








-
Traffic flow forecasting plays an important part in intelligent transportation systems[1]. Accurate traffic flow forecasting can effectively avoid traffic congestion and promote the intelligent management of modern transportation. However, traffic flow forecasting is considered a challenging task due to its uncertainty[2].
Over the past decades, researchers have dedicated a lot of effort to designing more effective and efficient models for traffic flow forecasting, which are roughly divided into three categories. The first type are the model-based methods, which have a small number of parameters and need to be manually set by transportation engineers, such as historical average[3], autoregressive integrated moving average[4,5], Kalman filtering model[6−8], spectral analysis, etc. The model-based methods are computationally friendly and require less training data, but they often fail to catch the complex nonlinear dependencies of the traffic flow by a small number of parameters[9].
The second type of model learns the traffic flow distributions from massive data, termed data-driven models. The data-driven models include k nearest neighbors[10], decision trees[11], support vector machine[12], extreme learning machines[13−15], deep learning models[16−18], etc. Among them, deep learning models are generally considered to achieve better performance due to the ability to learn complex nonlinear dependencies from the traffic flow[19]. Lv et al.[20] successfully discover the potential traffic flow representations to improve the traffic flow forecasting performance by a stacked autoencoder (SAE). Zhou et al.[16] proposes a δ-agree boosting strategy to integrate several trained SAEs to eliminate the short-sight of a single SAE. The gravity search algorithm (GSA) is applied in the GSA-ELM model[13] to iteratively generate the input weight matrix and hidden layer deviation for Extreme Learning Machine (ELM), to achieve better prediction performance. The PSOGSA-ELM algorithm[21] employs particle swarm optimization (PSO) algorithm instead of the original ELM random method to generate the initial population of GSA and uses hybrid evolutionary algorithm to complete the data-driven optimization task.
Recently, deep-learning techniques have attracted extensive attention in various fields due to their deep processing of big data. Qu et al.[22] propose a feature injection recursive neural network (FI-RNN), which uses a superimposed recursive neural network (RNN) to learn sequence features of traffic flow and extend context features by training sparse autoencoders. However, the recursive neural networks suffer from gradient vanishing problems. Long short-term memory (LSTM) network[23] is the improved version of RNN, which can effectively capture the time correlation between long sequences by embedding the implicit unit composed of gate structure[24]. The improvements of LSTM networks for traffic flow forecasting can be roughly divided into two types. One is to embed spatial information into the LSTM networks[25], and the other is to improve the robustness of the LSTM network to be effectively immune to outliers[11]. For example, Lu et al.[17] propose a spatial-temporal deep learning network combining multi-diffusion convolution with LSTM for traffic flow forecasting. Zhao et al.[26] propose a hierarchical LSTM model for short-term traffic flow forecasting by finding the potential nonlinear characteristics of traffic flow across the time domain and spatial domain. The LSTM network equipped with a loss-switching mechanism is proven to improve the robustness of the forecasting model at boundary points[18].
The conventional LSTM network often uses mean square error (MSE) as the cost function to guide the optimization of the network parameters. However, the MSE loss is a global metric for the total error between the predictions and the ground truth[18]. The MSE loss works well when the errors between the predictions and the ground truth are independent and identically Gaussian distribution. That is, if traffic flow is stationary, the MSE-guided LSTM networks work plausibly. However, due to hardware failure, artificial traffic control, or accidents, the distribution of the loss is impulsed by the non-Gaussian noises of the traffic flow, and can no longer maintain an identically Gaussian distribution[27].
As shown in Fig. 1, the blue curve represents the fluctuations of traffic flow over time. The traffic flow is changing dynamically over time, and its statistical characteristics are irregular. If the traffic flow is divided into several time segments, as shown by the black dotted line, it is found that the statistical characteristics of the local traffic flow pattern approximately obey a fixed distribution. The whole traffic flow pattern can be regarded as a composite of several independent Gaussian distributions, if the segments are small enough. Motivated by this idea, a local metric can be found to measure the similarity of the predictions and the ground truth of the traffic flow. To achieve this, a more reasonable metric is introduced to simultaneously deal with both Gaussian and non-Gaussian distribution of the network loss.
