








-
Megathyrsus maximus (Guinea grass), formerly known as Panicum maximum, is a subtropical grass native to South Africa[1] and is considered one of the best fodder species in tropical countries. This can produce good quality higher yields when managed properly[2] due to its higher performance as a C4 plant[3]. This plant is more suitable for being used as a pasture, cut-and-carry, and producing hay and silage. Guinea grass can be managed as a pasture for a longer period if it is grazed below 35 cm in height[4]. Guinea grass should be harvested when the plant reaches a 60 to 90 cm height to produce hay and silage and can be harvested up to 150 cm height[5]. To produce the highest quality silage, it is recommended to harvest Guinea grass before flowering[6].
Megathyrsus maximus was introduced to Sri Lanka as fodder for horses and cattle and was widely farmed and then naturalized within the Sri Lankan ecosystem in a short period of time[7]. Although no definite date for the arrival of Guinea grass to Sri Lanka has been established, several scholars assume that it was introduced in the early 19th century, prior to 1824[8].
In the 19th century Guinea grass was regarded as a weed and is now designated as an alien invasive species in Sri Lanka[9,10]. This plant is also found as an invasive weed in many coconut-growing lands[11], interfering with the routine practices of the plantation and thereby increasing the cost of production. Most manual and mechanical weed management methods are ineffective against this rhizomatous grass weed. Controlling this weed has become extremely difficult and laborious with the prohibition of systemic herbicides.
Even though this plant is recognized as a problematic weed in Sri Lankan agriculture ecosystems, in many countries, this plant is considered a raw material to produce organic fertilizer[12,13] and green manure[14−16] other than recognized as a valuable forage.
Guinea grass is one of Sierra Leone's most prominent grasses, having taken over most of the arable land and been used as green manure while preparing seedbeds for maize and tuber crops since it provides a low-cost source of nutrients for plant growth and production. Guinea grass has been indicated as viable green manure for maize production, and 15 t ha−1 is recommended as the best application rate for maize cultivation. Also, using Guinea grass as green manure at a rate of 15 t ha−1 has significantly improved vegetative growth[16]. Applying Guinea grass as organic manure has increased plant height, leaf area, fresh and dry weights of shoots, and roots of maize. Another experiment revealed that compost made from Guinea grass could be used as an effective soil supplement for improving soil fertility and increasing maize grain yield. The author has further stated that producing compost with this grass in tropical countries where this is abundantly available would reduce the cost of production, increasing the farmer's income[17].
In most of the agricultural lands in Jamaica, Guinea grass had been used as a mulch to minimize the impact of droughts in areas where rainfall is scarce. After preparing the soil for agriculture, it was recommended to apply dried Guinea grass on the ground like a mat. This approach has enhanced soil moisture retention, and, as a result, seed germination and crop establishment during dry spells have been facilitated, reducing the need for supplementary water supply. Guinea grass should be harvested before flowering in this method since it becomes more liquified during the reproductive stage, making it more difficult to disintegrate as a mulch. Mulching with Guinea grass has also reduced weed development, lowering the expense of weeding and reducing competition with the crop for soil moisture and nutrients[15].
A study conducted on various rates of dried Guinea grass mulch (0, 2, 4, and 8 t ha−1) on the growth and yield performances of cowpeas and eggplants revealed that mulching has improved both dry matter accumulation in cowpeas and marketable yield in eggplants, with the application rate of 4 t ha−1 of dried Guinea grass as a mulch. It has also improved the soil water retention, seedling emergence, weed control, and yield of both cowpeas and eggplants[14]. Furthermore, a recent study has confirmed that the combined application of Guinea grass and poultry manure has increased the growth and yield of sorghum by improving soil properties[18]. It highlighted the importance of the slow decaying process of Guinea grass green manures for retaining the nutrients in the root zone for a longer period.
Senanayake et al. studied Guinea grass's chemical and taxonomical characteristics, including leaf nutrient analysis, carbon isotope analysis, and leaf anatomy covering seven agroecological regions in Sri Lanka in 2018[19]. Other than that, only a few research studies have been carried out to identify the alternative uses of this invasive species in local conditions. Therefore, this study was designed to evaluate the feasibility of using M. maximus as a raw material to produce organic fertilizer for coconut plantations by estimating the nutrient composition when harvested at different growth stages.
