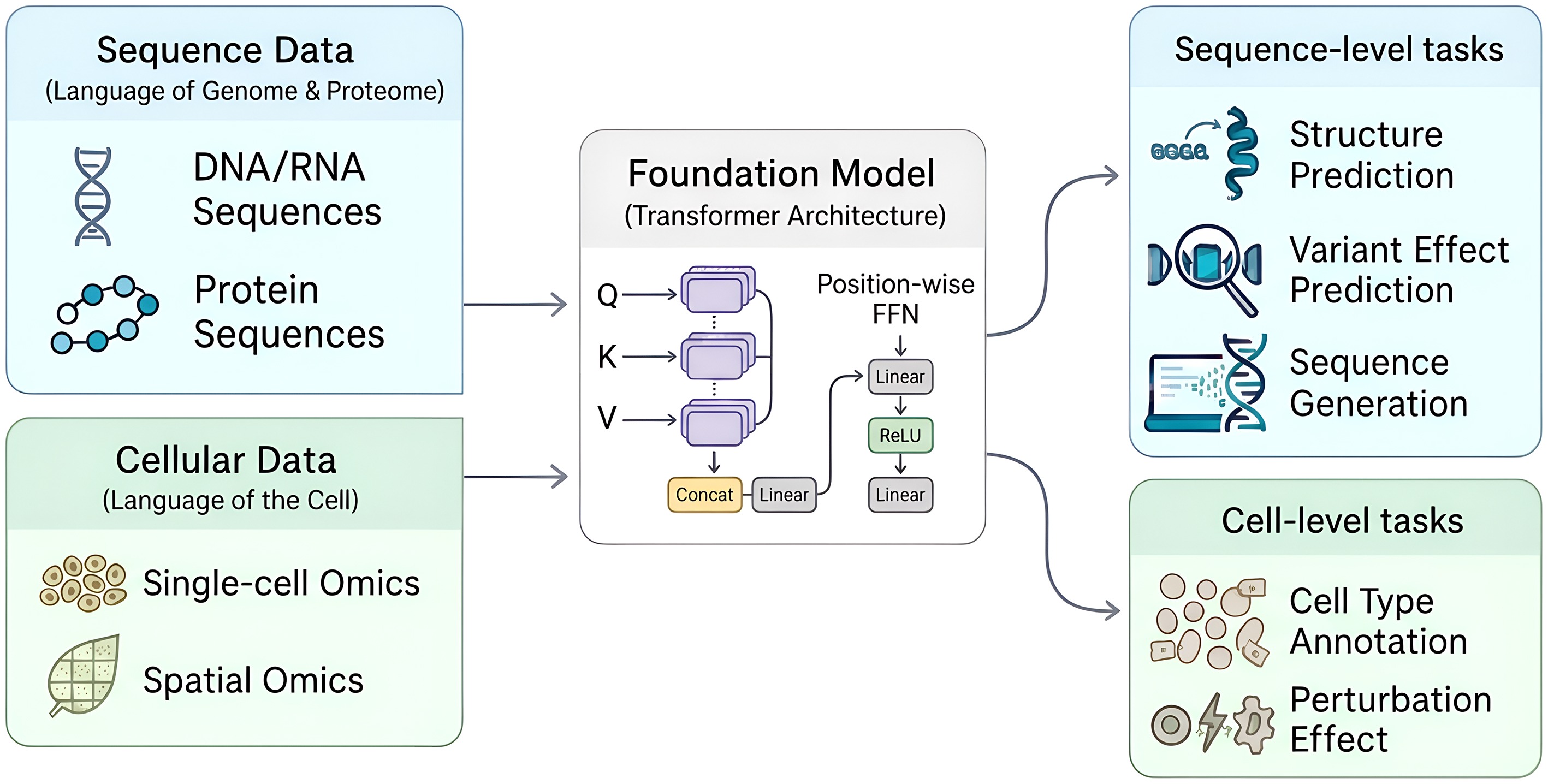
Figure 3.