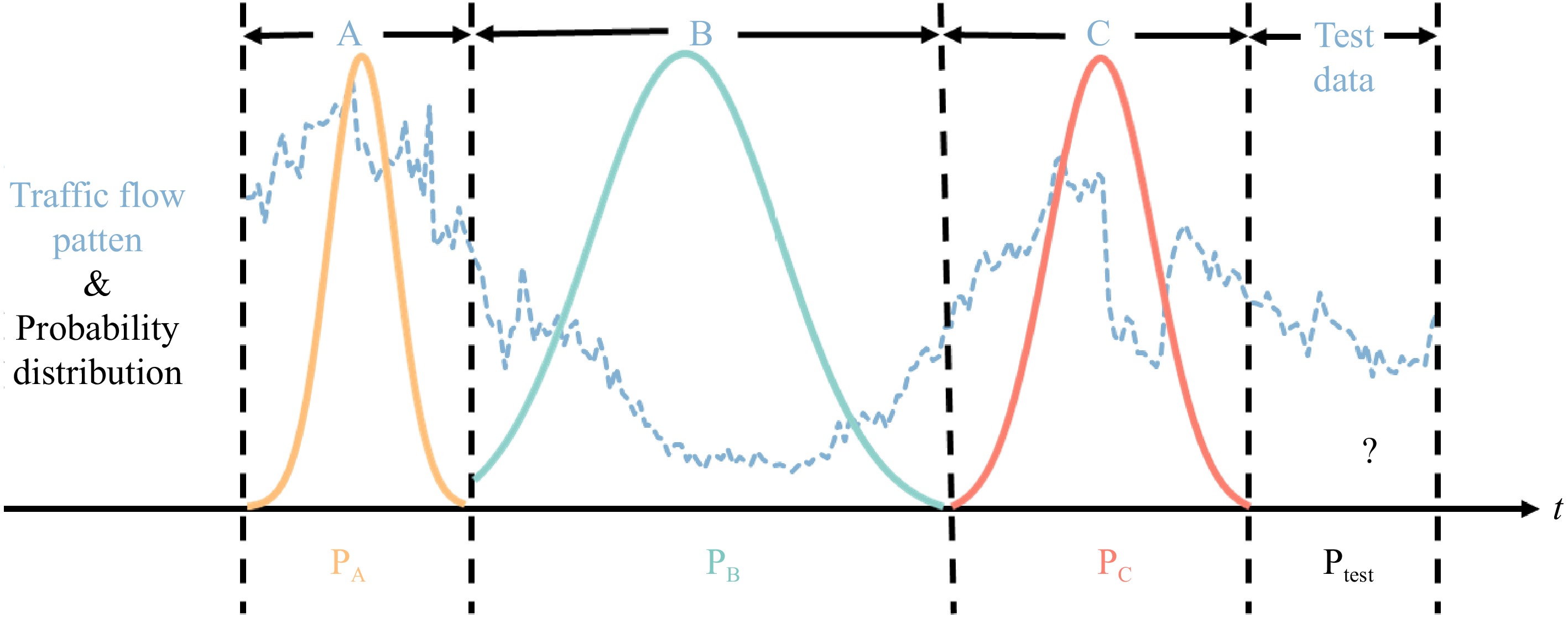
Figure 1.
The probability distribution of traffic flow patterns.
The mixed correntropy (MC) is proposed by Chen et al.[28] for local similarity metric based on information learning theory[29]. The MC criterion linearly combines a series of zero-mean Gaussian functions with different bandwidths as the kernel functions. Networks optimized by such criterion achieve good performance in the Gaussian noise environment and improve the robustness in non-Gaussian networks concurrently. This criterion has been successfully applied for robust short-term traffic flow forecasting. For example, Cai et al.[7] propose a noise-immune Kalman filter deduced by the MC criterion for short-term traffic flow forecasting. Zhang et al.[8] design an outlier-identified Kalman filter for short-term traffic flow forecasting. Cai et al.[27] propose a noise-immune LSTM (NiLSTM) network trained by the maximum correntropy criterion, which has good immunity to outliers in the traffic flow. Zheng et al.[11] propose a noise-immune extreme learning machine for short-term traffic flow forecasting.
The MC criterion only allows the combination of zero-mean Gaussian kernels. It is argued that it is inadvisable to restrict network loss to zero-mean everywhere all the time, especially when the traffic flow changes dramatically. In this work, we would like to answer two questions:
● First, can the network learn the sudden changes and perform better by relaxing the loss to non-zero-mean Gaussian kernels?
