-
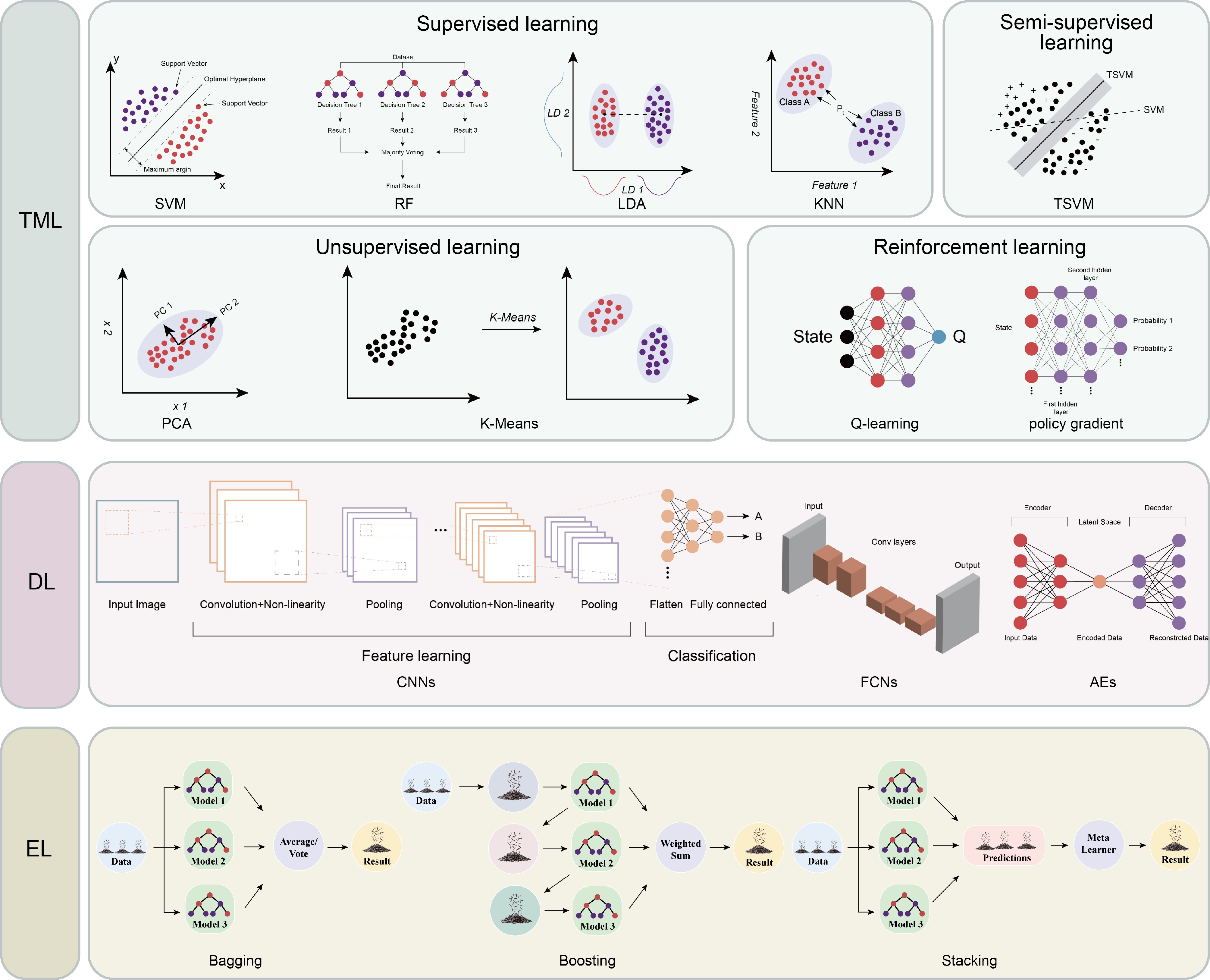
Figure 1.
Overview of machine learning (ML) methodologies. Visualization of ML approaches organized into three principal categories: traditional machine learning (TML), deep learning (DL), and ensemble learning (EL). TML encompasses supervised learning (exemplified by SVM, RF, LDA, and KNN), unsupervised learning (featuring PCA and K-Means Clustering), semi-supervised learning (represented by TSVM), and reinforcement learning (depicting Q-learning and policy gradient). DL demonstrates specialized neural network architectures, including CNNs, FCNs, and AEs. EL portrays integration strategies including bagging, boosting, and stacking.
