








-
Urban traffic congestion has become a global issue and caused severe effects, such as increased travel time, fuel consumption, and air pollution[1−3] It has serious implications for the global economy and the environment. For example, in recent years, the USA alone lost $87 billion per year in extra driving time and gasoline due to traffic jams[4,5].
Inadequate traffic infrastructure, the rapid growth of vehicles, and pre-determined traffic signal control (TSC) methods are the leading causes of urban traffic congestion[6]. Addressing urban planning and infrastructure concerns necessitates significant financial and material resources. As a result, improving the existing TSC methods is the most cost-efficient way to relieve traffic congestion.
In recent years, significant progress has been made on reinforcement learning (RL) for solving various sequential decision-making problems in Artificial Intelligence (AI) games, such as Atari[7], Go[8], and Dota2[9,10]. The TSC problem can be regarded as an agent that can make decisions at intersections by interacting with the environment, just like in a game.
It is challenging to alleviate traffic congestion by optimizing and controlling traffic signals only at a single intersection[11]. TSC is being extended from optimization of a single intersection to multiple intersections, which can be formulated as a multi-agent system with cooperation between agents. Hence, multi-agent reinforcement learning (MARL) has been receiving more attention from researchers in these years[12−14]. Furthermore, considering the network transmission and communication between traffic lights, efforts toward efficiently deploying MARL in practice has remained a research challenge.
Additionally, most research focused on lab theories and algorithms with few considerations of industrial-scale deployment issues. With the limited capabilities of the network transmission bandwidth and underlying computing resources, optimizing the deployment structure and algorithmic performances for TSC is essential for intelligence transport systems (ITS).
ITS-related technologies, such as urban traffic simulation environments[15−18], TSC algorithms[19,20], and traffic signal communication[14,21], have considerably enhanced traffic operation and management. To the best of our knowledge, there is rare research considering all aspects above for TSC, and few works can be deployed in the real-world. We summarize several existing challenges in TSC:
1) Although some studies have contributed to multi-intersection TSC[22−24], it lacks an integrated architecture to leverage the traffic simulation environment, cooperative TSC algorithm, and traffic signal communication to achieve optimal multi-intersection TSC;
2) Traditional algorithms in urban TSC rarely consider traffic light cooperation and communication simultaneously;
3) Most studies optimize the algorithms but ignore the network capacity or latency in the urban TSC process.
To address the aforementioned challenges, an integrated and cooperative architecture for TSC across multiple intersections is proposed in this paper. The main contribution is threefold:
1) An integrated architecture, namely General City Traffic Computing System (GCTCS), is proposed, which integrates an urban traffic simulation environment, TSC algorithm, and communication across the traffic signal network simultaneously.
2) A MARL algorithm, namely General-MARL, is developed for TSC based on GCTCS, considering cooperation and communication between traffic lights.
3) Comprehensive experiments have been conducted to validate the proposed architecture and algorithm with promising results. From experimental results, our novel architecture is much closer to the real-life traffic environment. With the proposed algorithm, the average speed of vehicles is increased by 23.2%, and the network latency is reduced by 11.7% compared with baseline algorithms.
The remainder of this paper is organized as follows: Section Related Work introduces related works. Section Preliminary explains the basic concepts and problem definition. Section Methodology describes the architecture of GCTCS and details the General-MARL method for cooperative traffic light control based on GCTCS. Section Experiments conducts experiments to demonstrate the advantage of the General-MARL algorithm. Section Conclusions concludes the paper and discusses future work.
-
In this section, we discuss and introduce studies on the TSC, which can be divided into two typical categories: Conventional approaches and RL-based methods.
Conventional methods for TSC
-
Conventional TSC methods are classified into four types: fixed-time control[25], actuated control[26], adaptive control[27], and optimization-based control[28]. Fixed-time is a conventional and primary method of urban TSC, benefiting from the simplicity of deployment. It usually consists of a pre-timed cycle length, fixed cycle-based phase sequence, and phase split. While calculating the cycle length and phase split, the traffic flow is assumed to be uniform during a specific period. Since introduction in the 1950s[25], it has been a leading solution to TSC in practice considering that the urban traffic environment is complex and uncertain, and mathematical approaches cannot precisely build a model from internal operational mechanisms of a TSC system. Actuated control[26] decided whether to keep or change the current phase based on the pre-defined rules and real-time traffic data. It could set the green signal for a specific traffic signal phase if the number of approaching vehicles is larger than a threshold. Based on traffic volume data from loop sensors, adaptive control[27] created a set of traffic plans and chose the one that was best for the current traffic situation. Optimization-based control[28] formulated TSC as an optimization problem under a dynamic traffic flow and decided the traffic signal according to the observed traffic information. All of the methods discussed above heavily rely on human-designed traffic signal plans or rules.
RL based methods for TSC
-
RL-based methods have emerged as a promising TSC solution, which are designed for different application scenarios including single intersection control[11,29], and multi-intersection control[30,31].
Single intersection control
-
Abdulhai et al. [11] introduced Q-learning for TSC and presented a case study involving application to traffic signal control. Li & Wang[29] proposed the idea to set up a deep neural network (DNN) to learn the Q-function of reinforcement learning from the sampled traffic state/control inputs and the corresponding traffic system performance result. Park et al.[32] developed two traffic signal control models using reinforcement learning and a microscopic simulation-based evaluation for an isolated intersection. Additionally, the models could also be adapted for two coordinated intersections.
Multi intersection control
-
Multi-agent reinforcement learning (MARL) involves the participation of more than one agent[12]. It can learn through the cooperation of (1) sharing instantaneous information through interaction with the environment and (2) sharing learned policies in episodic experience.
MARL is a suitable method for the TSC problem, which can be solved as a typical MARL system for optimization of all intersections[13,14]. There exist intelligent traffic agents in the environment that can facilitate learning progress in MARL. Co-DQL model[12] used a highly scalable independent double Q-learning method based on double estimators and the upper confidence bound (UCB) policy for multi intersections. Wang et al.[13] proposed two distributed MARL control models as well as a Federated Learning (FL) framework to solve the ATSC problem, where the former is based on Advantage Actor-Critic (A2C) algorithm, and the latter is based on Federated Averaging (FedAvg) algorithm. El-Tantawy et al.[30] investigated the following dimensions of the control problem: (1) RL learning methods, (2) traffic state representations, (3) action selection methods, (4) traffic signal phasing schemes, (5) reward definitions, and (6) variability of flow arrivals to the intersection. Rasheed et al.[31] designed a multi-agent DQN (MADQN) and investigated its use to further address the curse of dimensionality under traffic network scenarios with high traffic volume and disturbances. El-Tantawy et al.[30] introduced a multi-agent auto communication (MAAC) algorithm, which is an innovative adaptive global traffic light control method based on multi-agent reinforcement learning (MARL) and an auto communication protocol in edge computing architecture. The MAAC model considered traffic communication but did not leverage MARL and traffic simulation environment optimization.
From the literature, we find that most studies attempt to develop an RL or MARL model to address the TSC problem directly, ignoring the traffic simulation environment optimization and traffic communication simultaneously.
-
In order to create models for simulating complex traffic dynamics, urban traffic simulation systems typically integrate computing technologies and operational features of traffic flow (as illustrated in Fig. 1). Road network, vehicle description, traffic signal control, and communication between the simulation system and traffic equipment are typically the basic elements of an urban traffic simulation system.
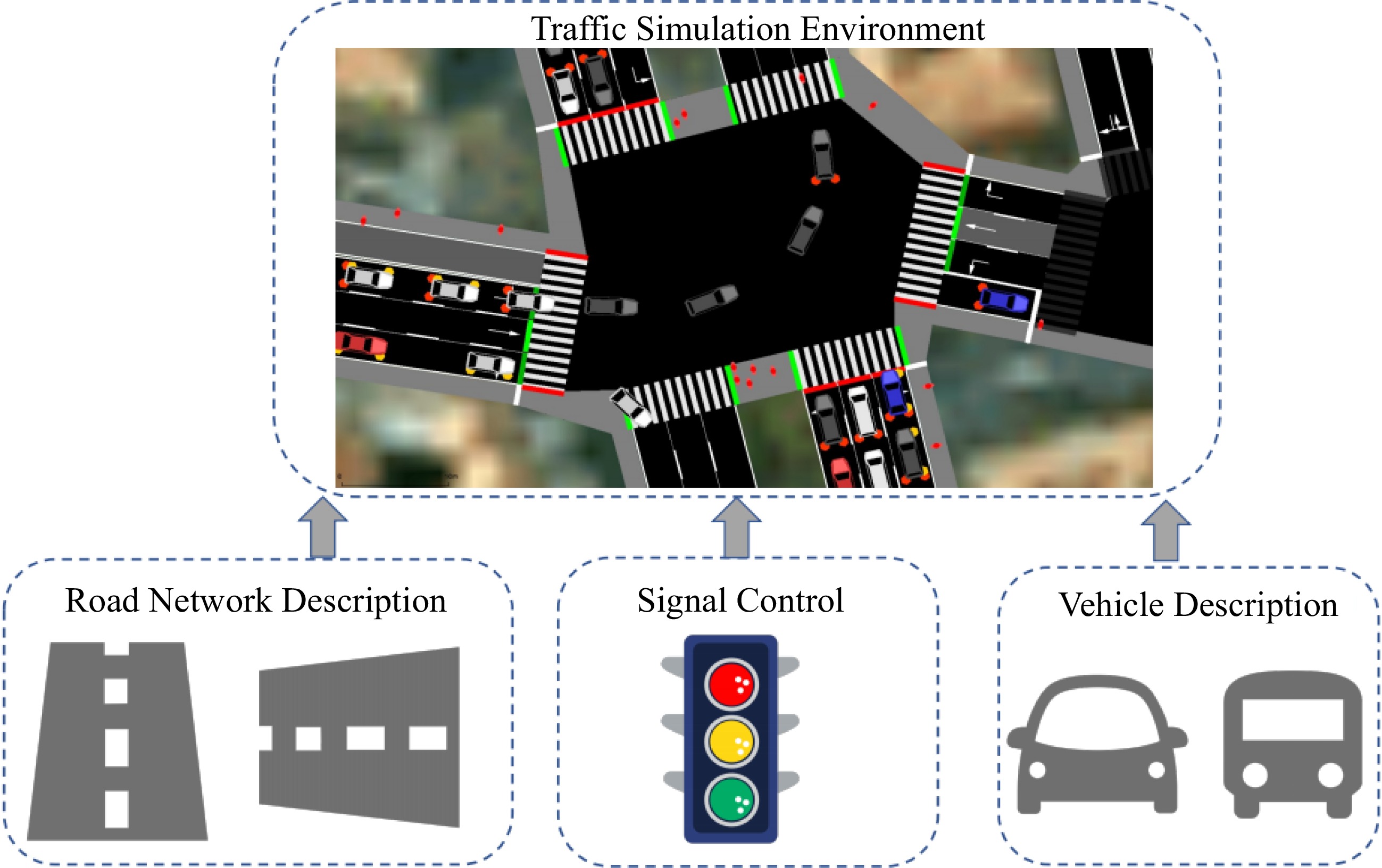
Figure 1.