● Second, can the network trained by such criterion still maintain the robustness to the errors of non-Gaussian distribution?
To these goals, a
$ {\overline{\delta }}_{relax} $ $ \overline{\delta } $ The main contributions of this work are summarized as follows.
● A loss function is presented for the LSTM based on the mixed correntropy criterion with a variable center to relax the Gaussian assumption of the prediction error to arbitrary mean distribution for traffic flow forecasting.
● Sufficient experiments are conducted on four benchmark datasets for the real-world traffic flow from Amsterdam, The Netherlands. The results and ablation study demonstrate the proposed
$ {\overline{\delta }}_{relax} $ The rest of this paper is organized as follows. The second section briefly introduces the LSTM network and analyzes the existing problems. Then, a
$ {\overline{\delta }}_{relax} $ $ {\overline{\delta }}_{relax} $ $ {\overline{\delta }}_{relax} $ -
In this section, the conventional LSTM network is introduced, its shortcomings analyzed, and then the
$ {\overline{\delta }}_{relax} $ The conventional LSTM network for forecasting
-
The LSTM network has been proven to be stable and powerful in modeling the long-term correlation of traffic flow sequences[27]. The LSTM network is composed of several basic LSTM cell units and a fully connected neural (FCN) network. Taking cell unit un as an example, hn−1 represents the cell hidden state at moment n−1, xn is the cell input at moment n. When hn-1, xn and b enter into the sig and the tanh boxes, it implies that they pass through a basic neural network[23], with output represented by in, fn, on, and C respectively. The relationship is expressed in Eqn (1).
$ \left(\begin{array}{c}\begin{array}{c}{i}_{n}\\ {f}_{n}\\ {o}_{n}\end{array}\\ \tilde{C}\end{array}\right)=\left(\begin{array}{c}\begin{array}{c}sigmoid\\ sigmoid\\ sigmoid\end{array}\\ tanh\end{array}\right)W\left(\genfrac{}{}{0pt}{}{{x}_{n}}{{h}_{n-1}}\right)+\left(\begin{array}{c}\begin{array}{c}{b}_{i}\\ {b}_{f}\\ {b}_{o}\end{array}\\ {b}_{C}\end{array}\right) $ (1) where, W represents the weight matrix in the hidden layer of the basic neural network, and xn, is the normalized data. In Eqn (1), in, fn and on are called the input gate, the forgetting gate, and the output gate respectively, and
$ \tilde{C} $ $ \tilde{C} $ $ \tilde{C} $ And then the cell state cn is calculated, which can be calculated by summing cn−1 and
$ \tilde{C} $ $ \tilde{C} $ $ {c}_{n}={f}_{n}\otimes{c}_{n-1}+{i}_{n}\otimes\tilde{C} $ (2) Since cn−1 means the previous cell state,
$ \tilde{C} $ Then calculate the cell output hn which is the result of the activated value of cn to a certain extent. The extent is determined by the output gate on, as shown in Eqn (3).
$ {h}_{n}={o}_{n}\otimes\mathrm{t}\mathrm{a}\mathrm{n}\mathrm{h}\left({c}_{n}\right) $ (3) Finally, hn is entered into an FCN network to get the prediction
$ {\hat{x}}_{n+1} $ Before using the LSTM network to predict traffic flow, it is necessary to train the parameters of the LSTM network by back-propagation algorithm under the guidance of the error function. The error function of the conventional LSTM network is the mean square error (MSE) function, and its expression is shown in Eqn (4).
$ MSE=\dfrac{1}{N}\textstyle\sum _{n=1}^{N}{\left({\hat{x}}_{n+1}-{x}_{n+1}\right)}^{2} $ (4) where,
$ {\hat{x}}_{n+1} $ As shown in Eqn (4), when the data is a stationary sequence, or when the noise is Gaussian noise or noiseless, satisfying
$ |{\hat{x}}_{n+1}-{x}_{n+1}| < 1 $ $ |{\hat{x}}_{n+1}-{x}_{n+1}| > 1 $ The $ {\overline{{\delta }}}_{\mathit{r}\mathit{e}\mathit{l}\mathit{a}\mathit{x}} $-LSTM network for forecasting
-
Although the LSTM model can learn long sequence dependence, its prediction performance is highly dependent on the MSE criterion. However, the MSE criterion assumes that the prediction error obeys Gaussian independent identical distribution (i.i.d), which makes MSE not suitable for complex traffic flow sequences containing non-Gaussian noise such as impulse noise. To solve this problem, we propose to introduce the MCVC function into the LSTM network to guide network parameters, to carry out higher-quality traffic flow forecasting.
