









-
Ubiquitination is an important process of post-translational modification of proteins that occurs in eukaryotic organisms, modulating a broad range of biological processes. There are three types of catalytic activities involved in this process: ubiquitin-activating enzyme (E1), ubiquitin-conjugating enzyme (E2), and ubiquitin ligase (E3)[1]. Initially, the E1 enzyme initiates the ubiquitin molecule in an ATP-dependent manner, and then these molecules are further progressed with the aid of E2. Finally, E3 covalently attaches E2 to the target protein. Target proteins are then tagged by multiple ubiquitin molecules and can be degraded by the 26S proteasome. E3 ubiquitin ligase is the most effective of these three enzymes in evaluating the specificity of the ubiquitination mechanism by selecting appropriate candidate proteins[2]. E3 is the most important factor in ubiquitination pathways, as it is present in a wide range of substrates. In Arabidopsis, more than 1,400 genes encode the functional components of the ubiquitination pathway, of which about 90% of genes are related to E3[3,4]. Based on the presence of domains and functional mechanism, E3 ubiquitin ligases are classified into single-subunit type, (HECT, RING/U-box ligases)[4] and multi-subunit type, such as SCF (skp1-cullin-F-box), APC (anaphase-promoting complex)[5] VBC (VHL-Elongin B-Elongin C)[6], etc. U-box proteins are categorized by the existence of their domain and that is mainly equal to up to 70 amino acids[7,8]. Both U-box and Ring domain proteins shared almost identical tertiary structures with slight differences such as the formation of salt-bridges for the stabilization of its structure[8]. So far, the presence of U-box proteins has been reported in a variety of organisms like yeast, plants, and animals[9−11]. The abundance of U-box genes varies from organism to organism. For example, in yeast genome two U-box genes have been reported, while 21 has been annotated in the human genome[8,12,13].
To date, the main abundance of U-box protein has been reported in plants[14], and the presence of U-box protein in plants is known as PUBs. PUB proteins are members of the E3 ubiquitin ligase family[9]. PUB genes have been reported in a variety of plant species, including, 64 in Arabidopsis thaliana, 70 Oryza sativa, 33 Chlamydomonas reinhardtii, 101 Brassica rapa, and 125 Glycine mix[15−19], suggesting that PUB genes are widely dispersed in plants. Yet, a comprehensive genome-wide analysis on their identification and expression profiling under multiple organs-tissues along with abiotic stresses still lacking in tomato.
The presence of a U-box domain in PUB proteins is typically used to classify them. As a result, they're divided into subgroups[9,16,20−22]. PUB proteins with ARM domains and PUB proteins with Kinase domains are the two most common types found in plants. However, several other species-specific groups have also been reported particularly in Arabidopsis and rice, such as the occurrence of two PUB-MIF4G proteins and one PUB-TPR-Kinase[9,15,16], respectively.
Increasing evidence proposes that PUB proteins play critical roles in various plant developmental and physiological processes, such as abiotic stress responses. CaPUB1, a U-box E3 protein found in water-stressed hot pepper plants, and its overexpression was found to be more susceptible to water stress and mild salinity[23]. In Arabidopsis, AtPUB22 and AtPUB23 proteins act as negative regulators against drought tolerance by RPN12a ubiquitination[24]. U-box E3 protein AtPUB19 is induced by drought, salt, cold, and ABA in Arabidopsis. Down-regulating the AtPUB19 expression resulted in hypersensitivity to ABA, enhancing ABA-induced stomata closing, and drought tolerance, while overexpression of AtPUB19 exhibited the reverse phenotypes[25]. Furthermore, Arabidopsis AtPUB44/SAUL1 E3 ubiquitin ligase inhibits premature leaf senescence by decreasing the ABA level, and AtPUB43 mutants displayed an increased seed germination rate compared with the wild type [24] at inhibitory concentrations of ABA[26,27]. In rice, the overexpression of OsPUB15 significantly regulated the drought and salt resistance positively, and further reduced the intracellular oxidative stress[28].