An urban traffic simulation environment for traffic research.
The traffic simulation system can be divided into two groups: the commercial and open-source system. VISSIM[33] and Paramics[34] are widely used as commercial traffic simulation systems. While, open-source systems, such as MIT Simlab[15], SUMO[16], CityFLow[17] are usually adopted by researchers.
Traffic computing structure
-
Communication is one of the key functions in cooperation, which usually suffers from inevitable network latency. However, relevant studies on the development and deployment of computing frameworks often ignore the network delay in communication. In general, there are three major IoT computing structures, namely cloud computing[35], fog computing[21], and edge computing[36].
Cloud computing is a ubiquitous, convenient, and on-demand repository of computing resources such as networks, servers, and storage. Fog computing is closer to where data is generated than cloud computing. Edge computing and data processing are performed at the nearest location where terminal devices generate the data.
Problem definition
-
The TSC problem can be regarded as an agent that can make decisions at intersections by interacting with the environment.
It can be formulated as an Markov Decision Process (MDP)[37] (
$ \left\langle{S,A,P,R,\pi ,\gamma }\right\rangle $ $ \pi $ $ \gamma \in \left[\mathrm{0,1}\right] $ 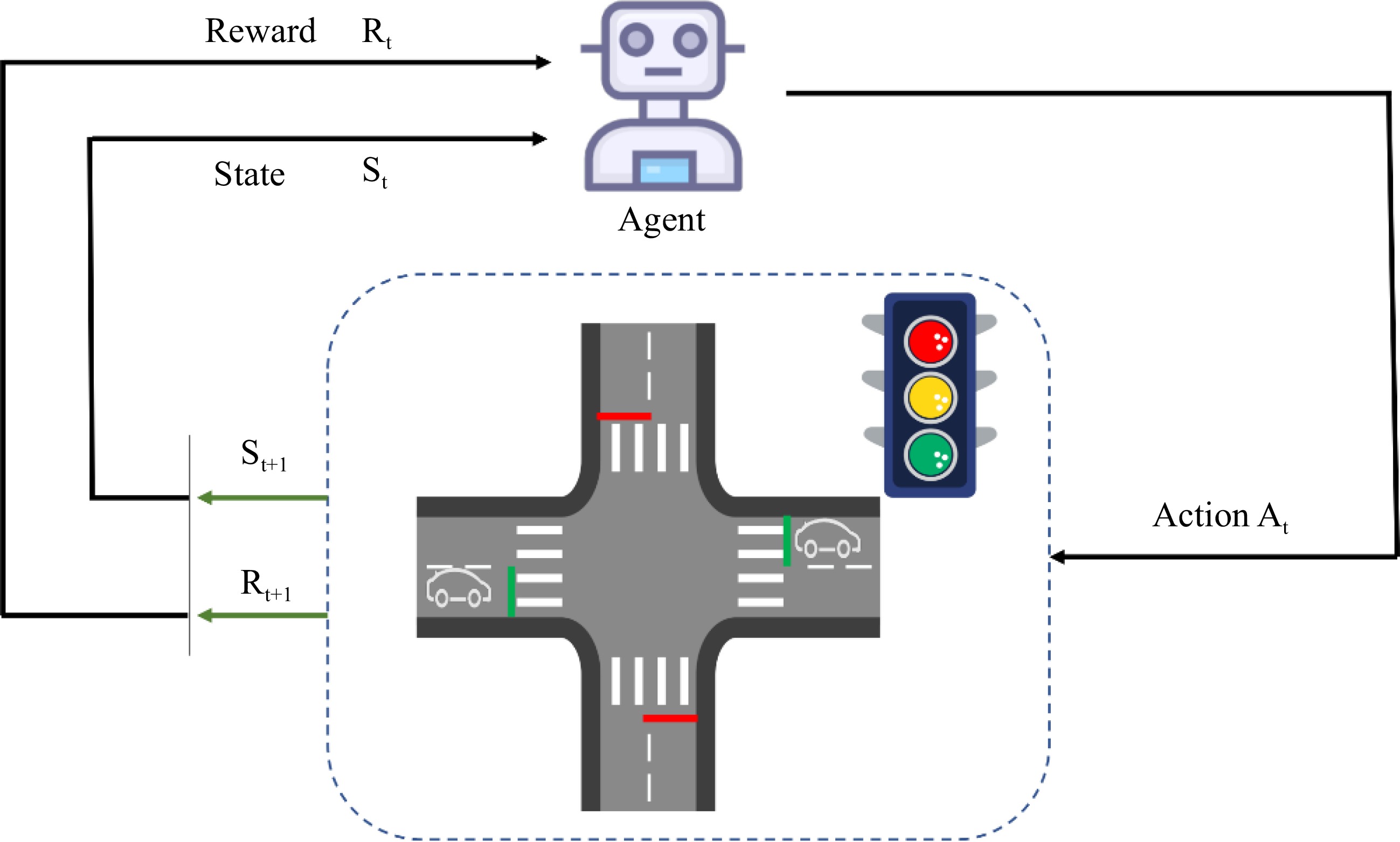
Figure 2.
An illustration of traffic signal control at an intersection. According to the current traffic state $ {S}_{t} $ and the reward $ {R}_{t} $, the agent selects and executes the corresponding action $ {A}_{t} $ (change or maintain the current traffic light). Then the agent evaluates the effects of the action to obtain a new traffic state $ {S}_{t+l} $ and a new reward $ {R}_{t+1} $.
In this paper, we formalize the TSC problem as decentralized intersection optimization by MARL for multi-intersection (as shown in Fig. 3). Each intersection
$ {I}_{i} $ $ {A}_{i} $ $ t $ $ {A}_{i} $ $ {\mathrm{S}}_{i} $ 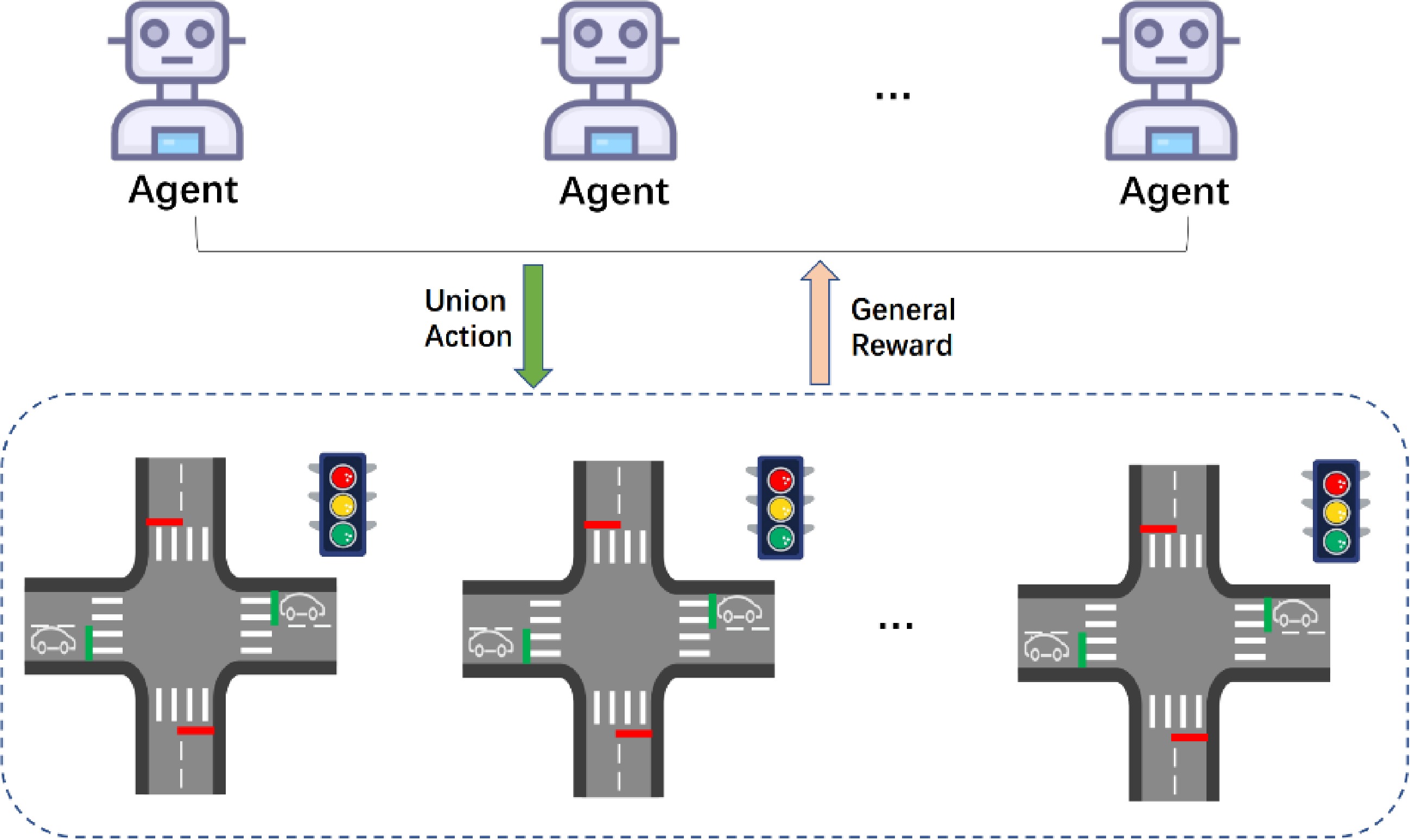
Figure 3.
The MARL structure in urban traffic signal control.
$ min{T}_{i}^{{I}_{i}\left({A}_{i}\right({\mathrm{S}}_{i}\left)\right)} $ (1) where
$ {T}_{i}^{{I}_{i}\left({A}_{i}\right({\mathrm{S}}_{i}\left)\right)} $ $ {I}_{i} $ $ {A}_{i} $ $ {\mathrm{S}}_{i} $ In a multi-agent system, the cooperation between agents is usually based on one computing structure. Thus, an effective and efficient integration solution covering different aspects is needed for TSC in practice.
-
In this section, we introduce an integrated and cooperative architecture, i.e., GCTCS, for urban TSC across multiple intersections. It integrates an urban simulation environment, a hybrid computing framework (cloud computing, fog computing, and edge computing), an interface for TSC algorithm deployment, a dynamic prediction module of traffic flow for traffic configuration interface, and an edge computing node of real-time traffic video processing[38].
The development of GCTCS is to support more synthetic and efficient TSC experiments involving multiple intersections and to provide simulation data that are closer to real traffic conditions for industrial deployment, as shown in Fig. 4.