Application of foundation models in biology. Foundation models are pre-trained on diverse biological data, including sequence data (DNA, RNA, proteins), and cellular data (single-cell, spatial omics). Using transformer architecture, these models learn fundamental representations of biological systems. The resulting models can then be applied to a wide range of downstream tasks (sometimes task-specifically fine-tuned), such as structure prediction and sequence generation at the sequence level, or cell type annotation and perturbation effect predictions at the cell level.
-
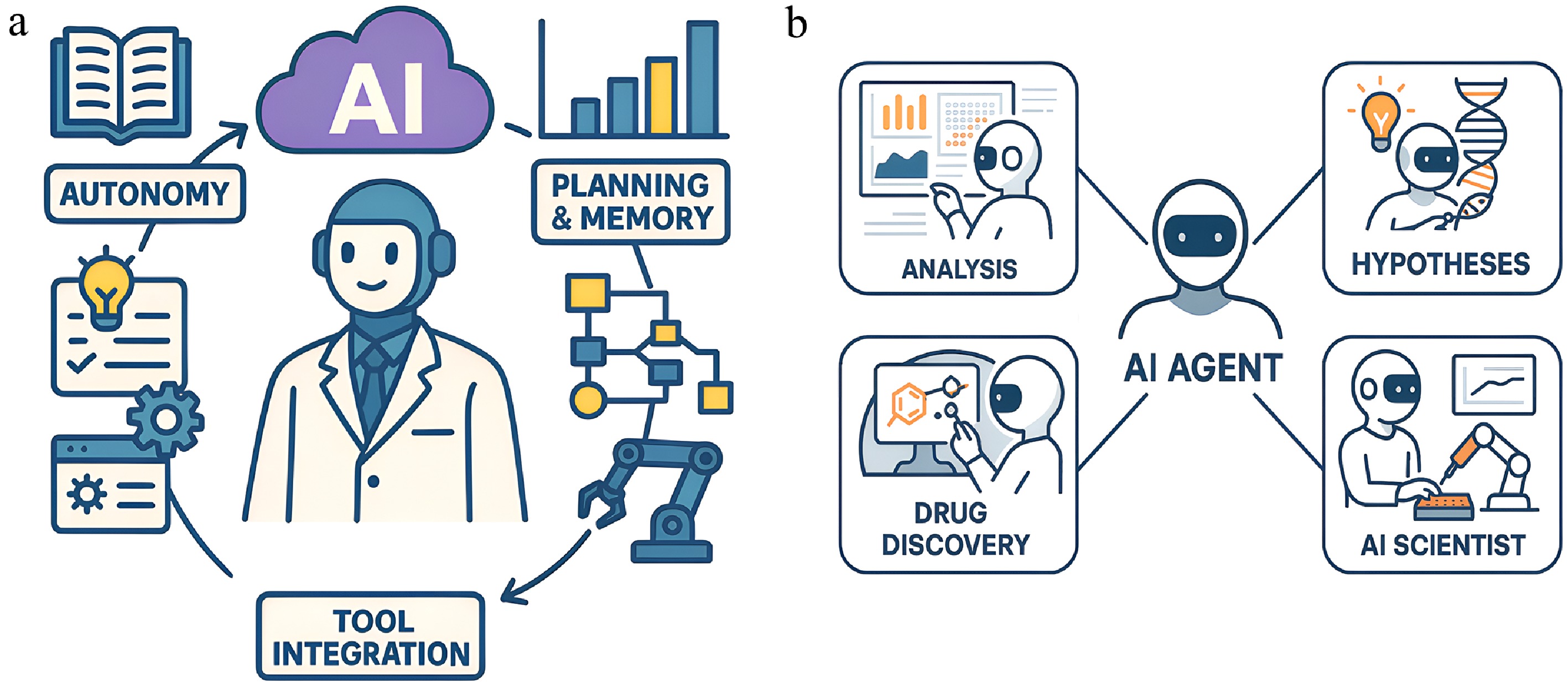
Figure 4.