Tomato (Solanum lycopersicum) is one of the vital economic crops and ranks fourth in global vegetable production worldwide. It is also a model plant species for fleshy fruit development and a rich source of nutrients[29]. The scale of production of tomato is however mainly constrained due to a series of various biotic and abiotic factors[30]. Hence, the identification of the gene family is a useful strategy for improving tomato development and crop production improvement. To the best of our knowledge, there are no reports for genome-wide investigation and wide-ranging transcriptional profiling of PUB genes in tomato to date. While the availability of the tomato whole-genome sequence[29] provides valuable resources for an in-depth understanding of gene functioning and evolution. In the present study, we systematically studied the PUB gene family in tomatoes such as basic properties, chromosomal localization, collinear analysis, synonymous-non synonymous mutation, gene duplications, organ-tissue expression profiles, abiotic stress, and functional evolution. These results will facilitate future research for understanding the PUB gene in functional genomic studies, as well as their utilization under abiotic stress in this important crop.
-
In this study, a total of 48 PUB genes were explored from the tomato genome and were renamed as SlPUB1-SlPUB48 based on their chromosomal positions from Chromosome 1−12 (Chr1−12). For these genes, we explored various gene properties including, chromosomal distribution, coding sequence (CDS) length (bp), and five different types of protein properties which include, protein length[26], molecular weight (MW) kDa, isoelectric point (PIs), grand average of hydropathicity (GRAVY), and subcellular prediction for each of PUBs protein (Dataset 1). The PUB genes in tomato were randomly distributed on the 1−12 chromosomes of the tomato genome, except none of the genes were detected on Chr8 and Chr10. The CDS length of SlPUB ranged from 831−3,141 bp (SlPUB32-SlPUB27), the protein length ranged from 276−1,046 aa (SlPUB32-SlPUB27). Similarly, the MW ranged from 31.77−118.442 kDa (SlPUB32-SlPUB14), the PIs 5.2−9.12 (SlPUB15-SlPUB2), and GRAVY −0.528 (SlPUB32) to 0.137 (SlPUB22). The observed variability among SlPUB genes specifically for GRAVY analysis revealed most of them were hydrophilic and only four genes i.e., SlPUB11, SlPUB7, SlPUB25, and SlPUB22 were hydrophobic having positive values. Also, the subcellular localization analysis predicted that the maximum PUB genes were involved in the nucleus, cytoplasm, chloroplast, plasma membrane, vacuole, and endoplasmic reticulum.