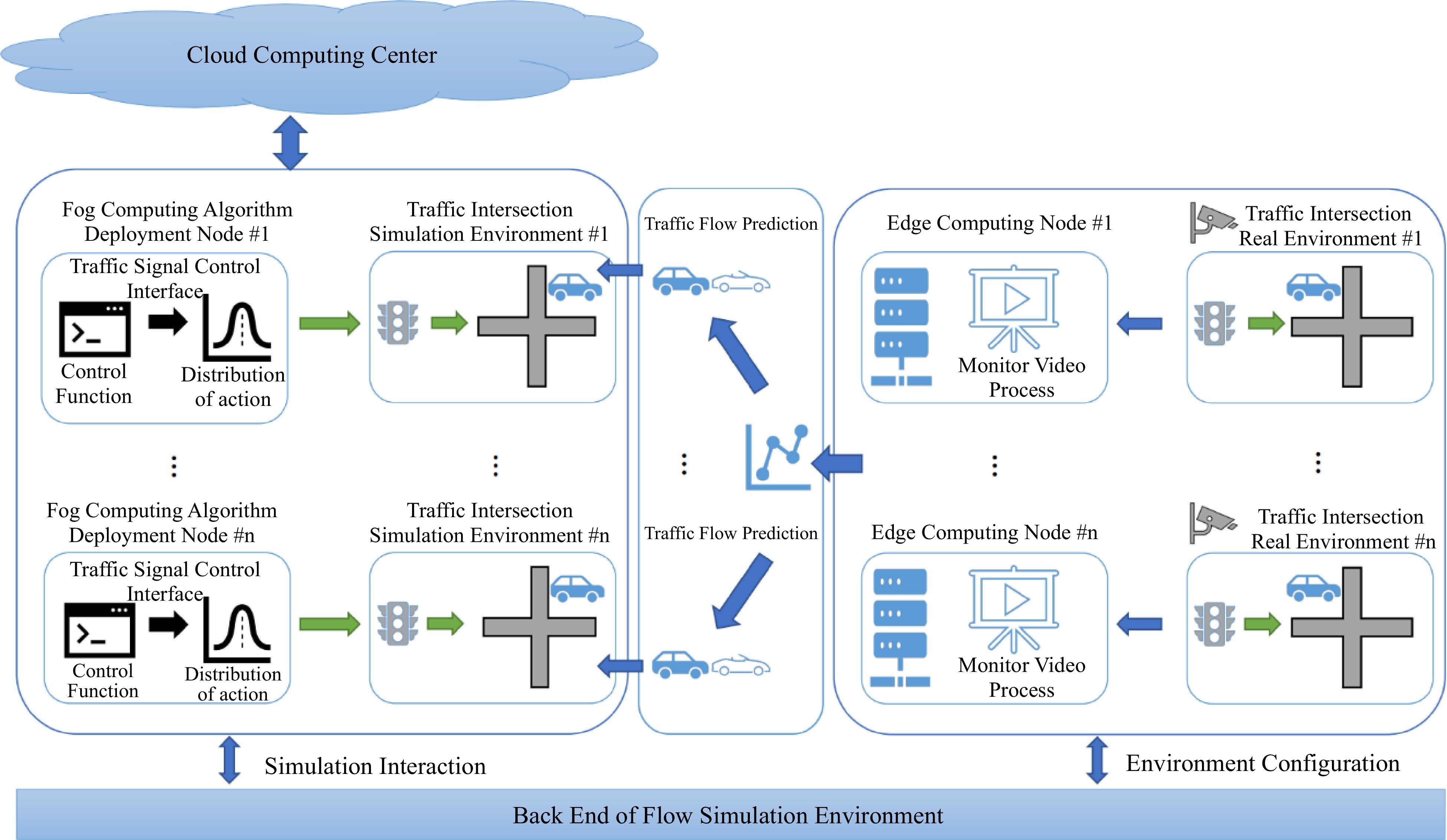
Figure 4.
The General City Traffic Computing System (GCTCS) for urban traffic signal control.
GCTCS dynamically connects the simulation environment with the natural environment of multi-intersection traffic signals; provides urban TSC algorithm interfaces deployed under the hybrid computing architecture of cloud computing, fog computing, and edge computing; and takes complete account of network bandwidth and network delay. GCTCS can break through the barrier between the real traffic flow across multiple intersections and the traffic flow configuration of the simulation environment and realize dynamic synchronization between the real environment and the simulation environment. In addition, the overall computing architecture of GCTCS is based on a hybrid computing framework, which fully considers and simulates network delay. It provides interfaces for urban TSC and traffic flow prediction algorithms.
The functions of each layer
-
The cloud computing layer is located at the top layer of the architecture. It is responsible for interacting with each fog computing node in the fog layer, collecting information at the fog node, and sending control instructions from the cloud computing layer.
The fog computing layer is located between cloud computing and edge computing layers and consists of various powered servers, routers, and controllers that can bear heavy processing[39]. The primary function is to compute and output the control signal instructions.
The edge computing nodes are located at the bottom layer, mainly processing surveillance videos and extracting status information at the current traffic intersection.
The module of traffic simulation environment
-
We designed the module of urban traffic simulation environment based on the urban traffic simulation platform described above, and it flexibly establishes the traffic flow forecasting interface for multiple intersections[40]. The module can be configured by dynamic traffic flow based on the current simulation environment, making the environment more realistic.
This module employs the traffic flow forecasting method's external interface to dynamically construct traffic flow at each intersection, allowing the traffic simulation system to assimilate the current condition and provide an algorithm interface for TSC. The simulation environment FLOW framework[18] is to optimize the urban traffic simulation environment benefiting from the forecasting capabilities based on data sets and time series models.
The traffic environments in different cities differ, and it is necessary to establish a unified method to obtain traffic circulating situations to construct the urban traffic environment closer to the real world (as shown in Fig. 5). The methodology (1) uses edge computing capabilities to convert the traffic flow captured in the urban traffic monitoring videos into text content; (2) applies a traffic flow prediction algorithm to predict relatively accurate traffic flow; and (3) dynamically interacts with the simulation environment's traffic flow configuration interface. The urban traffic environment is not built in isolation. It interacts with the simulation environment. The process is as follows:
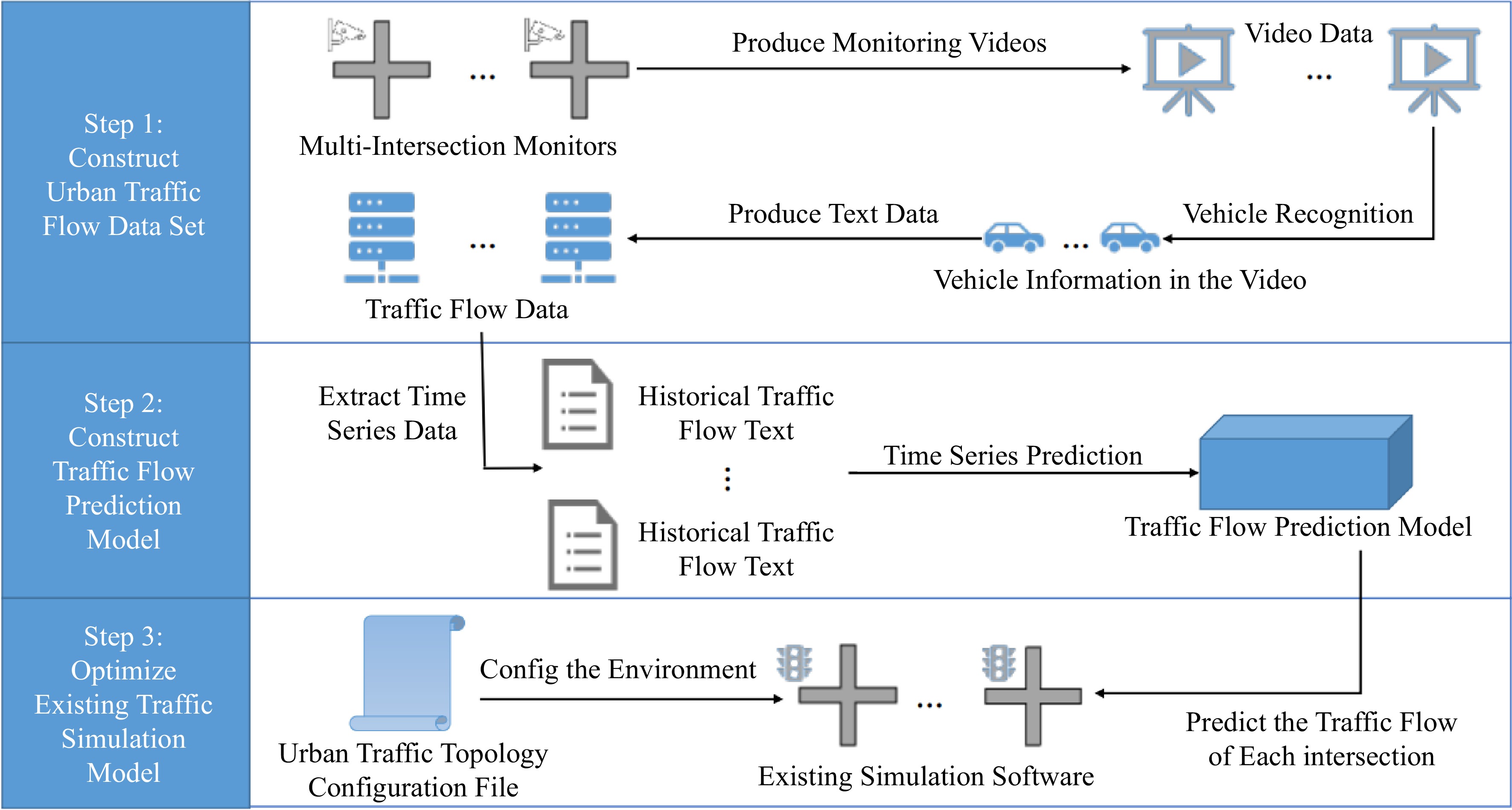
Figure 5.
The processes of construction of the urban traffic real environment.
(1) Establish a data set of urban traffic flow;
(2) Design a forecasting model for traffic flow;
(3) Develop an interactive interface with the simulation environment.
The simulation environment interacts with the traffic flow anticipated by the traffic flow prediction model, allowing the simulation environment to configure real-time traffic flow.
General-MARL
-
In this section, we design a TSC method, named General-MARL, based on the GCTCS.
The design of the General-MARL algorithm is according to different layers of the GCTCS architecture. Thus, the General-MARL is composed of three sub-algorithms: the algorithm at the edge computing layer (Edge-General-control), the algorithm at the fog computing layer (Fog-General-control), and the algorithm at the cloud computing layer (Cloud-General-control). Additionally, the GCTCS with a layer-to-layer connection, which has a clear structure and lowers complexity compared to point-to-point connections, making feasible for the General-MARL with the increasing computation ability for edge and fog devices.