-
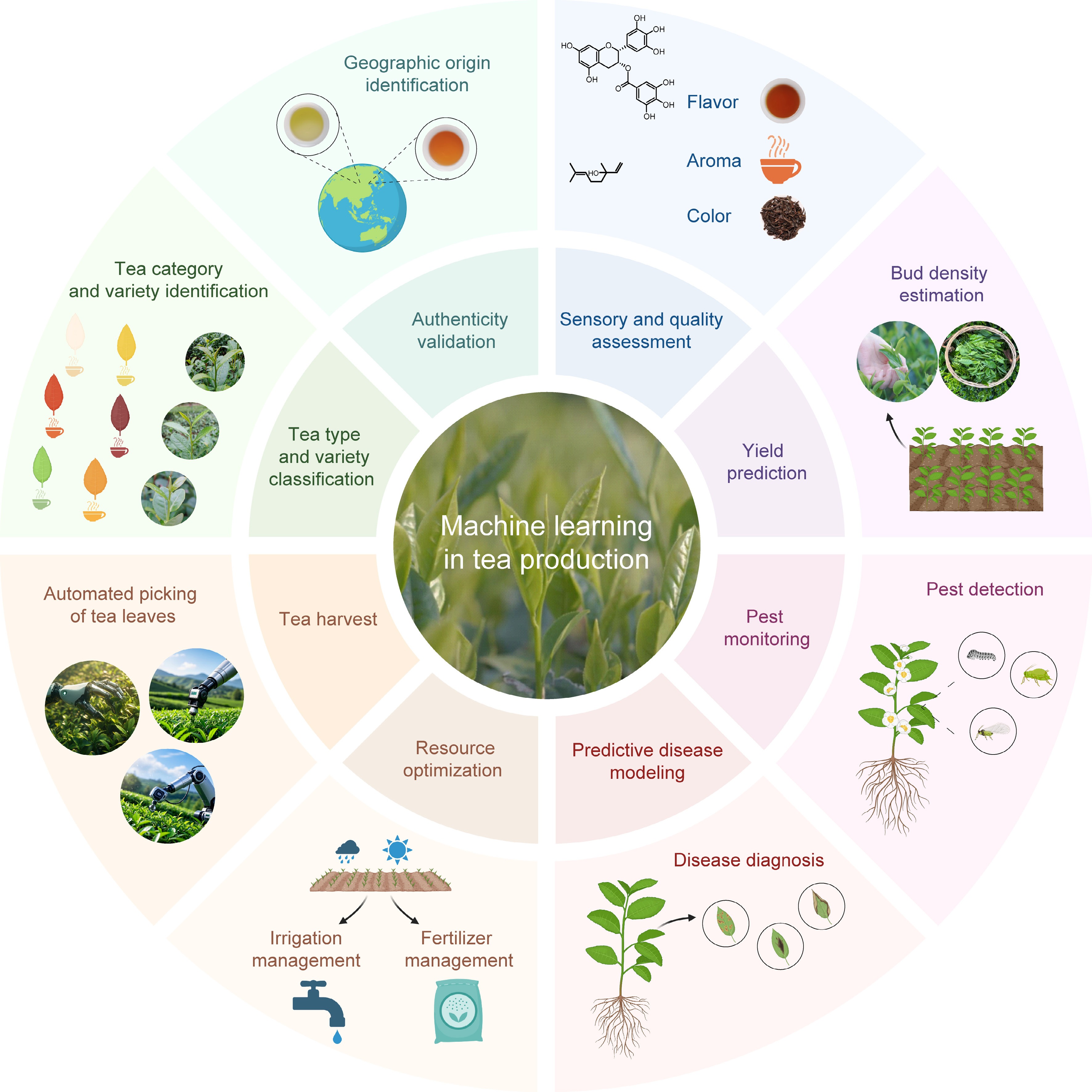
Figure 2.
ML applications in tea industry systems. This schematic depicts key applications of MLs throughout the tea value chain, including geographic origin authentication, tea variety classification, sensory quality assessment, yield prediction, resource optimization, pest monitoring, disease diagnosis, and automated harvesting.