Phylogenetic characterization, motif and gene structure analysis of PUB genes in tomato
-
To explore the evolutionary relationships, we constructed a neighbor-joining phylogenetic tree by utilizing the protein sequences i.e., 48 from tomato and 64 from Arabidopsis. The results revealed that PUB genes were clustered into seven subgroups (Fig. 1) and show the uneven distribution of SlPUB when compared with AtPUB. Notably, group V was observed with the most number of genes (29), followed by group VII and VI with eight and six genes respectively. Based on the group-wise comparison of SlPUB, group V and VI were scattered in the phylogenetic tree and showed relatively close genetic relationships with Arabidopsis.
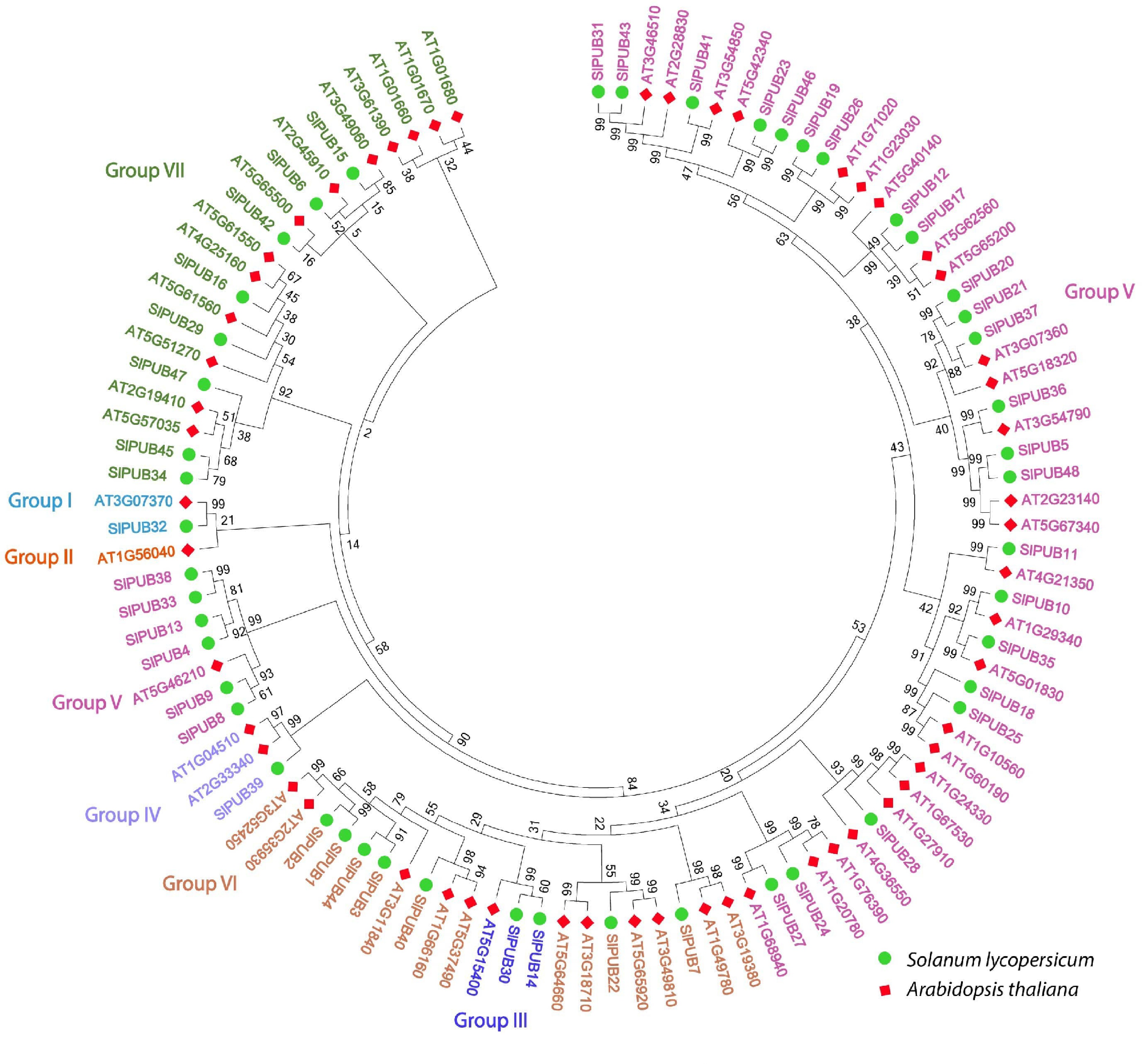
Figure 1.
Phylogenetic relationships of the PUB genes between tomato and Arabidopsis. The seven different subgroups of PUBs are indicated in different colors.
To better understand the conservation and diversification among PUBs, we analyzed the conserved motifs and gene structure. The motifs analysis was explored by the MEME program, and motifs ranged from 1−10 for SlPUBs. The results showed that several motifs were widely dispersed, however, motifs 1 and 4 were highly conserved amongst almost all the members of PUBs, suggesting their common evolution and the rest of PUB members indicated slightly structural diversification among the SlPUB gene family (Fig. 2a). Again, the MEME server was explored for the PUB protein LOGOS of these motifs. Motif6 was found with the highest number (100) of consensus sequences, while motif4 with a fewest number (50) of sequences (Supplemental Fig. S1). The gene structure analysis showed similar patterns to the motif composition, most of the PUBs generally exhibited similar gene structure in terms of their lengths (Fig. 2b). However, two of them showed contrasting results such as SlPUB8 and SlPUB9. These results suggested that most of the PUBs carry similar features and slight differentiation in their sources of functions during the process of evolution.