The Cloud-General-control produces the global control signal for each fog node's parameter updating based on the joint state (all traffic states from each node) and playback mechanism (historical interactions from fog nodes). The Fog-General-control generates a TSC signal according to the traffic state abstraction from Edge-General-control, the intelligent communication between agents allows an agent to share the learned strategies and the parameters from the cloud layer. Deep neural networks[41] are the basic component in General-MARL for generating control actions, communication information, and so on. The structure of the algorithm architecture is illustrated in Fig. 6.
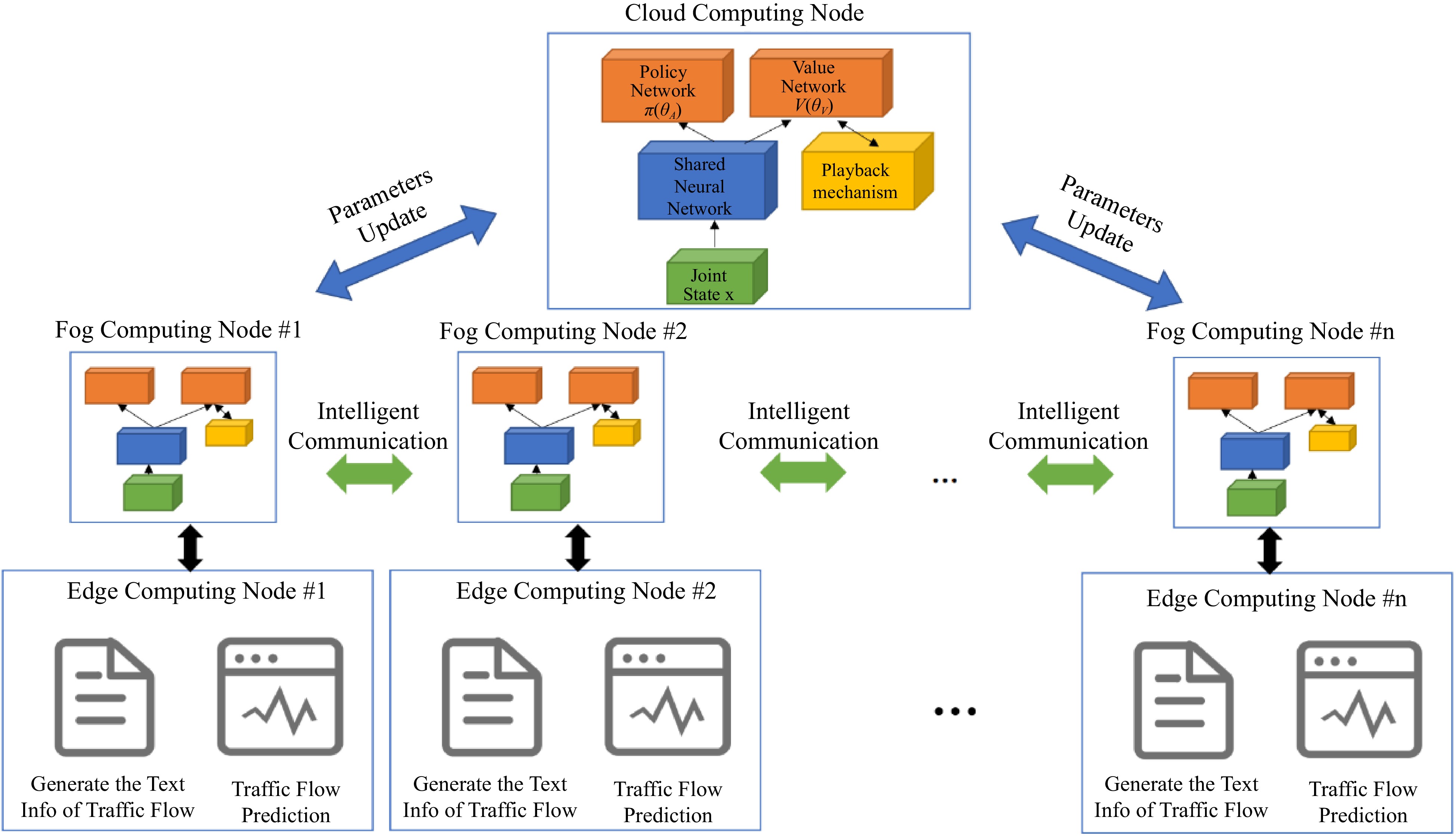
Figure 6.
The General-MARL is composed of three sub-algorithms based on different layers of the GCTCS architecture.
Edge-General-control
-
The Edge-General-control algorithm processes the traffic surveillance video based on the target detection algorithm YOLO[38], detecting the vehicles' location at the intersection.
As shown in Fig. 7, we apply an open-source vehicle image dataset, i.e., BIT-Vehicle[42], to fine-tune the YOLO algorithm for vehicle detection precisely. The center of each intersection is the center point (0,0). We get the vehicle position from the YOLO-based model and add two fully-connection (FC) layers for fine-tuning. Then, we obtain the direction information according to the vehicle's location and center position. Hence, traffic state text is abstracted from the traffic surveillance video, including the vehicle-id, type, direction, and timestamp for passing vehicles.
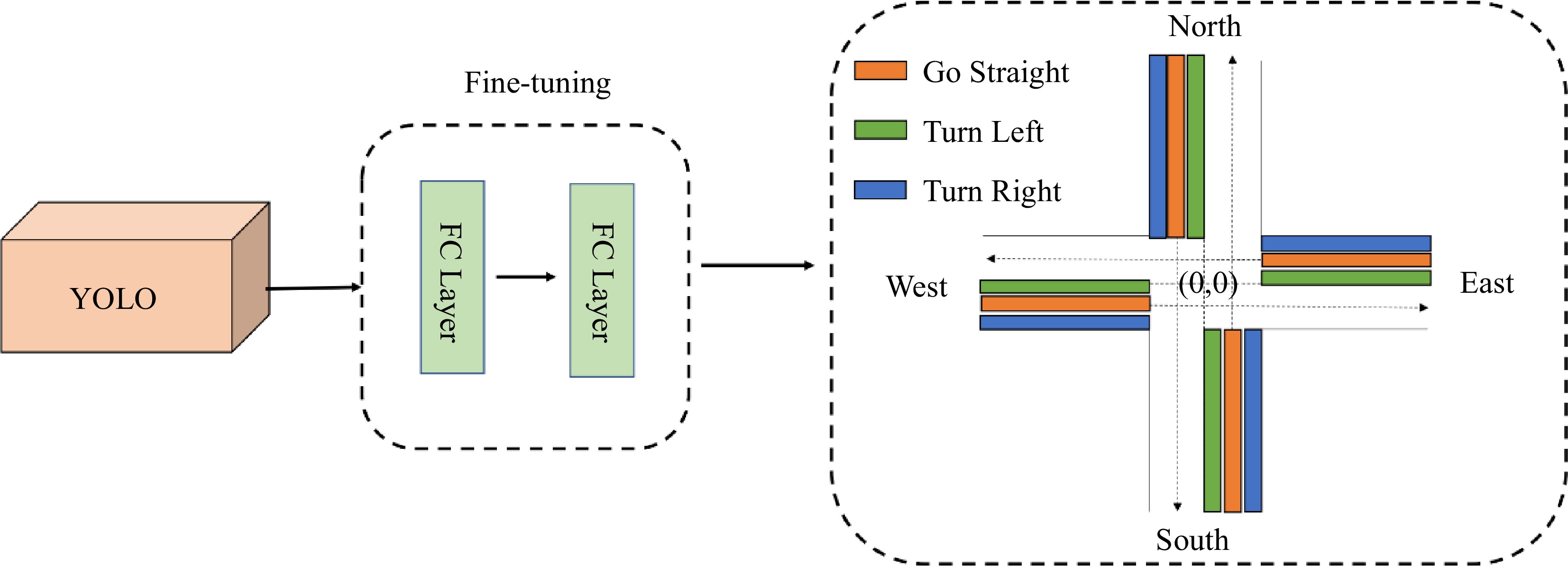
Figure 7.
The process of abstracting traffic information from the video to generate the text info from traffic flow. Detection of vehicles in the three regions stands for different directions of passing vehicles
Finally, we introduce the traffic flow prediction algorithm GCN-GAN[40], which can predict the traffic flow and synchronizes with the simulation environment in real-time (Algorithm 1).
Table 1. Edge-General-control algorithm.
1: Input the video information of the traffic situation. 2: Capture one frame from the video: G 3: Use and fine-tune the YOLO to recognize all the vehicle's position (x,y) and type in G. 4: for vehicle in G do 5: Obtain the direction of vehicles by judging the (x,y) from the regions according the three regions predefined. 6: Record traffic state text information (vehicle -id, types, direction, and the timestamp) into traffic state text T. 7: end for 8: Use GCN-GAN for traffic flow prediction to T. 9: Connect traffic flow prediction capability to the urban simulation environment. Fog-General-control
-
The Fog-General-control algorithm includes the Nash-MARL module and the communication module to generate control strategies for urban traffic signals.