-
The present study was carried out for a six month period starting from March 2021 at Rathmalagara Research Station of the Coconut Research Institute of Sri Lanka situated at Madampe (7°32'47.1084'' N, 79°53'18.6432'' E, elevation 33 m from the mean sea level) in Puttalam district (Fig. 1). The area belongs to the low country intermediate zone (IL1)[20], which receives 1,660 mm mean annual rainfall and a 23.8−30.4 °C average temperature range[21]. The soil of the experiment site belongs to the Andigama series, which is classified under the great soil group of Red Yellow Podzolic and characterized by soft or hard laterite, sandy clay loam soil mixed with a significant quantity of ironstone gravel. These soils are shallow to moderately deep and moderately well-drained[22].
Figure 1.
Map of experiment site: Rathmalagara Research Centre of Coconut Research Institute of Sri Lanka.
Experimental design
-
This experiment was laid according to the Randomized Complete Block Design (RCBD) with four replicates in an existing, naturally grown (previously used as a research field for Guinea grass experiments), uniform Guinea grass field under coconut. The area under a coconut square (8 m × 8 m) was selected as a single plot. All the experimental plots were cut at the height of 15 cm from the ground level before initiating the experiment and allowed to regrow in their natural habitat without supplementing any plant nutrients or conducting any weed management strategies. They were then harvested 4, 6, 8, 10, and 12 weeks after initial cutting. Dry matter yield and leaf nutrient content of Guinea grass were measured at different harvesting intervals.
Measurement of dry matter yield
-
The total fresh weight of Guinea grass in each plot was recorded separately. Three random samples were then taken from each plot, and the fresh weight of the collected samples was recorded at the time of harvesting. These samples were oven-dried at 70 °C until they reached a constant weight following standard protocols. The moisture content of each sample was calculated and averaged. The total dry matter content of each plot was calculated using fresh weight, dry weight, and moisture content of collected samples. Finally, the dry matter yield per hectare was calculated. The average dry matter yield harvested from four replicates simultaneously was considered the dry matter yield.
Leaf nutrient analysis
-
Three random leaf samples from each plot were collected in contamination-free polythene bags separately. Leaf samples were cleaned with distilled water and oven-dried at 70 °C until they reached a constant weight and ground with a pre-cleared, contamination-free plant material grinder. The ground homogenized leaf samples were stored in clean plastic bottles until further laboratory analysis.
The total nitrogen (N) content of leaf samples was determined based on Kjeldahl[23] and total leaf phosphorus (P) content was measured colorimetrically with ammonium molybdate following the standard protocol[24]. Total potassium (K), calcium (Ca), and magnesium (Mg) content in leaf samples were determined using Inductively coupled plasma-optical emission spectrometry (iCAP Pro, Thermo Scientific, Germany) followed by microwave digestion with high purity nitric acid and hydrogen peroxide at 200 °C[25]. All the leaf nutrient content were determined on a dry weight basis.
Statistical analysis
-
MINITAB 17 version was used for statistical analyses. Homoscedasticity and normality of all the measured parameters were checked using the normality test, outlier test, and spread of data in different treatments were compared by drawing box plots. Next, the mean, minimum, maximum, standard deviation (SD), and coefficient of variation (CV) of measured parameters were calculated under descriptive statistics. Finally, the mean values of the data were statistically compared using the One-way Analysis of variance (ANOVA) at 5 % significance and Tukey’s pairwise comparison test.
-
Results in Table 1 indicate that dry matter yield and total phosphorous content in leaves have more variation compared to other measured parameters. The highest dry matter yield (1.89 ± 0.45 t ha−1) was recorded when Guinea grass was harvested 12 weeks after regrowth. The highest leaf nutrient contents were recorded when Guinea grass was harvested 4 weeks after initial cutting, and the recorded values for total nitrogen, phosphorous, potassium, calcium, and magnesium content of the leaves as a percentage of their dry weight were 1.49 ± 0.06%, 0.29 ± 0.07%, 3.16 ± 0.43%, 0.57 ± 0.06%, and 0.45 ± 0.02% respectively.