Anatomy and applications of the AI agent in biology. (a) Core characteristics of an AI agent. An AI agent is defined by a set of core capabilities that enable it to act as an autonomous research partner. These include: (1) autonomy, the ability to operate without step-by-step human instruction by leveraging knowledge; (2) planning and memory, the capacity to devise multi-step strategies and maintain a working memory of a project; and (3) tool integration, the ability to interact with, and control external software, databases, or laboratory robotics. (b) Key application areas. By leveraging these core characteristics, AI agents are being deployed across a wide range of biological applications. These include automating complex data analysis, accelerating drug discovery by navigating vast chemical spaces, generating novel scientific hypotheses, and pursuing the ultimate goal of a generalist AI scientist that can design and orchestrate entire experimental workflows.
-
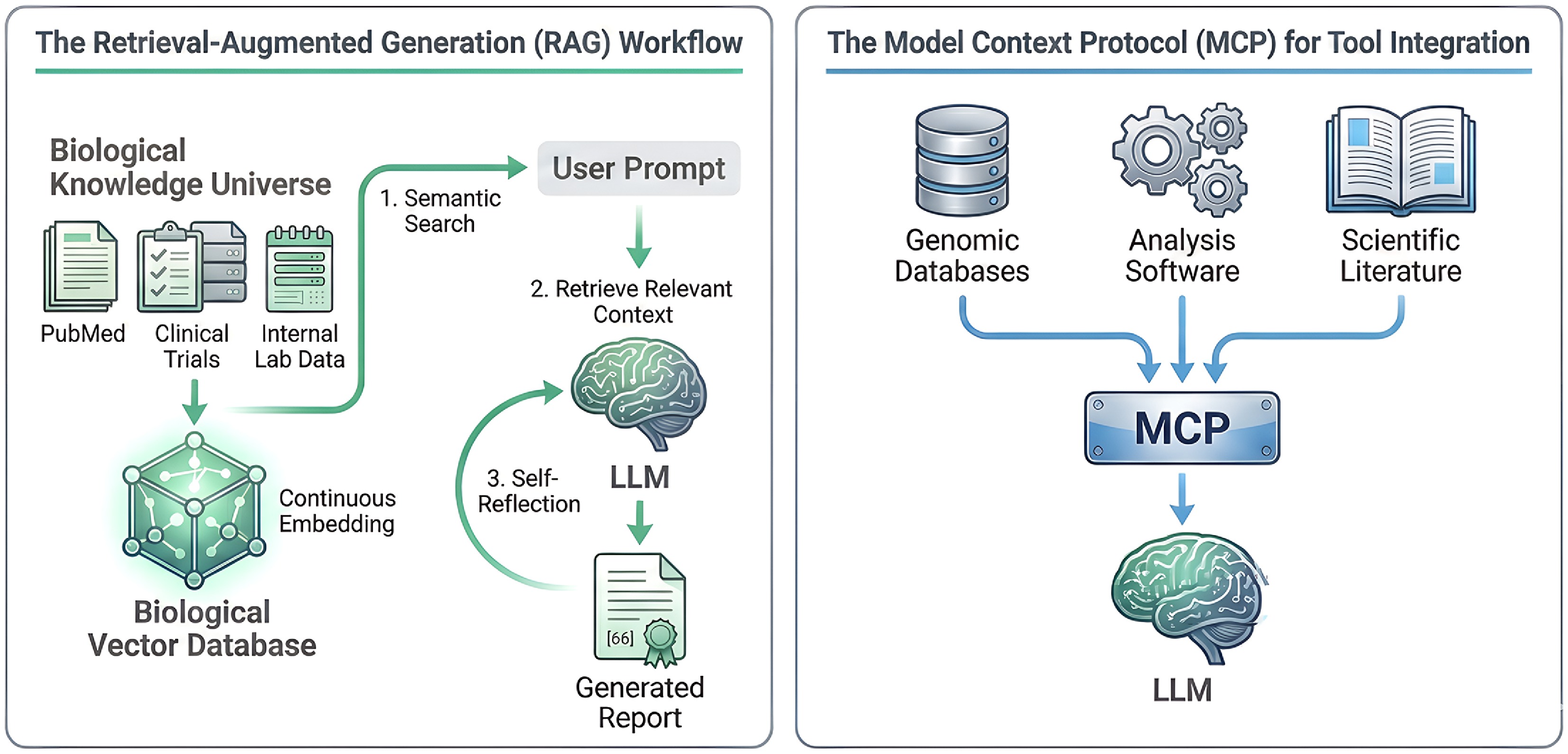
Figure 5.