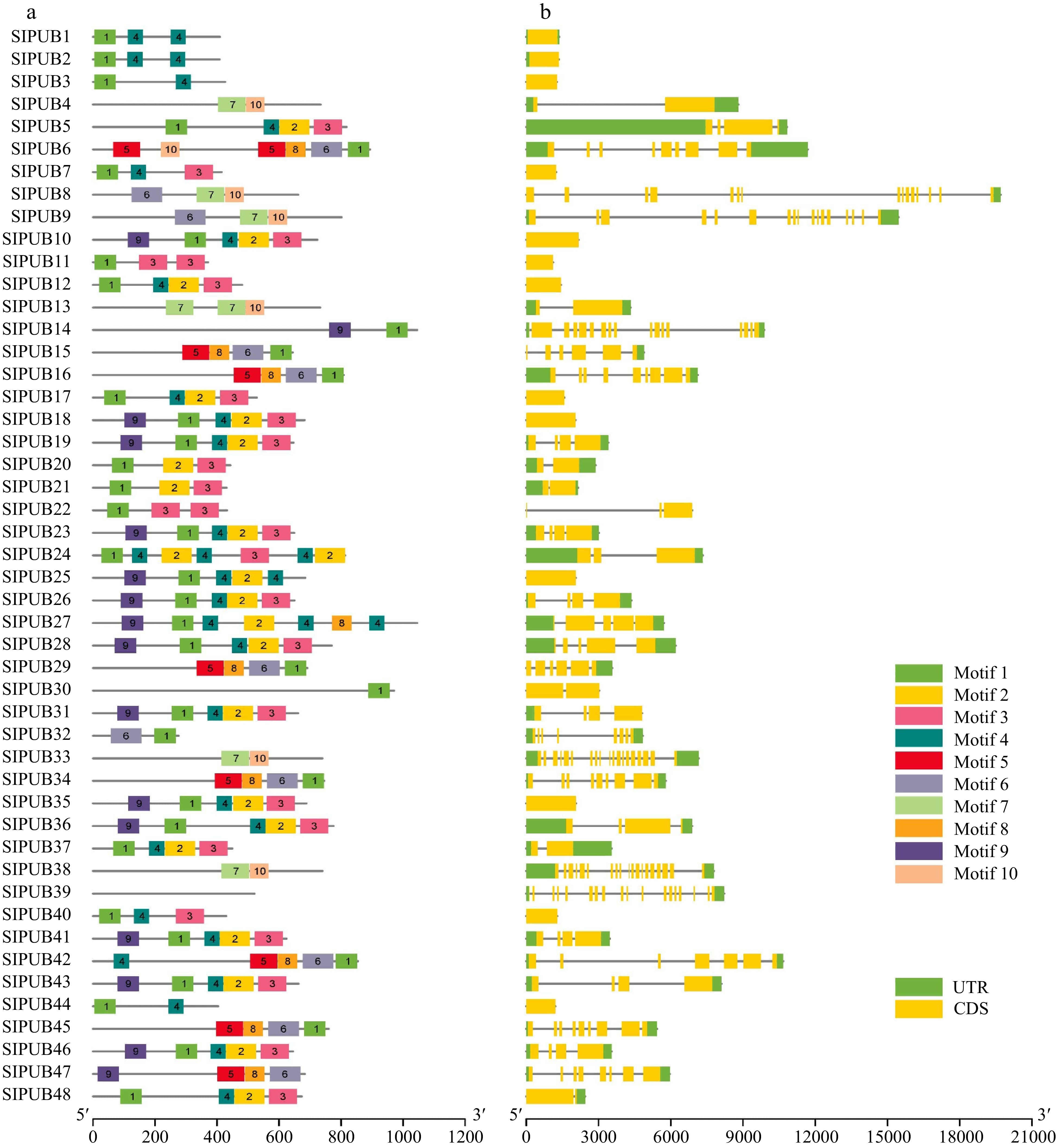
Figure 2.
(a) Motif structures and (b) gene structures of PUBs in tomato. The different motifs (Motif 1 − Motif 10) are displayed in different colors. The gene structures of PUBs are based on the coding sequences (CDS) and untranslated region (UTR) which are shown in yellow and green.
Gene collinearity, duplication, and Ka/Ks analysis of PUB
-
The chromosomal mapping of 48 PUB genes in tomato from Chr1-Chr12 was drawn by using TBtools software. All the PUB genes were distributed across the tomato genome except Chr8 and Chr10 as shown in Fig. 3. The distribution of the number of genes varies from chromosome such as the maximum amount of genes (7) was identified on Chr1 and Chr2, followed by Chr4 possessing six genes, while five of each gene were located on Chr5, Chr9 and Chr11. Thus, these results unveiled their uneven patterns among PUB members in the tomato genome. Collinearity relationships between PUB genes were also demonstrated by drawing circos using the TBtools software. Among SlPUB, high conservation of nucleotide was detected and a total of 11 pairs were detected as collinear with possible interaction with each other and another family. These collinear pairs include: SlPUB6-SlPUB15, Solyc01g099290-SlPUB38, SlPUB8-SlPUB9, SlPUB12-SlPUB17, SlPUB18-SlPUB25, SlPUB19-SlPUB26, SlPUB23-SlPUB46, Solyc06g008710-SlPUB38, SlPUB31-SlPUB43, SlPUB34-SlPUB45, and SlPUB41-SlPUB43. The two unknown genes (Solyc01g099290 and Solyc06g008710) were identified as cullins genes based on their domain analysis, and these genes are recognized for their vital role in the process of ubiquitination in combination with diverse cellular processes[31]. Additionally, the gene duplication investigation displayed that the maximum of the genes (26) were dispersed type followed by whole-genome duplication (WGD) or segmental (19), and tandem (3) as shown in Fig. 3.