Table 1. Descriptive statistics of dry matter yield and leaf nutrient content
Variable Harvesting interval (weeks after regrowth) Mean Min. Max. SD CV (%) Dry matter yield (t ha−1) 4 0.84 0.51 1.19 0.20 24.31 6 1.01 0.47 1.75 0.39 37.99 8 1.52 0.53 2.96 0.81 53.66 10 1.80 0.46 3.75 0.97 53.80 12 1.89 1.20 2.47 0.45 23.51 Total nitrogen (% dry weight basis) 4 1.49 1.38 1.63 0.06 4.00 6 1.16 0.79 1.35 0.18 15.72 8 1.09 0.71 1.36 0.18 16.88 10 0.99 0.69 1.37 0.17 17.29 12 0.71 0.17 1.08 0.25 34.75 Total phosphorous
(% dry weight basis)4 0.29 0.20 0.39 0.07 24.97 6 0.27 0.15 0.50 0.13 48.38 8 0.25 0.15 0.34 0.07 28.36 10 0.21 0.10 0.40 0.11 49.10 12 0.19 0.05 0.35 0.09 46.33 Total potassium
(% dry weight basis)4 3.16 2.49 4.05 0.43 13.75 6 2.52 1.67 3.02 0.48 19.23 8 2.20 1.59 3.04 0.48 21.67 10 2.12 1.19 3.47 0.74 35.09 12 1.91 1.45 2.34 0.26 13.42 Total calcium
(% dry weight basis)4 0.57 0.50 0.65 0.06 10.10 6 0.56 0.45 0.68 0.08 13.61 8 0.48 0.36 0.62 0.08 17.32 10 0.43 0.23 0.64 0.16 37.78 12 0.43 0.30 0.59 0.09 21.08 Total magnesium
(% dry weight basis)4 0.45 0.43 0.48 0.02 4.21 6 0.39 0.30 0.47 0.06 15.64 8 0.37 0.26 0.44 0.05 14.48 10 0.34 0.19 0.46 0.07 21.36 12 0.32 0.26 0.40 0.05 14.09 Since these are naturally existing fields, the variation is higher compared to cultivated fields resulting in higher CV values. Dry matter yield at different harvesting intervals
-
Figure 2a reveals that the dry matter yield has increased significantly (p < 0.05) with the increase in grass maturity. The lowest dry matter yield (0.84 ± 0.20 t ha−1) was recorded 4 weeks after initial cutting, and it has been increased up to 1.89 ± 0.45 t ha−1 when it reached 12 weeks after initial cutting. The order of ascent for dry matter yield obtained at various harvesting intervals was 12 weeks > 10 weeks > 8 weeks > 6 weeks > 4 weeks after initial cutting.
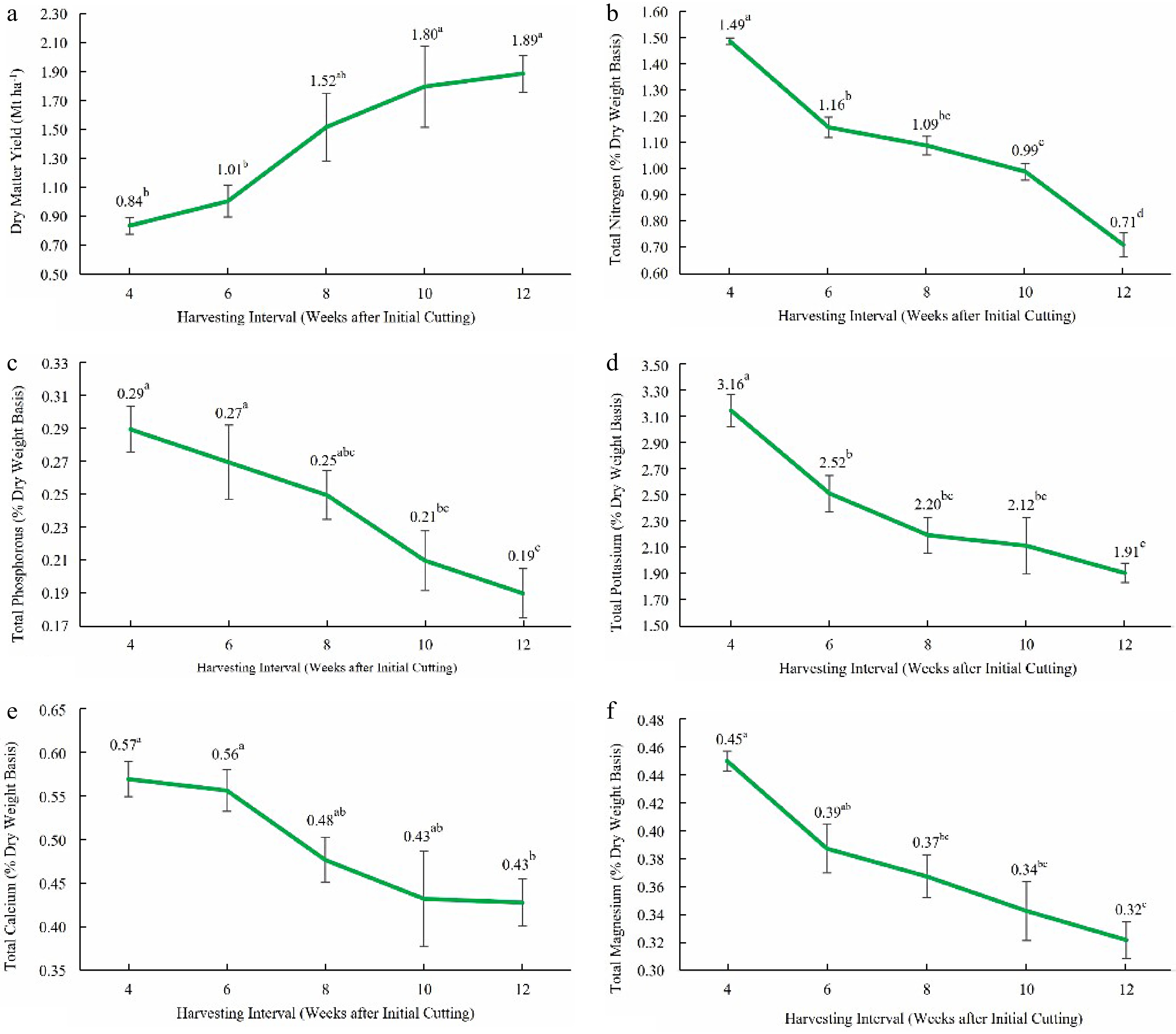
Figure 2.
(a) Dry matter yield, (b) total leaf nitrogen content, (c) total leaf phosphorous content, (d) total leaf potassium content, (e) total leaf calcium content, and (f) total leaf magnesium content at different growth stages (4, 6, 8, 10, and 12 weeks after initial cutting). Means that do not share a letter are significantly different at p < 0.05.