Nash-MARL Module: The Nash-MARL Module is to obtain Nash equilibrium for TSC without prior knowledge dynamically[43]. It defines that
$ X $ $ U $ $ A $ $ a\in A $ $ {u}^{a}\in U $ $ R $ $ {Agent}^{i} $ $ {\pi }_{i} $ $ {R}_{i} $ Herein, the Bellman equation with Nash Equilibrium: firstly, fix other agents' policies
$ {\pi }_{-i}^{*} $ $ {Agent}^{-i}:{R}_{i}\left(x;{\pi }_{i};{\pi }_{-i}^{*}\right) $ $ R=\underset{u\in {U}_{i}}{\mathrm{max}}\left\{{r}_{i}\left(x,u,{\pi }_{-i}^{*}\left(x\right)\right)+{\gamma }_{i}\underset{{x'}\sim p\left(\cdot |x,u\right)}{\mathrm{E}}\left[{R}_{i}\left({x'};{\pi }_{i,1}^{*};{\pi }_{-i,1}^{*}\right)\right]\right\} $ (2) Where
$ {\pi }_{i}^{*} $ $ {Agent}^{i} $ $ {Agent}^{-i} $ $ {\pi }_{i}^{*} $ $ \gamma \in [0, 1] $ $ {Agent}^{i} $ In the design of the Nash-MARL Module, the computation of the critic function (advantage) in deep reinforcement learning might have positive (good) and negative (bad) reward results, making the learning process efficiently. Thus, the Nash-MARL module defines the
$ Q $ $ {Agent}^{-i} $ $ {\left({\hat{Q}}_{i}^{\theta }\left(x;u\right)\right)}_{i\in N} $ $ {Agent}^{-i} $ $ {\left({\hat{V}}_{i}^{\theta }\left(x;u\right)\right)}_{i\in N} $ $ u $ $ x $ $ {\hat{A}}^{\theta }\left(x;u\right)={\hat{Q}}^{\theta }\left(x;u\right)-{\hat{V}}^{\theta }\left(x;u\right) $ (3) It employs the actor-critic model[44] as a framework. In the actor-critic model, the actor is a policy function and the critic is a value function. The parameter set
$ \theta $ $ \theta =\left({\theta }_{V},{\theta }_{A}\right) $ $ {\theta }_{V} $ $ {\hat{V}}^{{\theta }_{V}} $ $ {\theta }_{A} $ $ {\hat{\pi }}^{{\theta }_{A}} $ $ {x}_{m}^{\text{'}} $ $ {x}_{m} $ $ {L}_{m}\left(\theta \right) $ $ {L}_{m}\left(\theta \right)=\frac{1}{M}\sum\nolimits _{m=1}^{M}\left|\left|{\hat{V}}^{\theta }\left({x}_{m}\right)+{\hat{A}}^{\theta }\left({x}_{m};{u}_{m}\right)-r\left({x}_{m};{u}_{m}\right)-{\gamma }_{i}{\hat{V}}^{\theta }\left({x'_{m}}\right)\right|\right|$ (4) The module defines
$ {y}_{m}=\hat{L}\left(y,{\theta }_{V},{\theta }_{A}\right) $ $ {y}_{m}={\left|\left|{\hat{V}}^{{\theta }_{V}}\left({x}_{m}\right)+{\hat{A}}^{{\theta }_{A}}\left({x}_{m};{u}_{m}\right)-r\left({x}_{m};{u}_{m}\right)-{\gamma }_{i}{\hat{V}}^{{\theta }_{V}}\left({x'_{m}}\right)\right|\right|}^{2} $ (5) Inspired by the deep Q-networks[7], the module also introduce a memory buffer (replay buffer) to store triples
$ {y}_{t}=\left({x}_{t-1},u,{x}_{t}\right) $ $ {x}_{t-1} $ $ u $ $ {x}_{t} $ $ {y}_{t} $ Additionally, the idea of parallel space-time is incorporated to enable the simultaneous execution in various environments. To achieve a stable learning process, multiple explorations in multiple environments would explore different policies and accelerate the learning speed. The overall algorithm structure is shown in Fig. 6. Further, the Nash-MARL algorithm process is detailed in Algorithm 2.
Table 2. Nash-MARL Module.
1: Init Episode $ B > 0 $, $ b=1 $; Minibatch Size $ \hat{M} > 0 $, Game Step N 2: Init Replay Buffer $ D $, $ {\theta }_{V} $ and $ {\theta }_{A} $ 3: repeat 4: Reset, go to the $ {x}_{0} $ 5: repeat 6: Select $ u\leftarrow {\pi }^{{\theta }_{A}}\left(x\right) $ or select $ u $ randomly (e.g., ϵ-greedy) 7: Observe $ {y}_{t}=\left({x}_{t-1},u,{x}_{t}\right) $ 8: Store $ {y}_{t} $ to Reply Buffer $ D $ 9: Sampling from Replay Buffer: $ Y={\left\{{y}_{i}\right\}}_{i=1}^{\hat{M}} $ 10: Optimize $ \frac{1}{M+1}{\sum }_{y\in Y\cup \left\{{y}_{t}\right\}}\hat{L}\left(y,{\theta }_{V},{\theta }_{A}\right) $ fix $ {\theta }_{A} $ update $ {\theta }_{V} $ 11: Optimize $ \frac{1}{M+1}{\sum }_{y\in Y\cup \left\{{y}_{t}\right\}}\hat{L}\left(y,{\theta }_{V},{\theta }_{A}\right) $ fix $ {\theta }_{V} $ update $ {\theta }_{A} $ 12: Until $ t > N $ 13: Until $ b > B $ 14: return $ {\theta }_{V} $ and $ {\theta }_{A} $ Communication Module: The communication module between agents allows an agent to share the learned strategies with others based on the attention mechanism[45].
The calculation steps in the communication module[14] at time
$ t $ $ t $ $ {X}_{t}=\left({x}_{t}^{1},\cdots ,{x}_{t}^{N}\right) $ $ {C}_{t}=\left({c}_{t}^{1},\cdots ,{c}_{t}^{N}\right) $ $ \left({Agent}_{1},\cdots ,{Agent}_{N}\right) $ $ {x}_{t} $ $ {c}_{t} $ $ \left({a}_{t+1},{c}_{t+1}\right) $ $ t+1 $ 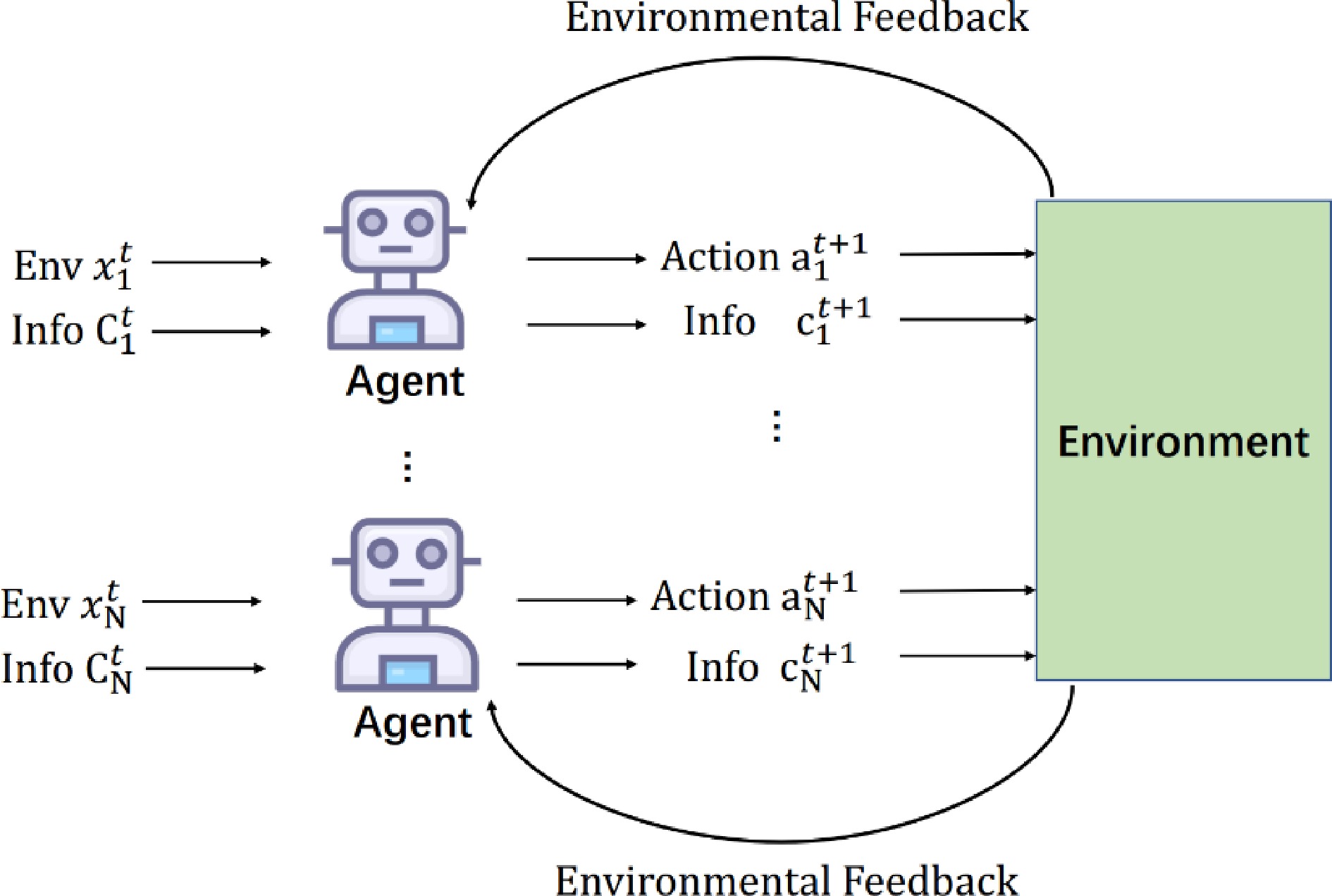
Figure 8.
The communication process between agents in the communication module.
In the communication module (as shown in Algorithm 3), the parameter set of
$ {Agent}^{i} $ $ {\theta }^{i} $ $ {\theta }^{i} $ $ {\theta }_{Sender}^{i} $ $ {\theta }_{Receiver}^{i} $ Table 3. The communication module.
1: Initialize the communication matrix of all agents $ {C}_{0} $ 2: Initialize the parameters of agent $ {\theta }_{Sender}^{i} $ and $ {\theta }_{Receiver}^{i} $ 3: repeat 4: Receiver of $ {Agent}^{i} $: use attention mechanism to generate communication matric $ {\hat{C}}_{t} $ 5: Sender of $ {Agent}^{i} $: chooses an action $ {a}_{t+1}^{i} $ from policy selection network, or randomly chooses an action (e.g., ϵ-greedy exploration) 6: Sender of $ {Agent}^{i} $: generate its own information through the receiver's communication matrix $ {\hat{C}}_{t}:{c}_{t+1}^{i} $ 7: Collect all the joint actions of Agent and execute the actions $ {a}_{t+1}^{1},\cdots ,{a}_{t+1}^{N} $, get the reward from the environment $ {R}_{t+1} $ and next state $ {X}_{t+1} $ 8: until End of Round Episode 9: return $ {\theta }_{Sender}^{i} $ and $ {\theta }_{Receiver}^{i} $ for each agent The Fog-General-control algorithm is illustrated as below (Algorithm 4):
Table 4. Fog-General-control.