It is well known that the error function plays a key role in the performance of deep learning networks. From the perspective of information theory, the correntropy criterion, as a nonlinear similarity measure, has been successfully used as an effective optimization cost in signal processing and machine learning[28]. The correntropy between two random variables X and Y is shown in Eqn (5).
$ V(X,Y)=\mathbb{E}\left[{\text ƙ}\right(e\left)\right]=\dfrac{1}{N}\textstyle\sum _{n=1}^{N}{\text ƙ}\left({e}_{n}\right) $ (5) where,
$ \mathbb{E}[\cdot ] $ ${\text ƙ}(\cdot) $ It is worth noting that the selection of the kernel function
$ {\text ƙ} $ $ {\text ƙ}\left(e\right)={\parallel e\parallel }^{d} $ $ {\text ƙ}\left(e\right)=\dfrac{1}{N}\sum _{n=1}^{N}\mathrm{e}\mathrm{x}\mathrm{p}[-\dfrac{{\Delta }_{n}^{2}}{2{\delta }^{2}}] $ $ {V}_{MC}=\textstyle\sum _{i=1}^{I}{\alpha }_{i}\dfrac{1}{N}\textstyle\sum _{n=1}^{N}{G}_{{\delta }_{i}}\left({e}_{n}\right) $ (6) where, δi is the kernel bandwidth of the ith Gaussian kernel, and αi is the corresponding proportionality coefficient, satisfying α1 + α2 + ... + αI = 1. Since the Taylor expansion of Gaussian kernel is a measure from zero to infinite order, it can contain the measure order of non-Gaussian noise whether it is heavy tail noise or light tail noise, so Gaussian kernel is easy to eliminate non-Gaussian noise in the training process.
In Eqn (6), VMC is a linear combination of multiple Gaussian cores. Besides, it is found that the mean error of a single Gaussian kernel in VMC is zero, that is, VMC can only have a good effect on the noise under the mixed Gaussian kernel with the center of zero. Then, Chen et al.[30] proposed the MCVC criterion to further improve the performance of correntropy by enhancing the applicability of correntropy, as shown in Eqn (7).
$ {V}_{MCVC}=\textstyle\sum _{k=1}^{K}{\lambda }_{k}\dfrac{1}{N}\textstyle\sum _{n=1}^{N}{G}_{{\delta }_{k}}({e}_{n}-{c}_{n}) $ (7) where, δk defines the kernel bandwidth of the kth Gaussian kernel, and λk is the corresponding proportionality coefficient, satisfying λ1 + λ2 + ... +λk = 1.
It should be noted that the kernel function in VMCVC is a multi-Gaussian function, which usually does not satisfy Mercer's condition. However, this is not a problem because Mercer's condition is not required for the similarity measure[30]. As for the convergence of 1, it involves the kernel method and the unified framework of regression and classification. However, the convergence of 1 can be guaranteed if an appropriate parameter search method is adopted[31].
To consider both Gaussian error and non-Gaussian error of LSTM network, an
$ {\overline{\delta }}_{relax} $ $ \begin{split}L=\;&1-{V}_{MCVC} =1-\sum _{k=1}^{K}{\lambda }_{k}\dfrac{1}{N}\textstyle\sum _{n=1}^{N}{G}_{{\delta }_{k}}\left({e}_{n}-{c}_{n}\right)\\ =\;&1-\Bigg({\lambda }_{1}\dfrac{1}{N}\textstyle\sum _{n=1}^{N}\mathrm{exp}\left[-\dfrac{{\left({e}_{n}-{c}_{n}\right)}^{2}}{2{{\delta }_{1}}^{2}}\right]+\cdots +\\&{\lambda }_{K}\dfrac{1}{N}\textstyle\sum _{n=1}^{N}\mathrm{exp}\left[-\dfrac{{\left({e}_{n}-{c}_{n}\right)}^{2}}{2{{\delta }_{K}}^{2}}\right]\Bigg)\end{split} $ (8) Through the analysis of Eqn (8), the advantages of
$ \mathcal{L} $ ●
$ \mathcal{L} $ $ \dfrac{{\left({e}_{n}-{c}_{n}\right)}^{2}}{2{\delta }^{2}} $ ● When K = 2 , δ1 < δ2, and
$ {\delta }_{1}\to \infty $ $ {\overline{\delta }}_{relax} $ $ \mathcal{L} $ ● The single Gaussian kernel in
$ \mathcal{L} $ $ \mathcal{L} $ -
In this section, the performance of the
$ {\overline{\delta }}_{relax} $ Data description
-
The datasets A1, A2, A4, and A8 obtained by Monica sensor collected by Wang et al.[33] were used in the experiment, which records the traffic flow per minute of A1, A2, A4, and A8 freeways within 35 d starting from May 20, 2010. These datasets are widely used in the evaluation of traffic flow prediction models[7,9,16,21,34,35].