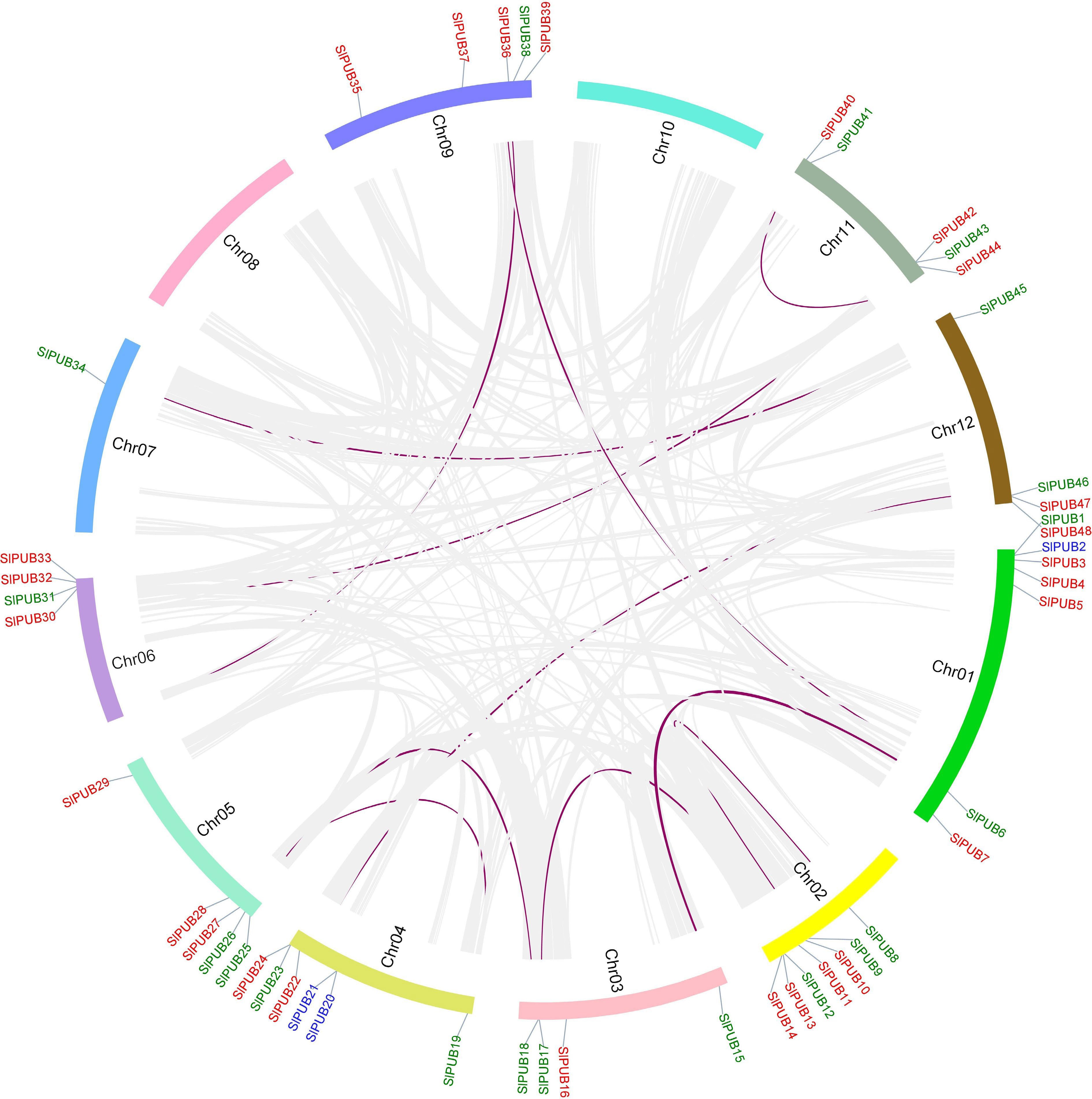
Figure 3.
Chromosomal locations of the PUB genes in the tomato genome from Chr1-Chr12. The collinear genes are presented inside the circle in purple. The different types of duplication such as dispersed, segmental, and tandem are marked in red, green, and blue.