According to previous studies, 576.43 kg ha−1 herbage yield from monocropping of this grass can be received when harvested at six week intervals[26]. Another study has reported that the dry matter yield of Megathyrsus maximus has been increased with the length of the cutting interval and further stated that approximately 12.07 tons of dry matter yield can be obtained per year from one hectare and approximately 14.25 t ha−1 yr−1 and 14.89 t ha−1 yr−1 yield when harvested once in 4 and 5 weeks interval[27].
However, with nitrogen fertilizer application, higher dry matter yield was recorded compared to non-nitrogen applied fields. For example, when nitrogen is applied at a rate of 150 to 200 kg ha−1 of Guinea grass production land, an annual yield of 18 to 21 tons of forage can be obtained from a hectare. A two-year study conducted to assess the forage yield and nutritional value of 24 genotypes of M. maximus in the Brazilian savannah has reported the highest annual dry matter yield as 20.9 t ha−1, including the stems and 14.7 t ha−1 as the highest annual leaf dry matter yield. These experiment plots had been fertilized with 250 kg ha–1 of nitrogen and 207.5 kg ha–1 of potassium per year[28]. Furthermore, as farm yard manure (FYM) application levels increased, Guinea grass dry matter yield enhanced (239 to 457 kg ha–1 per 1 tonne of FYM) by improving both the productivity and quality of the grasses[29].
Leaf nitrogen content at different harvesting intervals
-
Leaf nitrogen content of M. maximus has been decreased significantly (p < 0.05) with the increment of maturity (Fig. 2b). The highest nitrogen content was recorded at the 4 week growth stage, followed by the 6, 8, 10, and 12 week growth stages. The highest recorded value was 1.49 ± 0.06%, and the lowest was 0.71 ± 0.25%. Compared to the leaf nitrogen content at 6, 8, 10 and 12 week growth stages, 27.98%, 36.70%, 49.85%, and 111.39% more leaf nitrogen was present at the 4 week growth stage.