The geographical location of the four expressways is shown in Fig. 2. Among them, the A1 highway is the first double three-lane highway with a high utilization rate in Europe, connecting Amsterdam and the German border. Its traffic volume has changed greatly over time, which increases the difficulty of prediction. The A2 motorway connects Amsterdam to the Belgian border with more than 2,000 vehicles an hour. The A4 highway connects the city of Amsterdam to Belgium’s northern border and is 154 km long. The A8 highway starts at the northern end of the A10 highway and ends at Zaandijk, which is less than 10 km in length.
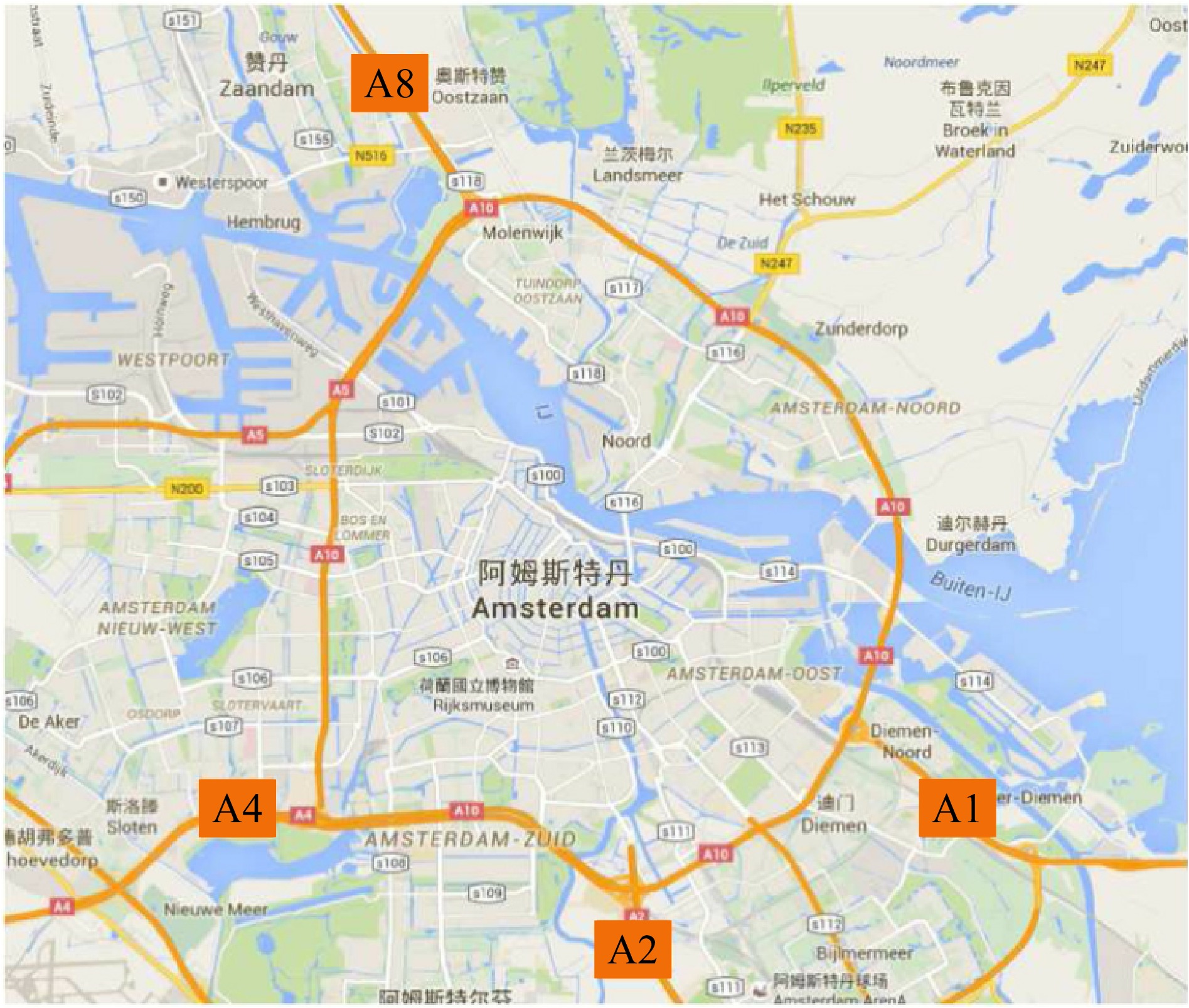
Figure 2.