1: Apply the communication module: 2: Initialize the communication matric $ {C}_{0} $ of all fog computing node Agents 3: Initialize the parameters $ {\theta }_{Sender}^{i} $ and $ {\theta }_{Receiver}^{i} $ of the fog computing node Agents 4: Receive the global parameter sets $ {\theta }_{V} $ and $ {\theta }_{A} $ distributed by the cloud computing node and initialize the parameter sets $ {\theta }_{V}^{i} $ and $ {\theta }_{A}^{i} $ 5: Initialize the Episode $ B > 0 $, $ b=1 $; the minimum batch size Minibatch Size $ \stackrel{-}{M} > 0 $, the number of game steps $ N $ 6: Apply the Nash-MARL Module: 7: Initialize the memory record Replay Buffer $ D $ 8: repeat 9: Reset the environment and enter the initial state $ {x}_{0} $ 10: repeat 11: Choose joint action $ u\leftarrow {\pi }^{{\theta }_{A}}\left(x\right) $ or randomly choose joint action $ u $ (e.g., ϵ-greedy exploration) 12: Observe the state-action-state triplet $ {y}_{t}=\left({x}_{t-1},u,{x}_{t}\right) $ 13: Store triples in the Replay Buffer $ D $ 14: Extract data $ Y={\left\{{y}_{i}\right\}}_{i=1}^{M} $ from the Replay Buffer 15: $ {Agent}^{i} $ receiver uses Attention mechanism to generate communication matrix $ {\hat{C}}_{t} $ 16: The strategy choice network of the Agent $ {t}^{i} $ sender chooses an action $ {a}_{t+1}^{i} $, or randomly chooses action a (e.g., ϵ-greedy exploration) 17: The $ {Agent}^{i} $ sender generates its own information $ {c}_{t+1}^{i} $ through the communication matrix $ {\hat{C}}_{t} $ at the receiving end 18: Collect the joint actions of all Agents, execute an action $ {a}_{t+1}^{i},\cdots ,{a}_{t+1}^{N} $, get rewards $ {R}_{t+1} $ and the next state $ {X}_{t+1} $ from the environment 19: Optimization step $ \frac{1}{M+1}{\sum }_{y\in Y\cup \left\{{y}_{t}\right\}}\hat{L}\left(y,{\theta }_{V}^{i},{\theta }_{A}^{i},{\hat{C}}_{t}\right) $, fixes $ {\theta }_{A}^{i} $ updates $ {\theta }_{V}^{i} $ 20: Optimization step $ \frac{1}{M+1}{\sum }_{y\in Y\cup \left\{{y}_{t}\right\}}\hat{L}\left(y,{\theta }_{V}^{i},{\theta }_{A}^{i},{\hat{C}}_{t}\right) $, fixes $ {\theta }_{V}^{i} $ updates $ {\theta }_{A}^{i} $ 21: until $ > N $ 22: until $ b > B $ 23: Return $ {\theta }_{V}^{i} $ and $ {\theta }_{A}^{i} $ Cloud-General-control
-
The Cloud-General-control algorithm deploys the Nash-MARL module, the 'parallel universe' of the Nash-MARL algorithm are fog nodes.
The Cloud-General-control Algorithm 5 is:
Table 5. Cloud-General-control.
1: Apply the Nash-MARL module: 2: Initialize the global parameter sets $ {\theta }_{V} $ and $ {\theta }_{A} $ of the cloud computing center and the global counter $ T $ 3: repeat 4: Distributer global parameters to fog computing nodes $ {\theta }_{V}^{i}={\theta }_{V} $, $ {\theta }_{A}^{i}={\theta }_{A} $ 5: repeat 6: Update global parameters $ {\theta }_{V}={\theta }_{V}+d{\theta }_{V}^{i} $, $ {\theta }_{A}={\theta }_{A}+d{\theta }_{A}^{i} $ 7: until all fog computing nodes are traversed and collected 8: $ T\leftarrow T+1 $ 9: until $ T > {T}_{max} $ -
In this section, we apply General-MARL and baseline methods to the integrated and cooperative architecture GCTCS for multi-intersection TSC. The experimental process ignores or considers the situation of network bandwidth and network delay, respectively.
Dataset
-
The dataset from Lanzhou in China consists of two parts: (1) the traffic network; and (2) the traffic flow. The traffic network describes the traffic network, including lanes, roads, intersections, and signal phases. As shown in Fig. 9, there are 27 intersections connecting 45 roads. All the traffic networks are simulated in the simulation environment from our GCTCS. Various and flexible TSC algorithms control each intersection's signal. The distance between two intersections is two to four kilometers (km). The speed limitation is 60 (km/h).
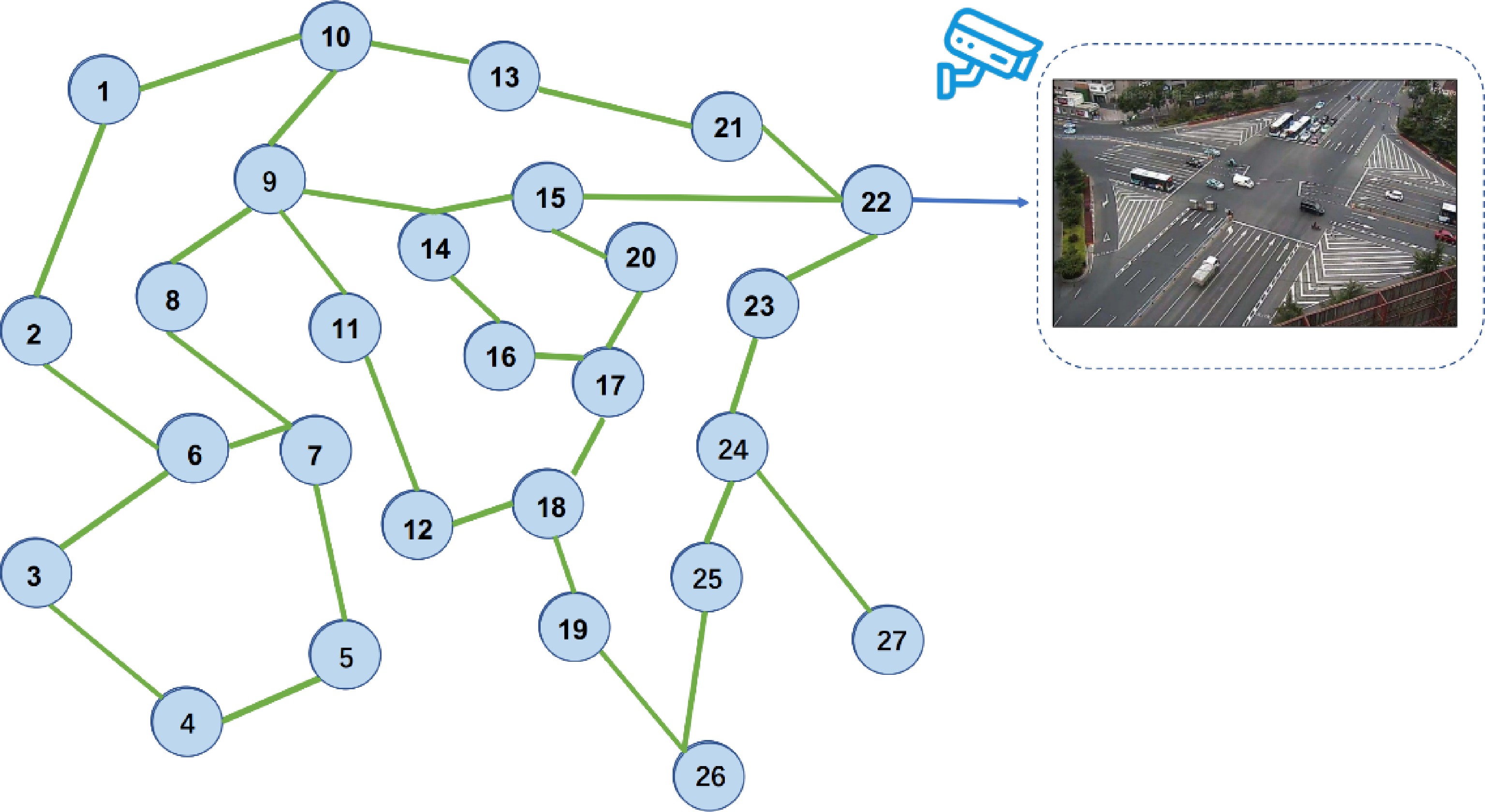
Figure 9.
The illustration of topology map of real traffic intersection.
The initial flow of incoming and outgoing vehicles at each intersection is configured based on the real traffic flow data. The traffic flow dataset contains vehicles travel information, which is described as
$ (t,u) $ $ t $ $ u $ Parameter settings of General-MARL
Cloud computing center
-
We deploy the Cloud-General-control algorithm in a Docker environment[46], logically away from the intersections, and set the communication delay from the cloud center to the fog computing node to
$ x $ $x$ $x$ $ \pi \left(x\right) $ Fog computing node
-
We deploy the Fog-General-control algorithm in the Docker environment and set it to be logically close to the intersection. The delay from the intersection to the fog computing node is set to
$ x $ $x$ $ x $ $ \pi \left(x\right) $ Edge computing node
-
We deploy the Edge-General-Control algorithm in the Docker environment at one intersection. The network delay from the edge computing nodes to fog computing and vehicles are both set to
$ x $ $x$ $x$ Initial traffic light period setting
-
The traffic control period is set to 60 s initially. The intervals of the green, red and yellow lights are set as
${g}_{t}$ $ {r}_{t} $ $ {y}_{t} $ Vehicle simulation
-
According to the actual traffic flow forecasting algorithm, the traffic flow is predicted every 15 min, and the vehicle simulation is conducted at each intersection.
Evaluation mechanism
-
In the simulation environment, the passing time of all vehicles at each intersection in an Episode is recorded as
$ {T}_{e}={\sum }_{i=1}^{I}{\sum }_{m=1}^{M}{t}_{m} $ $ e\in E $ $ M $ $ I $ $E$ $ I $ Methods for comparison
-
Fixed-Time[25]: a policy gives a fixed cycle length with predefined green time among all phases. The intervals of the green, red and yellow signals are fixed as green and red are 27 s, and the yellow is 6 s, which are the same as the initial intervals for other methods for a fair comparison.
Q-learning[32]: a model-free reinforcement learning algorithm to learn the value of an action in a particular traffic state based on Q-learning[48], which leverages the advantage deep neural network for addressing TSC problem. The algorithm can be deployed on the Fog or Edge node with the same parameters as shown in Table 1.
Table 1. List of parameters in this paper.
Module Parameters Description Cloud Computing Center $ x=0|x=10 $
20, 60, 60, 20
0.001The delay from the cloud to the fog node
The hidden layers in the network
The learning rateFog Computing Node $ x=0|x=1 $
20, 60, 60, 20
0.001The delay from intersection to the fog node
The hidden layers in the network
The learning rateEdge Computing Node $ x=0|x=1 $ The delay from edge nodes to fog node Experiment Settings $ {g}_{t}={r}_{t}=27,{y}_{t}=6 $
15
E = 1,000
I = 27
l = 0.001
γ = 0.982The initial intervals of the green, red and yellow
The traffic flow prediction period
The number of Episodes
The number of intersections
The learning rate
The discount rateNash-Q[49]: a model integrates Q-learning[48] and Nash Equilibrium[50] for making agents learn a better cooperative strategy, which can be deployed on the Fog node.
Nash-DQN[51]: a Deep-Q-learning methodology for model-free learning of Nash Equilibrium for general-sum stochastic games.
MAAC[14]: a multi-agent auto communication (MAAC) algorithm is an adaptive global TSC method based on MARL. MAAC combines multi-agent auto communication protocol with MARL, allowing an agent to communicate the learned strategies with others for achieving global optimization in traffic signal control. The intervals of the green, red and yellow signals are fixed as the experiment settings.
Experimental process
-
Each experiment consists of two parts: the first part ignores the network delay and compares results with other TSC algorithms; in the other part, network delay is considered.