-
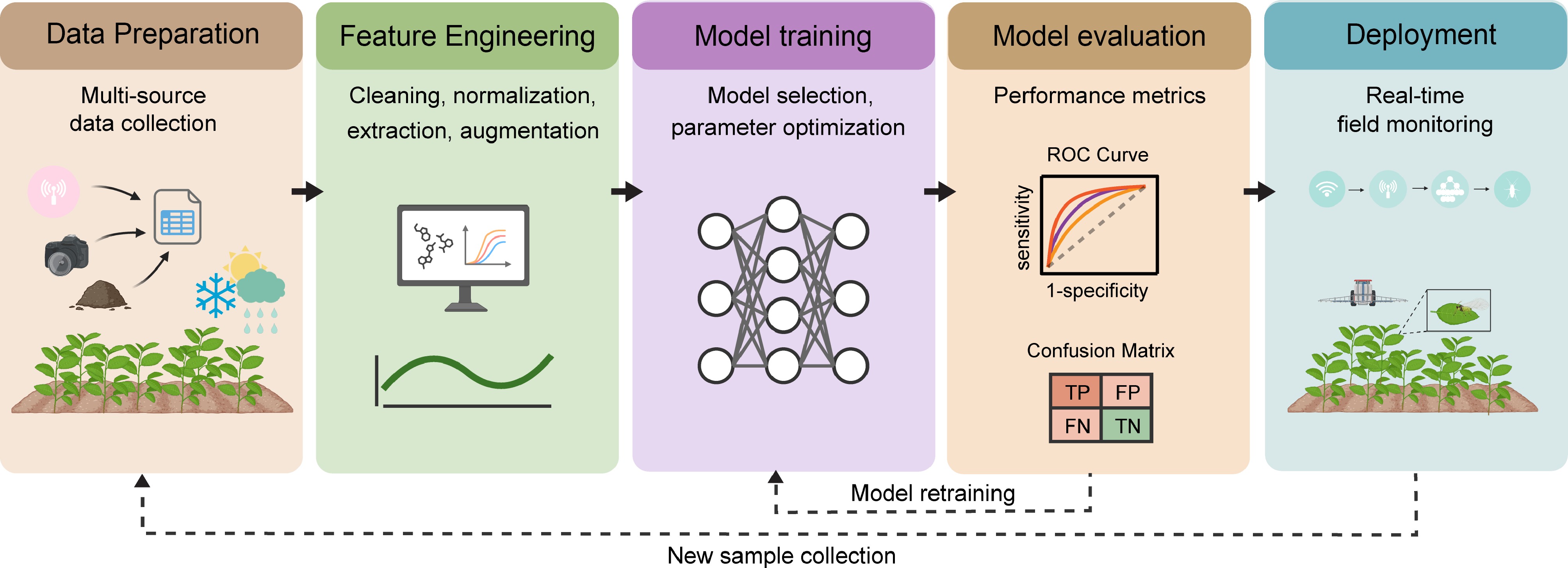
Figure 3.
Structured workflow of ML pipeline implementation for tea-specific applications. Systematic representation of the end-to-end ML pipeline encompassing sequential stages: multimodal data acquisition and preprocessing, domain-specific feature engineering, model architecture selection and hyperparameter optimization, comprehensive performance evaluation, and deployment with edge computing integration. The pipeline incorporates feedback mechanisms for continuous model refinement based on operational data and evolving environmental conditions.