Grounding AI agents with knowledge and tools. (Left) the Retrieval-Augmented Generation (RAG) workflow. To ensure factual accuracy, a diverse 'Biological Knowledge Universe' (e.g., PubMed, clinical trials, internal lab data) is converted into a 'Biological Vector Database'. When a user provides a prompt, a semantic search retrieves the most relevant context from this database. This information is then fed to the LLM, which uses it to generate a grounded and verifiable report, often incorporating a 'Self-Reflection' step to check its own output. (Right) the Model Context Protocol (MCP) for tool integration. MCP acts as a universal, standardized interface that allows an LLM to seamlessly interact with a wide array of external resources. This includes querying 'Genomic Databases', calling 'Analysis Software', or accessing the latest 'Scientific Literature'. By creating a common language for tool use, MCP simplifies the process of building context-aware agents that can leverage the best available resources for a given task.
-
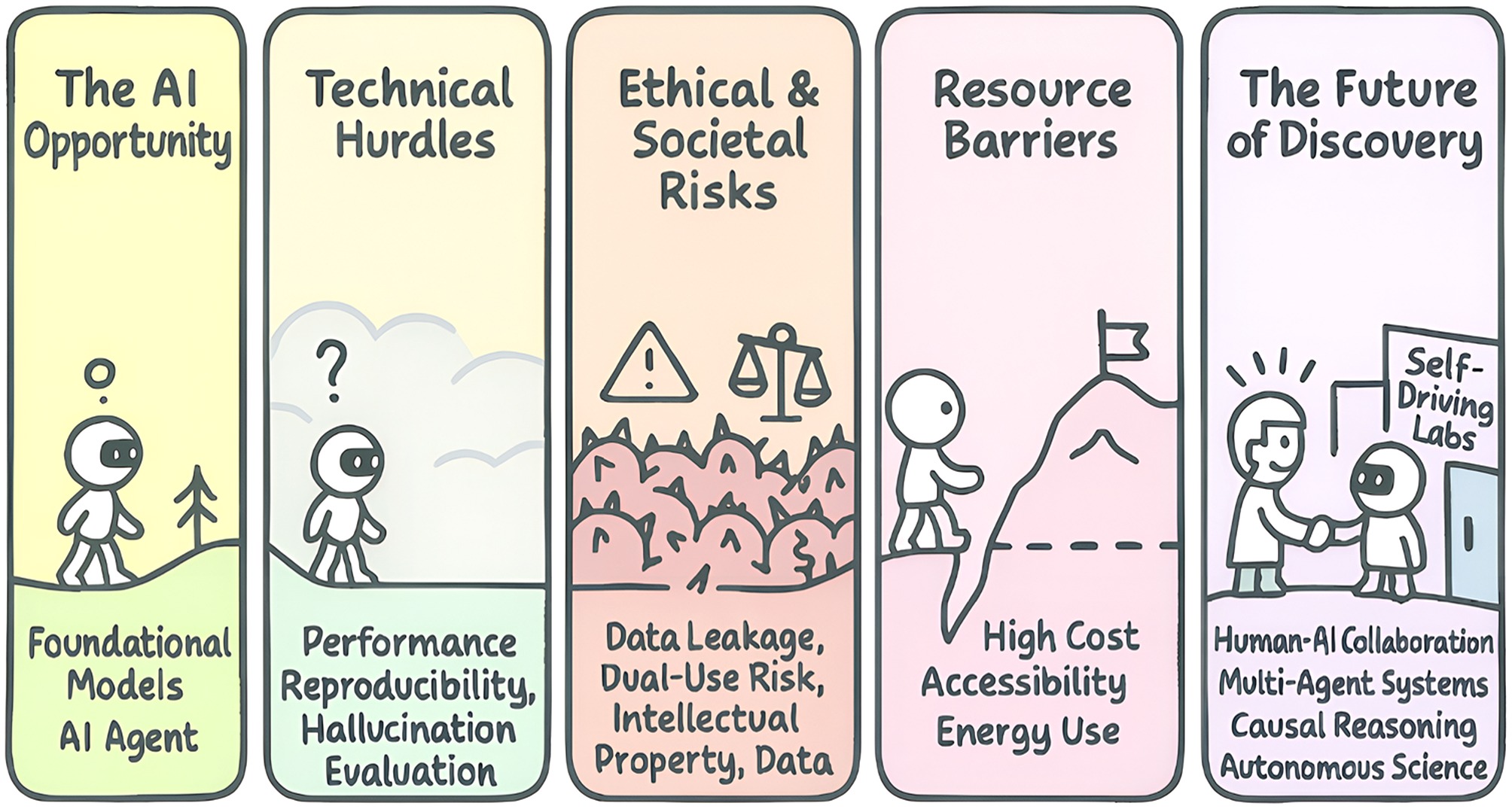
Figure 6.
The Path to trustworthy AI in biology: navigating challenges to unlock opportunities. This roadmap illustrates the progression from the core AI opportunity (foundation models and agents) to the future of discovery. This path requires overcoming technical hurdles (e.g., performance, hallucination), navigating ethical and societal risks (e.g., data privacy, dual-use), and breaking down resource barriers (e.g., cost, accessibility). Successfully doing so will enable a new era of science defined by human-AI collaboration, causal reasoning, and autonomous labs.