The four motorways of Amsterdam.
In the experiment, the data are aggregated as vehicles per hour in 10 min, in the unit of vehs/h, which is consistent with other traffic flow prediction models[6,9]. The first 28 d of the dataset were used for training the model, and the last 7 d were used for testing. All data are normalized to the maximum and minimum before being sent into the model.
Evaluation criteria
-
In the test, two common indicators, root mean square error (RMSE) and mean absolute percentage error (MAPE), were used to evaluate all the prediction methods. RMSE measures the average difference between the predicted and true values, while MAPE represents the percentage difference between them. The calculation methods of RMSE and MAPE are shown in Eqns (9) and (10), respectively.
$ \mathrm{R}\mathrm{M}\mathrm{S}\mathrm{E}=\sqrt{\dfrac{1}{M}\textstyle\sum _{m=1}^{M}{({y}_{m}-{\hat{y}}_{m})}^{2}} $ (9) $ \mathrm{M}\mathrm{A}\mathrm{P}\mathrm{E}=\dfrac{1}{M}\textstyle\sum _{m=1}^{M}\left|\dfrac{{y}_{m}-{\hat{y}}_{m}}{{y}_{m}}\right|\times 100{\text{%}} $ (10) where, M means the total number of samples in the test set,
$ {\hat{y}}_{m} $ Performance evaluation
-
In this section, the test results of
$ {\overline{\delta }}_{relax} $ $ {\overline{\delta }}_{relax} $ $ {\overline{\delta }}_{relax}$ $ {\overline{\delta }}_{relax} $ In this part, the performance of
$ {\overline{\delta }}_{relax} $ The data preprocessing method of the KF model in Table 1 adopts the wavelet de-noising method proposed by Xie et al.[32], the mother wavelet uses Daubechies 4, and the variance of processing error is V = 0.1I, where I represents the identity matrix. The variance of the measurement noise is 0, so the measurement is considered to be correct. The initial state is defined as [1/N, ..., 1/N] with N = 8. The covariance matrix of the initial state estimation error is expressed as 10−2I. The ANN is a one-hidden-layer feed-forward neural network, where the mean squared, error is set to 0.001, the spread of a radial basis function (RBF) is 2000, and the maximum number of neurons in a hidden layer is set as 40. Through cross-validation, the parameter setting of the SAE network is [120, 60, 30], and the hierarchical greedy training method is adopted. In the LSTM, NiLSTM, and
$ {\overline{\delta }}_{relax} $ Table 1. The comparison of the $ {\overline{\delta }}_{relax} $-LSTM model with five baseline models on the four baseline datasets, with boldface representing the best performance.