Guinea grass samples collected from naturally grown fields in low country-wet zone, mid country-wet zone, up country-wet zone, low country-intermediate zone, mid country-intermediate zone, up country-intermediate zone, and low country-dry zone of Sri Lanka had recorded 1.92%, 2.06%, 1.65%, 1.82%, 1.92%, 1.68%, and 1.22% of leaf nitrogen content respectively. Guinea grass samples collected from the mid country-wet zone had the highest leaf nitrogen content and the lowest was from low country-dry zone samples[19].
A study has stated that M. maximus produced a higher herbage nitrogen content when grown under the tree canopy (0.72%) than in the open between canopies (0.55%). The leaf nitrogen content were 1.13% and 0.88%, respectively, when grown under and between canopies, and nitrogen content in stems of M. maximus harvested under and between canopies were 0.42% and 0.35%, respectively[30].
Leaf phosphorous content at different harvesting intervals
-
Leaf phosphorous content was declined significantly (p < 0.05) with increasing maturity (Fig. 2c). The highest leaf phosphorus content (0.29 ± 0.07%) of M. maximus was received when harvested 4 weeks after initial cutting, and the lowest (0.19 ± 0.09%) was recorded when harvested 12 weeks after initial cutting. Compared to the leaf phosphorous content at 6, 8, 10, and 12 weeks of growth stages, 9.59%, 18.96%, 37.05%, and 51.31% more leaf phosphorous was present at 4 weeks of growth stage after initial cutting.
Guinea grass harvested from the seven different agroecological zones of Sri Lanka reported 0.24%, 0.18%, 0.28%, 0.19%, 0.21%, 0.25%, and 0.28% leaf phosphorous content, respectively. Results of the current study also fell into these ranges. According to that research, the highest phosphorous content was recorded in the samples collected from the up-country wet zone and the low-country dry zone, while the lowest was in the samples collected from the mid-country wet zone[19].
Leaf potassium content at different harvesting intervals
-
Similar to leaf nitrogen and phosphorous content, leaf potassium content was also decreased significantly (p < 0.05) with increasing maturity (Fig. 2d). The highest leaf potassium content (3.16 ± 0.43%) resulted at 4 weeks of growth stage after initial cutting and the lowest (1.91 ± 0.26%) at 12 weeks of growth. Compared to the leaf potassium content at 6, 8, 10, and 12 weeks of growth stages, 25.42%, 43.81%, 48.96%, and 65.18% more leaf potassium was present at the 4 weeks of the growth stage. However, leaf potassium content present at the 6 and 8 weeks growth stages did not vary significantly.
The leaf potassium content of Guinea grass from the seven ecological zones were 1.96%, 1.84%, 2.64%, 1.60%, 2.36%, 2.36%, and 1.92%. The highest leaf potassium content was reported from the Guinea grass samples collected from the up-country wet zone and the lowest from the low country–intermediate zone[19].
Leaf calcium and magnesium content at different harvesting intervals
-
Leaf calcium content of Guinea grass was also varied significantly (p < 0.05) with different growth stages and decreased with maturity (Fig. 2e). The highest leaf calcium content received was 0.57% ± 0.06% at 4 weeks of growth, and the lowest was 0. 43% ± 0.09% at 12 weeks of growth. Leaf calcium content present at the 4 and 6 weeks growth stages did not vary significantly. Compared to the leaf calcium content at 8, 10, and 12 weeks of growth stages, 19.36%, 31.78%, and 33.22% more leaf calcium was present at the 4 week growth stage.
Similarly, leaf magnesium content also varied significantly (p < 0.05) with maturity (Fig. 2f). Leaf magnesium content had been reduced with increasing maturity. The highest leaf magnesium content received was 0.45 ± 0.02 at 4 weeks of growth, and the lowest was 0. 32 ± 0.05 at 12 weeks of growth. Compared to the leaf magnesium content at 6, 8, 10, and 12 weeks of growth stages, 16.24%, 22.52%, 31.52%, and 40.18% more leaf magnesium was present at the 4 weeks growth stage.
Four replicates of Guinea grass leaf samples collected from the low country intermediate zone, indicated 0.88% calcium and 0.31% magnesium content[19]. The results of the present study also align with the above findings.