-
Model name Type Parameters Training hardware Accessibility DNABERT-2 Genome 117 M 8 RTX 2080Ti https://huggingface.co/zhihan1996/DNABERT-2-117M GenomeOcean Genome 100 M, 500 M, 4 B 64 NVIDIA A100 https://huggingface.co/DOEJGI/GenomeOcean-4B HyenaDNA Genome 1 K, 16 K, 32 K, 160 K,
450 K, 1 M8 NVIDIA A100 https://huggingface.co/collections/LongSafari/hyenadna-models Nucleotide Transformer Genome 100 M, 500 M, 2.5 B 128 NVIDIA A100 https://huggingface.co/collections/InstaDeepAI/nucleotide-transformer Nucleotide Transformer v3 Genome 8 M, 100 M, 650 M / https://huggingface.co/spaces/InstaDeepAI/ntv3 Evo2 Genome 1 B, 7 B, 40 B > 2,000x NVIDIA H100 https://huggingface.co/collections/arcinstitute/evo AlphaGenome Genome 450 M 512 GOOGLE TPU +
64 NVIDIA H100API only RiNALMo Genome 650 M 7 NVIDIA A100 https://zenodo.org/records/15043668 ESM3 Proteome 1.4 B, 7 B, 98 B / https://huggingface.co/EvolutionaryScale/esm3-sm-open-v1 xTrimoPGLM Proteome 1 B, 3 B, 7 B, 100 B 768 NVIDIA A100 https://huggingface.co/biomap-research/proteinglm-100b-int4 AlphaFold2 Proteome 93 M 128 GOOGLE TPU https://github.com/google-deepmind/alphafold AlphaFold3 Proteome / / Apply for academic usage BioEmu Proteome 31 M / https://huggingface.co/microsoft/bioemu ProGen2 Proteome 151 M, 764 M, 2.7 B, 6.4 B / https://github.com/salesforce/progen/tree/main/progen2 Table 1.
Computational landscape of major bio-foundation models.
Figures
(6)
Tables
(1)