Models Criterion A1 A2 A4 A8 HA RMSE (vehs/h) 404.84 348.96 357.85 218.72 MAPE (%) 16.87 15.53 16.72 16.24 KF RMSE (vehs/h) 332.03 239.87 250.51 187.48 MAPE (%) 12.46 10.72 12.62 12.63 ANN RMSE (vehs/h) 299.64 212.95 225.86 166.50 MAPE (%) 12.61 10.89 12.49 12.53 SAE RMSE (vehs/h) 295.43 209.32 226.91 167.01 MAPE (%) 11.92 10.23 11.87 12.03 GSA-ELM RMSE (vehs/h) 287.89 203.04 221.39 163.24 MAPE (%) 11.69 10.25 11.72 12.05 PSOGSA-ELM RMSE (vehs/h) 288.03 204.09 220.52 163.92 MAPE (%) 11.53 10.16 11.67 12.02 LSTM RMSE (vehs/h) 289.56 204.71 224.49 165.13 MAPE (%) 12.38 10.56 11.99 12.48 NiLSTM RMSE (vehs/h) 285.54 203.69 223.72 163.25 MAPE (%) 12.00 10.14 11.57 11.76 $ {\overline{\delta }}_{relax} $-LSTM RMSE (vehs/h) 280.54 195.28 220.08 161.69 MAPE (%) 11.48 10.02 11.51 11.54 In addition, for the
$ {\overline{\delta }}_{relax} $ Table 2. The hyperparameters for the LSTM, NiLSTM, and $ {\overline{\delta }}_{relax} $- LSTM network.
Hyperparameter value Value Hidden layers 1 Hidden units 256 Batch size 32 Input length 12 Epochs 200 Table 3. The parameter settings of $ \mathcal{L} $ for the $ {\overline{\delta }}_{relax} $-LSTM network.
Dataset λ1 λ2 δ1 δ2 c1 c2 A1 0.6 0.4 0.3 10 0 −1 A2 0.8 0.2 30 0.3 5 0 A4 1 0 0.7 30 0 −0.5 A8 0.6 0.4 0.3 15 0 −1 The performance results are listed in Table 1. According to the results in Table 1, the prediction effect of the
$ {\overline{\delta }}_{relax} $ $ {\overline{\delta }}_{relax} $ -
In this paper, an
$ {\overline{\delta }}_{relax}$ $ {\overline{\delta }}_{relax} $ $ {\overline{\delta }}_{relax} $ The research was supported by the Natural Science Foundation of China (No. 62462021, 61902232), the Philosophy and Social Sciences Planning Project of Zhejiang Province (No. 25JCXK006YB), the Hainan Province Higher Education Teaching Reform Project (No. HNJG2024ZD-16), the Natural Science Foundation of Guangdong Province, China (No. 2022A1515011590), and the National Key Research and Development Program of China (No. 2021YFB2700600).
-
The authors confirm contribution to the paper as follows: conceptualization, project administration: Zhou T, Lin Z; data curation, methodology, visualization: Fang W; formal analysis, validation: Fang W, Li X; funding acquisition, supervision: Zhou T; investigation: Li X, Lin Z, Zhou J; writing – original draft: Fang W, Zhou T. All authors have read and agreed to the published version of the manuscript.
-
The data that support the findings of this study are available from the corresponding author on reasonable request.
-
The authors declare that they have no conflict of interest.
- Copyright: © 2024 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Fang W, Li X, Lin Z, Zhou J, Zhou T. 2024. Mixture correntropy with variable center LSTM network for traffic flow forecasting. Digital Transportation and Safety 3(4): 264−270 doi: 10.48130/dts-0024-0023 

Mixture correntropy with variable center LSTM network for traffic flow forecasting
- Received: 11 September 2024
- Revised: 28 October 2024
- Accepted: 11 November 2024
- Published online: 27 December 2024
Abstract: Timely and accurate traffic flow prediction is the core of an intelligent transportation system. Canonical long short-term memory (LSTM) networks are guided by the mean square error (MSE) criterion, so it can handle Gaussian noise in traffic flow effectively. The MSE criterion is a global measure of the total error between the predictions and the ground truth. When the errors between the predictions and the ground truth are independent and identically Gaussian distributed, the MSE-guided LSTM networks work well. However, traffic flow is often impacted by non-Gaussian noise, and can no longer maintain an identical Gaussian distribution. Then, a $ {\overline{\delta }}_{relax} $-LSTM network guided by mixed correlation entropy and variable center (MCVC) criterion is proposed to simultaneously respond to both Gaussian and non-Gaussian distributions. The abundant experiments on four benchmark datasets of traffic flow show that the $ {\overline{\delta }}_{relax} $-LSTM network obtained more accurate prediction results than state-of-the-art models.
-
Key words:
- Traffic flow theory /
- Machine learning /
- Robust modeling /
- Mixture correntropy