-
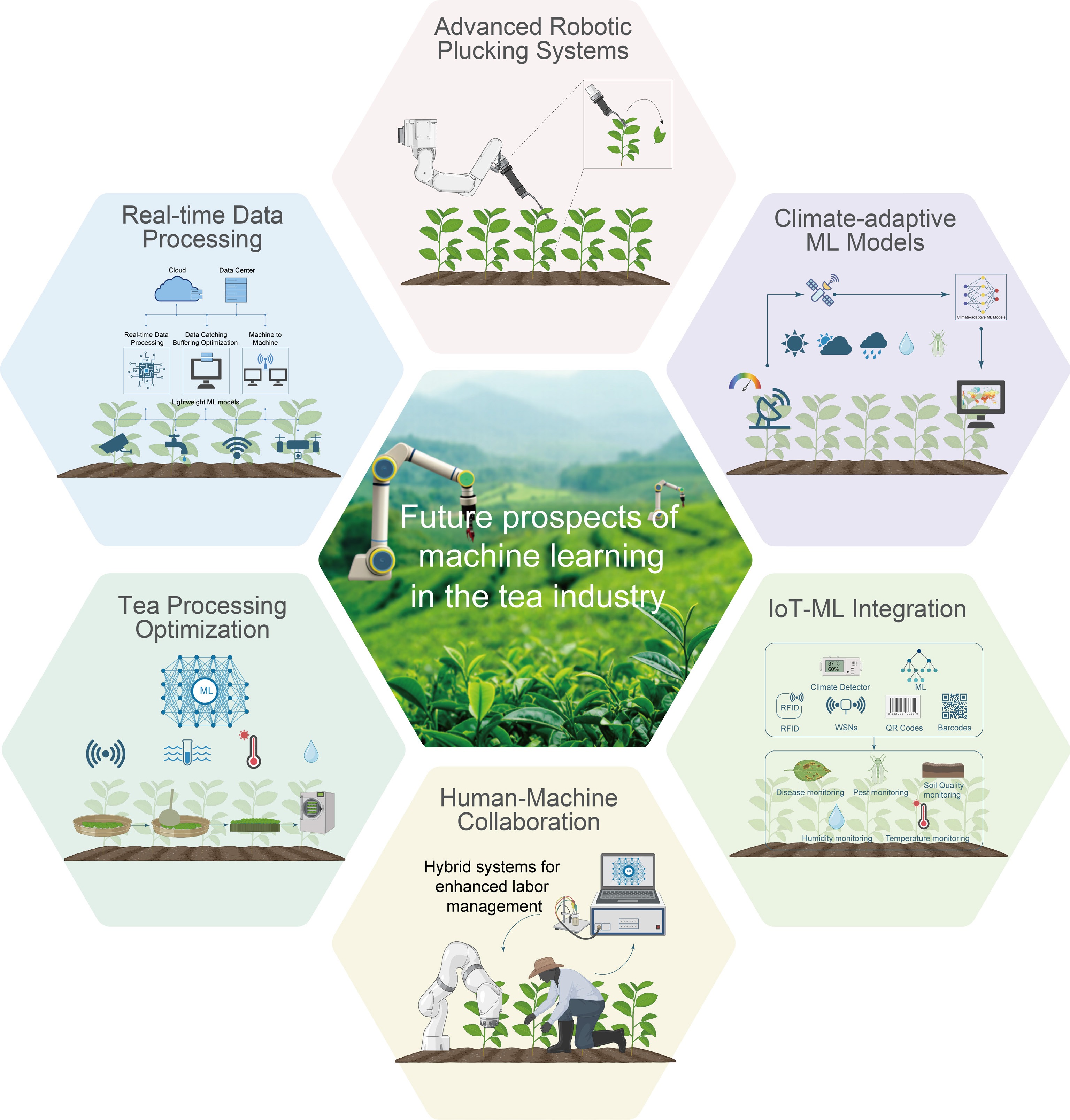
Figure 4.
Future prospects of ML applications in tea industry. Key future ML applications in tea industry include robotic plucking, real-time data processing, climate-adaptive models, processing optimization, IoT integration, and human-machine collaboration.
-
Stage Description Relevance to tea tasks Example tools/techniques Data preparation and feature engineering Data integration, preprocessing
(e.g., scaling, normalization), augmentation, feature extraction, and selectionIntegrates diverse tea-specific data: leaf images, NIR/hyperspectral scans, soil parameters, and weather metrics, and electronic tongue/nose readings. Augmentation simulates field conditions to improve model robustness. H2O-AutoML, PCA, mutual information, recursive feature elimination, image rotation/brightness adjustment Model training and optimization Model selection, hyperparameter optimization, iterative refinement Optimizes models for tea-specific tasks: disease detection, quality grading, yield prediction, and fermentation monitoring. Balances accuracy with computational efficiency for field deployment. Bayesian optimization, evolutionary algorithms, MobileNetV2, CNNs for disease detection, RNNs for fermentation monitoring Model evaluation Performance metrics (accuracy, precision, recall, F1-score, R² and RMSE), cross-validation, error
analysisValidates model reliability across different tea varieties, regions, and seasonal conditions. Identifies specific error patterns in tea-related predictions and classifications. K-fold cross-validation, confusion matrix analysis, performance comparison tools, learning curve visualization Deployment Architecture optimization, model compression, edge computing implementation, IoT integration Enables field-level applications: real-time disease detection, harvest optimization, and processing monitoring through lightweight models on portable devices and sensor networks. NAS, AutoML for Model Compression (AMC), MobileNetV2, edge-AI frameworks, IoT sensor integration for tea estate monitoring Table 1.
Key components of an ML pipeline for tea-related tasks.
Figures
(4)
Tables
(1)