The main green manure types recommended for coconut plantations by the Coconut Research Institute of Sri Lanka are Gliricidia sepium[31,32] and Tithonia diversifolia[33]. Leaf nitrogen, phosphorous, potassium, calcium and magnesium content of Gliricidia sepium are reported to be in the range of 2.5%−3.5%, 0.1%−0.2%, 1.3%−1.7%, 1.0%−1.9%, and 0.3%−0.5% respectively. Gliricidia sepium is recommended to be applied at a rate of 25 kg per adult palm along with 1,375 g of Eppawala Rock Phosphate, 250 g of Dolomite, and 270 g of Muriate of Potash[34]. According to current research findings, Guinea grass can replace traditional green manure more effectively as it supplies 1.49%, 0.29%, 3.16%, 0.57%, and 0.45% of nitrogen, phosphorus, potassium, calcium, and magnesium respectively within a short period[34].
The highest leaf nutrient presented in Guinea grass was potassium (3.16% ± 0.43%) which is one of the major macronutrients required by coconut palm (125.9 kg ha−1 yr−1) at a higher rate[35]. Therefore, Guinea grass can be suggested to be used as a raw material for organic fertilizer production and as green manure for coconut plantations which can not easily be achieved with the application of Gliricidia sepium or Tithonia diversifolia.
-
M. maximus, naturally grown under a coconut plantation in the low country intermediate zone, has shown significant changes in their leaf nutrient content and dry matter yield when harvested at different growth stages after initial cutting. The highest available leaf nutrient of Guinea grass was potassium and thereby can be used as a raw material to produce organic fertilizer for coconut plantations and can be utilized as green manure since potassium is one of the major nutrients required by coconut palm at a higher amount without a natural fertilizer source in the country. Based on the dry matter yield and leaf nutrient composition, Guinea grass can be suggested to be harvested 6 weeks after initial cutting to be used as a raw material to produce organic fertilizer or as green manure for coconut plantations. However, further studies are required to understand the decomposition of Guinea grass when applied as green manure and its impact on the coconut palm and soil properties.
-
We would like to express our gratitude to the technical staff of the Agronomy Division of the Coconut Research Institute of Sri Lanka, for their involvement in collecting and analyzing samples. Mr. Gihan Fernando and Mrs. Asanki Jayamali deserve special appreciation for their enormous contribution to laboratory analysis and compiling data. We would like to express our great appreciation to the editor and two anonymous reviewers for their insightful comments and critical evaluation.
-
The authors declare that they have no conflict of interest.
- Copyright: © 2023 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Udumann SS, Dissanayaka DMNS, Nuwarapaksha TD, Dissanayake DKRPL, Atapattu AJ. 2023. Megathyrsus maximus as a raw material for organic fertilizer production: A feasibility study. Technology in Horticulture 3:9 doi: 10.48130/TIH-2023-0009 

Megathyrsus maximus as a raw material for organic fertilizer production: A feasibility study
- Received: 07 November 2022
- Accepted: 21 March 2023
- Published online: 30 May 2023
Abstract: Megathyrsus maximus (Guinea grass) has a high potential for use as a raw material for organic fertilizer production. In the present study, leaf nutrient content and dry matter yield of naturally grown M. maximus under a coconut plantation were measured when harvested 4, 6, 8, 10, and 12 weeks after initial cutting to evaluate its feasibility. All the Guinea grass in the experiment field was cut at a height of 15 cm and allowed to regrow before harvesting. The percentage of leaf nutrients, nitrogen, phosphorus, potassium, calcium, and magnesium were determined on a dry weight basis, and the dry matter yield per hectare was measured at each harvesting interval. Leaf nutrient content and dry matter yield of M. maximus varied significantly (p < 0.05) when harvested at different growth stages. The highest nutrient levels were recorded when harvested 4 weeks after initial cutting, and the lowest was 12 weeks after initial cutting. The highest dry matter yield was obtained 12 weeks after initial cutting, and the lowest was 4 weeks after initial cutting. The highest leaf nutrient levels recorded for nitrogen, phosphorus, potassium, calcium, and magnesium were 1.49%, 0.29%, 3.16%, 0.57%, and 0.45%, respectively. The highest dry matter yield was 1.89 t ha−1, and the lowest was 0.84 t ha−1. Considering leaf nutrient levels and the dry matter yield, it is suggested that M. maximus can be harvested six weeks after initial cutting to use as a raw material to produce organic fertilizer or as green manure for coconut plantations.
-
Key words:
- Dry matter yield /
- Growth stages /
- Guinea grass /
- Leaf nutrients /
- Organic fertilizer