Ignoring network delay
-
The delays of edge computing, fog computing, and cloud computing nodes in General-MARL are all set to 0 without considering network latency. In the urban simulation environment, we input actual traffic data before configuring various TSC algorithm models via the algorithm interface. Baseline methods and the General-MARL algorithm are run in the simulation environment. The traffic flow at each intersection is updated every 15 min. We record the waiting time of vehicles at each traffic intersection every minute (considered as an environmental feedback reward) and conduct 1000 Episode (round) training.
As shown in Fig. 10, the training convergence effect of the General-MARL algorithm is as good as the Nash-DQN algorithm but does not perform the best.
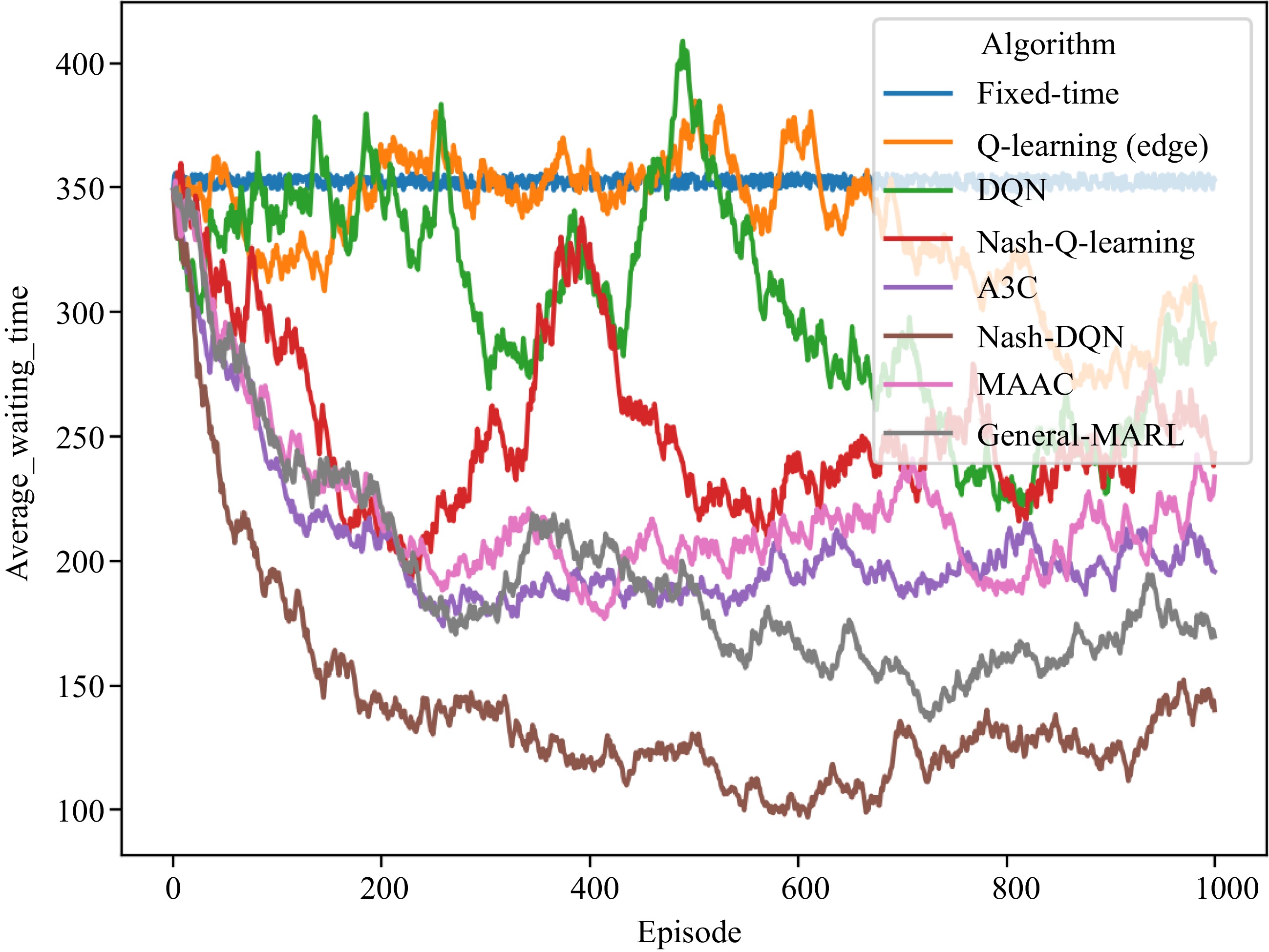
Figure 10.
Multi-intersection traffic signal control training process (without network delay).
Considering network delay
-
In the case of considering network delay, the delays of the edge computing, fog computing, and cloud computing nodes in General-MARL are all set parameters according to the previous section. Then we configure the fixed duration as the traffic signal time series as the previous setting. Q-learning (edge) deploys the Q-learning algorithm on the fog computing node to control the traffic lights, and the delay from the controlling agent to the intersection is 1 s. There are 27 docker containers deployed at 27 traffic intersections with Q-learning capabilities to generate traffic flow controlling signals, respectively.
Q-learning (center) and DQN only use the cloud computing center to collect the information at each intersection. They are applied for overall control and generation of control commands for each intersection. The traffic flow prediction algorithm then updates the traffic flow at each intersection every 15 min (GCN-GAN). GCTCS records the waiting time of vehicles at each intersection every minute (as an environmental feedback reward) and conducts the training with 1000 Episodes.
As shown in Fig. 11, the convergence speed of the General-MARL is faster than Nash-DQN, and the training results outperform other baseline algorithms.
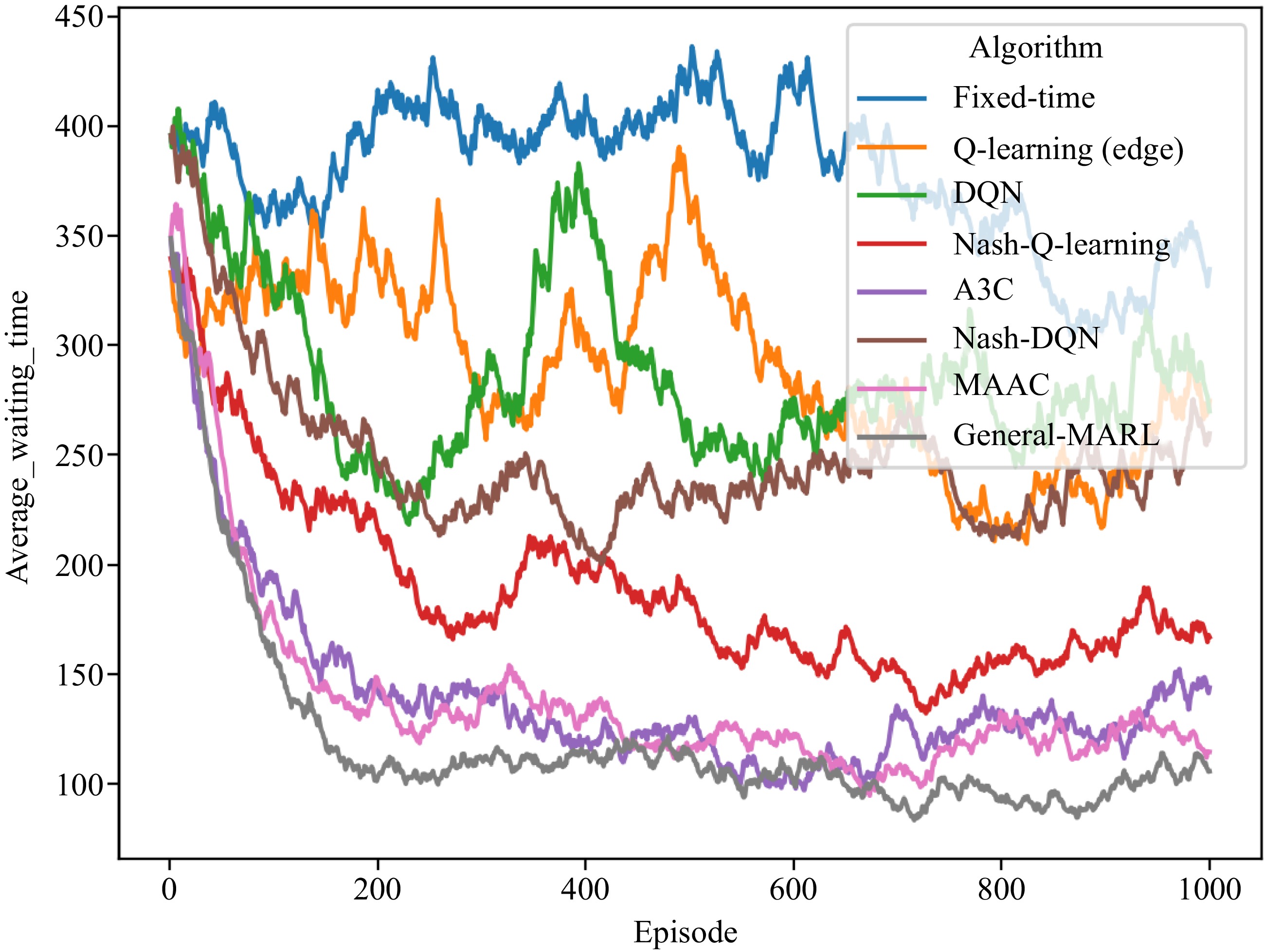
Figure 11.
Multi-intersection traffic signal control training process (with network delay).
Experimental results
-
The results of the experiment are also split into two parts: the first part ignores network delay, and the second part considers network delay.
Ignoring network delay
-
After training in the simulation experiment in the previous section, 500 episode tests were performed to generate the experimental results, as shown in Table 2.
Table 2. Results of General-MARL and other algorithms (ignoring network delay).
Method Average speed (km/h) Average waiting time (s) Fixed-time 10.17 166.70 Q learning 18.43 135.62 DQN 20.10 112.24 A3C 24.12 90.73 Nash-Q 29.70 70.14 Nash-DQN 33.81 61.21 MAAC 27.39 80.21 General-MARL 31.22 62.87 The experimental results show that, regarding the average speed and average waiting time of vehicles at 27 intersections, the General-MARL algorithm leads a similar performance as the Nash-DQN algorithm. The performance of General-MARL is not outstanding when network delay is ignored, but the overall performance of General-MARL is better than other baseline algorithms.
Considering network delay
-
We conduct 500 episodes in the tests after training in the simulation and collected the experimental results, as shown in Table 3. Regarding the average waiting time at intersections, the overall performance of General-MARL is the best, surpassing all the other algorithms, and it shows an average decrease of 18.3% waiting time compared to the baseline algorithms. As for the average speed of vehicles at intersections, the General-MARL algorithm increases the average speed by 10.2% when network delay is considered. As shown in Table 4, the General-MARL algorithm fully exceeds the baseline algorithms and other algorithms in terms of the accumulated waiting time of vehicles, network delay time, and delay rate indicators. The delay rate is reduced by 7.4%. Furthermore, the General- MARL algorithm optimizes each intersection to a certain extent, as shown in Table 5.