The synonymous with non-synonymous mutation analysis was also performed among the different types of gene duplications in tomato i.e., dispersed, tandem, and WGD or segmental. In the process of evolution, genes are typically associated with diverse kinds of selection pressure that include, purifying selection (Ka/Ks < 1), positive selection (Ka/Ks > 1), and neutral selection (Ka/Ks = 1)[32]. A possible combination of 23 pairs was selected for Ka/Ks calculation based on their duplication types i.e., 13 pairs of dispersed, one tandem, and nine pairs of WGD or segmental as described in Table 1. The results have shown that the maximum of gene pairs having a Ka/Ks ratio of less than 1.00, from three different types of duplication. These analyses signifying that purifying selection and reducing divergence occurred among them. Only three pairs of dispersed genes that include, SlPUB16-SlPUB22, SlPUB30-SlPUB32, and SlPUB36-SlPUB37 were perceived with greater than 1.00 values, suggesting positive selection.
Table 1. Gene duplications of PUB genes in tomato with outlier Ka/Ks values.
Gene 1 Gene 2 Ks Ka Ka/Ks Selection pressure Gene duplications SlPUB3 SlPUB4 0.74 0.59 0.80 Dispersed Purifying SlPUB5 SlPUB7 0.68 0.62 0.92 Dispersed Purifying SlPUB10 SlPUB11 0.65 0.59 0.90 Dispersed Purifying SlPUB13 SlPUB14 0.80 0.59 0.73 Dispersed Purifying SlPUB16 SlPUB22 0.58 0.61 1.06 Dispersed Positive SlPUB24 SlPUB27 0.70 0.68 0.98 Dispersed Purifying SlPUB28 SlPUB29 0.88 0.63 0.71 Dispersed Purifying SlPUB30 SlPUB32 0.44 0.45 1.03 Dispersed Positive SlPUB33 SlPUB35 0.88 0.62 0.70 Dispersed Purifying SlPUB36 SlPUB37 0.46 0.67 1.45 Dispersed Positive SlPUB39 SlPUB40 0.78 0.65 0.83 Dispersed Purifying SlPUB42 SlPUB44 0.72 0.53 0.73 Dispersed Purifying SlPUB47 SlPUB48 0.75 0.61 0.82 Dispersed Purifying SlPUB20 SlPUB21 0.22 0.11 0.52 Tandem Purifying SlPUB1 SlPUB6 0.63 0.46 0.74 WGD or Segmental Purifying SlPUB8 SlPUB9 0.65 0.05 0.07 WGD or Segmental Purifying SlPUB12 SlPUB15 0.74 0.61 0.82 WGD or Segmental Purifying SlPUB17 SlPUB18 0.76 0.65 0.86 WGD or Segmental Purifying SlPUB19 SlPUB23 1.08 0.55 0.51 WGD or Segmental Purifying SlPUB25 SlPUB26 0.76 0.66 0.87 WGD or Segmental Purifying SlPUB31 SlPUB34 0.77 0.62 0.80 WGD or Segmental Purifying SlPUB38 SlPUB41 0.79 0.61 0.77 WGD or Segmental Purifying SlPUB43 SlPUB45 0.80 0.64 0.80 WGD or Segmental Purifying Transcriptional analysis of PUB genes in multiple tissues and developmental stages in tomato
-
Three major Illumina RNA-seq datasets of various multiple tissues were utilized from cultivated tomato (Solanum lycopersicum cv. Heinz) and the wild relative Solanum pimpinellifolium[33,34], and the Micro-Tom (MT) (unpublished data). The ten tissues from the cultivated tomato include bud, flower, leaf, roots, 1 cm, 2 cm, 3 cm, mature green, breaker, and breaker+ 10 fruits. From the wild relative, eight tissues and organs, which included anthesis flower (0DPA), 10 d post-anthesis (DPA) fruit, 20 DPA fruit, ripening fruit (33 DPA), mature leaves (ML), whole root (WR), young flower buds (YFB), and young leaves[30], were selected for analysis. The data from our unpublished RNA-seq data of the model variety Micro-Tom (MT) was also utilized for four different tissues at various stages such as root 30, 45, and 85 days post germination (DPG), stem 30, 45, and 85 DPG, leaf 30, 45, and 85 DPG, and flower 30 and 45 DPG. Several developmental stages like, 10 DPA (55 DPG), 20 DPA (65 DPG), immature green (IMG) at 75 DPG, mature green (MG) at 80 DPG, Br (85 DPG), Br3 (88 DPG), Br7 (92 DPG), Br10 (95 DPG) and Br15 (100 DPG).
To represent the tissue-specific expression of 48 SlPUB genes, a heatmap was generated on RPKM values. Results of Heinz and MT data showed an almost identical expression pattern and slight inconsistency with its wild relative such as SlPUB4-SlPUB19, SlPUB22, SlPUB24, SlPUB26, SlPUB28, SlPUB30-SlPUB39, SlPUB41-43, SlPUB47, and SlPUB48 significantly expressed in both of them (Figs 4a, 5a & 5b) and Dataset 2 and 3. While, the wild relative showed that SlPUB4-SlPUB17, SlPUB19, SlPUB22, SlPUB24, SlPUB26, SlPUB28, SlPUB30-SlPUB34, SlPUB36-SlPUB39, SlPUB41-43, SlPUB47 and SlPUB48 were significantly expressed entirely in the tissues, indicating their foremost contribution in tissue-specific response and development (Fig. 4b) and Dataset 4. The remaining PUB genes showed either very low, moderate, and even a few of them were not expressed in or several selected tissues, suggesting their slightly partial response in tomato.
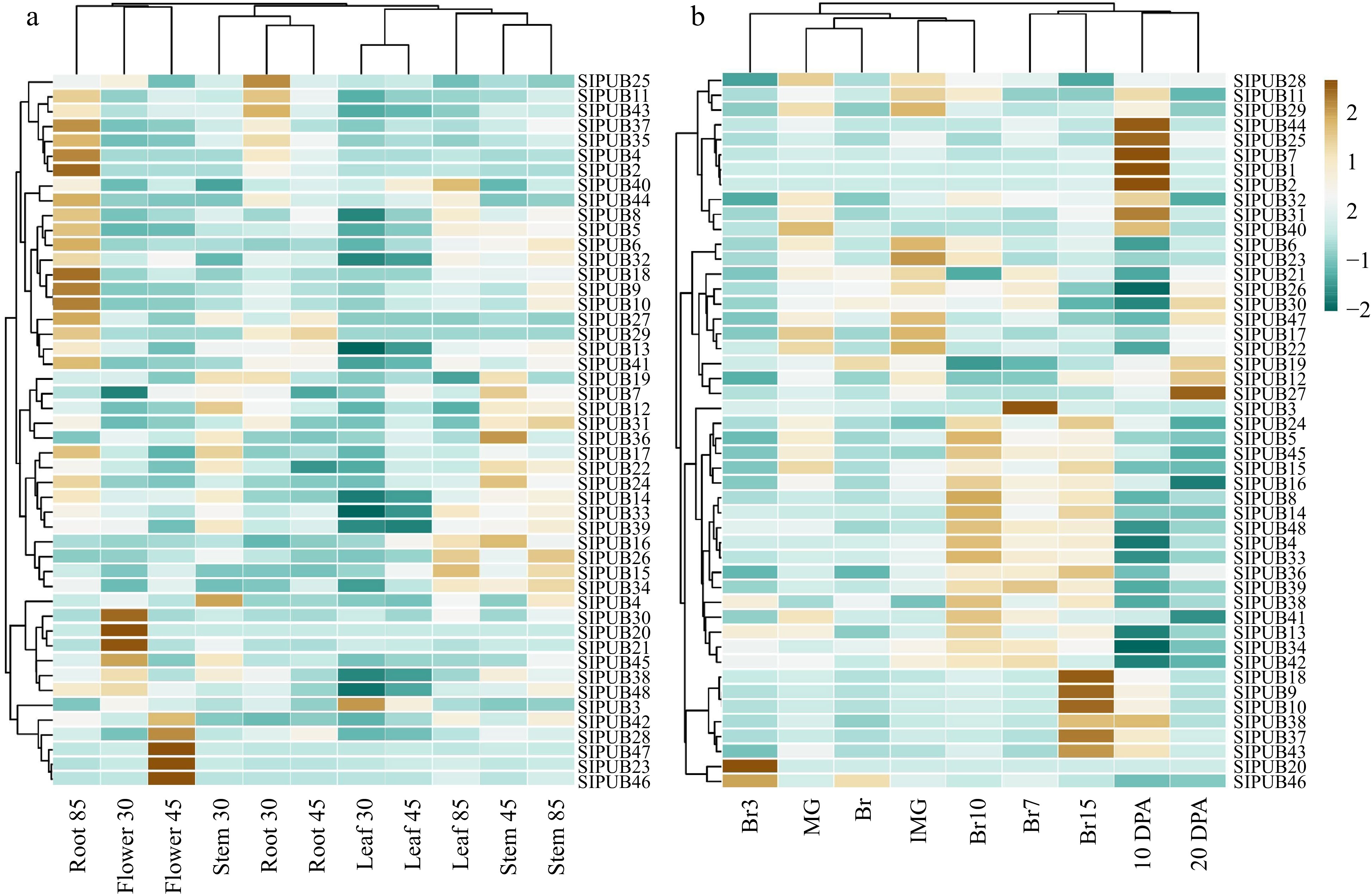
Figure 4.