Table 3. Results of the average speed and waiting time in each episode (consider network delay).
Method Average speed (km/h) Average waiting time (s) Fixed-time 10.15 166.71 Q learning(center) 21.69 182.75 Q learning(edge) 23.47 155.64 DQN 24.94 132.70 A3C 26.12 108.65 Nash-Q 28.32 105.55 Nash-DQN 30.86 106.37 MAAC 27.61 116.81 General-MARL 30.78 92.48 Table 4. Results of accumulated time and network delay in each episode (consider network delay).
Method Accumulated time (s) Network delay (s) Delay rate Fixed-time 38827.5 0.0 0.0% Q learning(center) 45448.0 10809.7 23.8% Q learning(edge) 35789.3 6522.9 18.2% DQN 33789.9 8997.2 26.6% A3C 31340.4 7792.1 24.9% Nash-Q 30940.5 7536.9 24.4% Nash-DQN 31994.6 7937.7 24.8% MAAC 28940.7 6552.1 22.6% General-MARL 26912.7 3264.5 12.2% Table 5. Results of average waiting time at each intersection in each episode (considering network delay).
ID Fixed-
timeQ-edge DQN A3C Nash-Q Nash-
DQNMAAC General 1 175.27 161.96 136.93 110.89 109.34 111.21 124.69 96.81 2 188.35 172.68 145.58 116.43 115.88 119.02 130.73 105.46 3 155.28 145.58 123.71 102.43 99.35 99.27 120.99 83.59 4 197.72 180.36 151.78 120.39 120.57 124.61 133.34 111.66 5 155.23 145.54 123.68 102.41 99.32 99.24 116.97 83.56 6 168.97 156.8 132.76 108.22 106.19 107.45 122.26 92.64 7 157.68 147.55 125.30 103.44 100.55 100.7 107.91 85.18 8 161.32 150.53 127.70 104.98 102.37 102.88 119.31 87.58 9 185.23 170.13 143.52 115.11 114.32 109.88 128.53 103.40 10 176.47 162.95 137.72 111.40 109.94 111.92 115.15 97.60 11 161.21 150.44 127.63 104.94 102.31 102.81 119.28 87.51 12 125.96 121.55 104.32 90.01 104.30 81.77 105.69 64.20 13 131.62 126.19 108.06 92.41 87.52 85.15 117.87 67.94 14 169.15 156.95 132.88 108.30 106.28 107.55 122.33 92.76 15 175.52 180.84 152.16 120.64 109.47 124.96 40.06 112.04 16 132.47 126.89 108.62 92.77 87.94 85.65 108.20 68.50 17 164.12 152.83 129.56 87.56 103.77 104.55 113.46 89.44 18 166.87 155.08 131.38 107.33 105.14 106.19 121.45 91.26 19 150.39 141.57 120.48 100.36 96.90 96.35 115.11 80.36 20 177.77 164.01 138.58 111.95 110.59 112.70 125.65 98.46 21 153.63 144.23 122.62 101.73 98.52 98.29 96.35 82.50 22 167.54 155.63 131.82 107.62 105.48 106.59 121.71 91.70 23 177.62 163.89 162.05 157.98 110.52 112.61 139.54 121.93 24 186.84 171.45 144.58 115.79 115.13 118.11 129.15 104.46 25 175.36 162.04 136.99 110.93 109.39 111.26 128.73 96.87 26 175.23 161.93 136.90 110.87 109.32 111.18 124.67 96.78 27 188.35 172.68 145.58 116.43 115.88 119.02 104.64 102.77 Overall analysis
-
The analysis of experimental results reveals that network delay has a significant impact on the actual application effect of the TSC algorithm. Although General-MARL showed good performance even when network delay was ignored, implementation of the method in urban TSC should take into account the influence of network latency for industrial deployment.
With the consideration of network delay, the General-MARL fully surpasses the baseline algorithms on average vehicle speed at intersection, average vehicle waiting time, vehicle cumulative waiting time, network delay time, and the indicators of delay rate. The average speed of vehicles increases by 23.2%, and the network latency decreases by 11.7%, as shown in Fig.12.
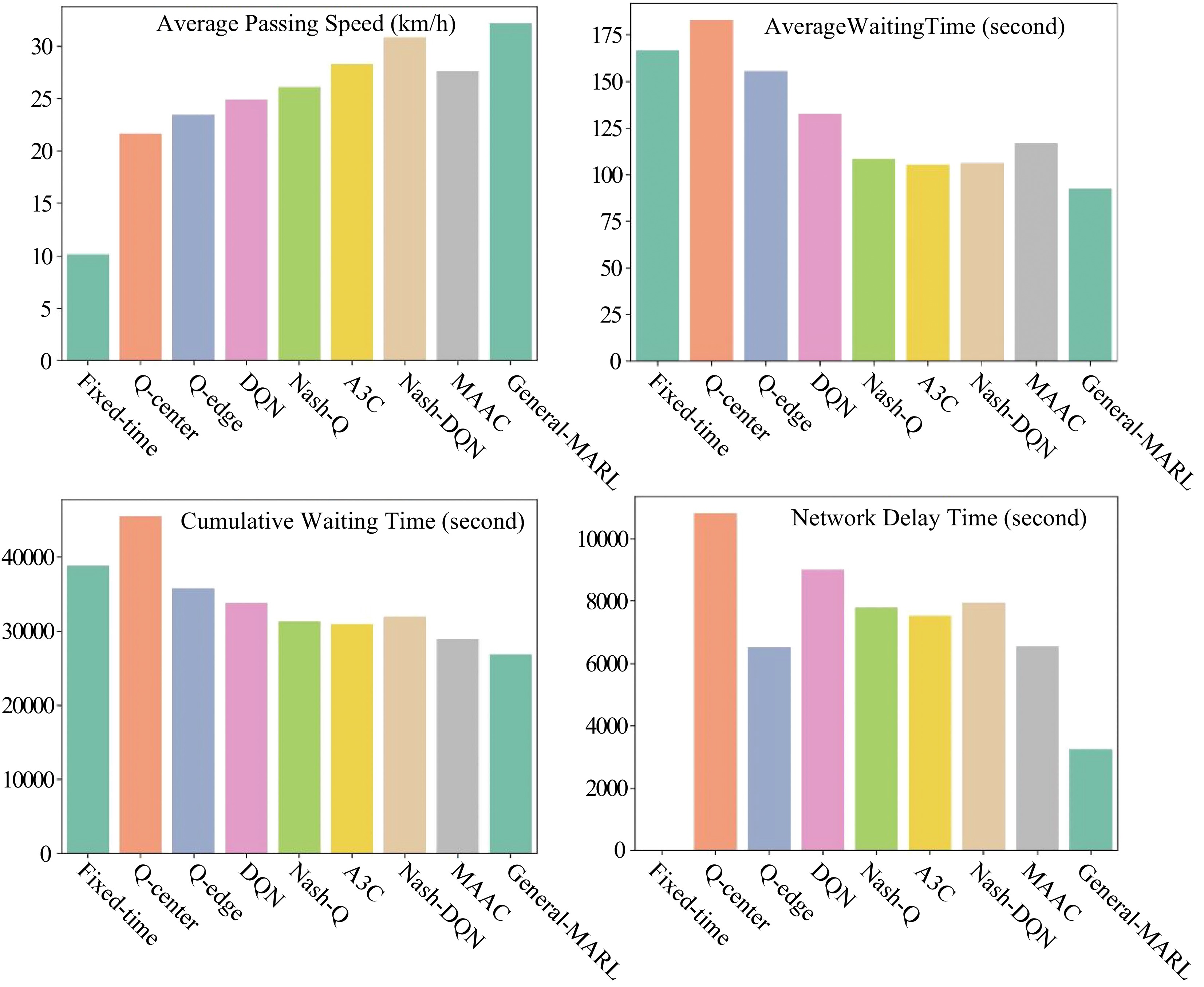
Figure 12.
Comparative results among different algorithms.
-
In this paper, we proposed an integrated and cooperative IoT architecture GCTCS and the General-MARL algorithm for multi-intersection traffic signal control. The results from the proposed framework and algorithm showed that the average speed of vehicles was increased by 23.2%, and the network latency was reduced by 11.7%, when compared with baseline algorithms. Our results proved that the application of MARL in urban traffic signal control needs to consider multiple factors, including the simulation environment, algorithm process, deployment architecture, and network delay. The results also validated the best performance of the proposed General-MARL. Therefore, GCTCS and General-MARL showed great potential in practical applications and theoretical contributions for multi-intersection traffic signal control with large-scale deployment in real road networks.
In traffic signal control, not only the vehicles' but also the pedestrians' behaviours[52], such as crossing times and waiting times are affected. In future studies, pedestrians will be included to cover all the road users at intersections. We will be able to further validate our proposed methodology based on real-life case studies because we have been invited by one city from China to deploy our GCTCS and algorithm in a test area.
This work is supported by the National Natural Science Foundation of China (Grant Nos. 61673150, 11622538). We acknowledge the Science Strength Promotion Programme of UESTC, Chengdu, China.
-
The authors declare that they have no conflict of interest. Bo Du and Jun Shen are the Editorial Board members of Digital Transportation and Safety. They were blinded from reviewing or making decisions on the manuscript. The article was subject to the journal's standard procedures, with peer-review handled independently of these Editorial Board members and their research groups.
- Copyright: © 2023 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Wu Q, Wu J, Kang B, Du B, Shen J, et al. 2023. An integrated and cooperative architecture for multi-intersection traffic signal control. Digital Transportation and Safety 2(2):150−163 doi: 10.48130/DTS-2023-0012 

An integrated and cooperative architecture for multi-intersection traffic signal control
- Received: 15 April 2023
- Accepted: 16 June 2023
- Published online: 29 June 2023
Abstract: Traffic signal control (TSC) systems are one essential component in intelligent transport systems. However, relevant studies are usually independent of the urban traffic simulation environment, collaborative TSC algorithms and traffic signal communication. In this paper, we propose (1) an integrated and cooperative Internet-of-Things architecture, namely General City Traffic Computing System (GCTCS), which simultaneously leverages an urban traffic simulation environment, TSC algorithms, and traffic signal communication; and (2) a general multi-agent reinforcement learning algorithm, namely General-MARL, considering cooperation and communication between traffic lights for multi-intersection TSC. In experiments, we demonstrate that the integrated and cooperative architecture of GCTCS is much closer to the real-life traffic environment. The General-MARL increases the average movement speed of vehicles in traffic by 23.2% while decreases the network latency by 11.7%.
-
Key words:
- Intelligent transport system /
- Traffic signal control /
- Traffic /
- Deep learning