Expression profiling of the 48 differentially expressed genes in multiple tissues based on RPKM values, including (a) Solanum lycopersicum cv. Heinz and (b) the wild relative Solanum pimpinellifolium. The brown bars represent up-regulated genes and dark blue bars represent down regulation.
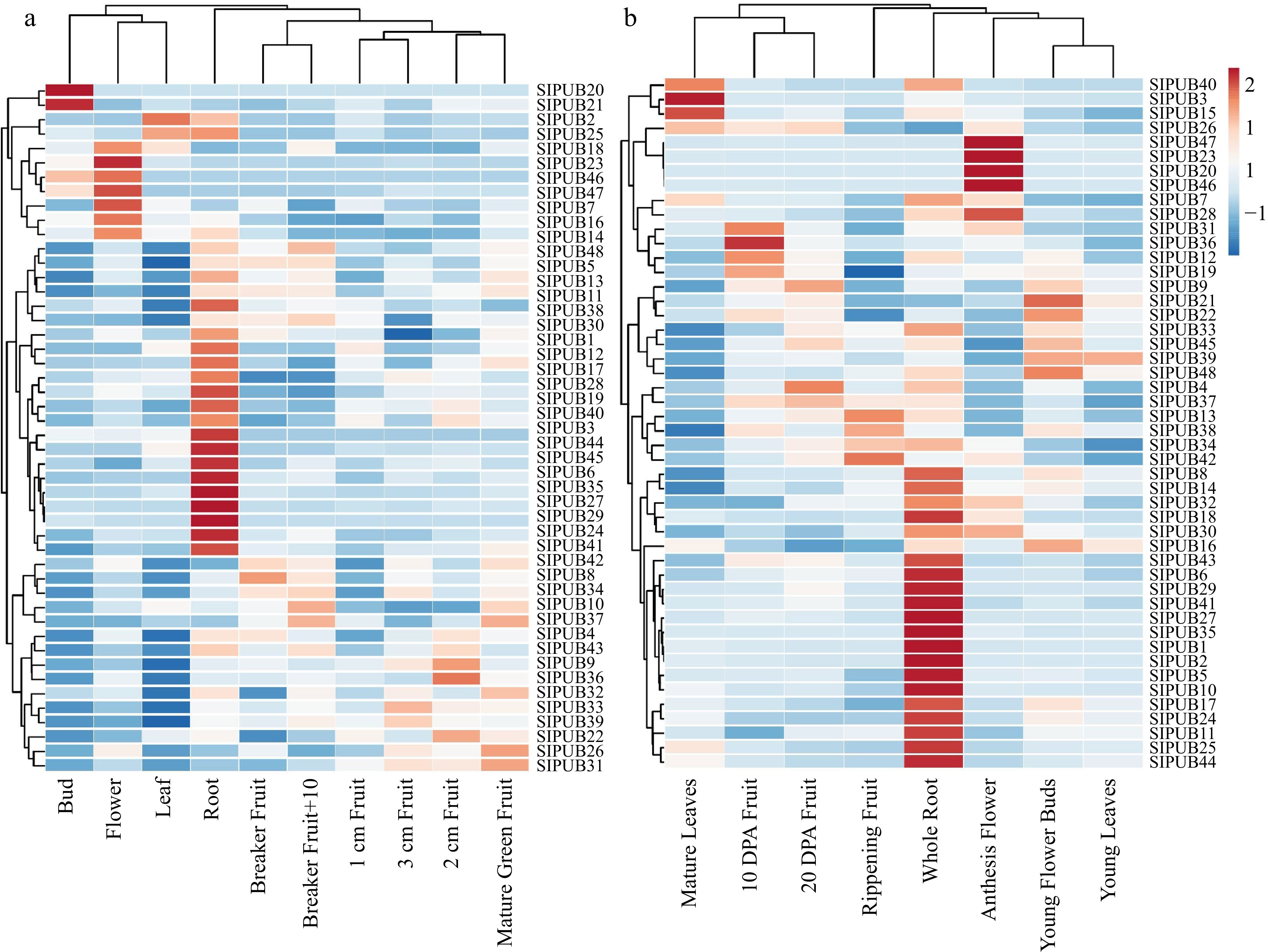
Figure 5.
Expression profiling of the 48 differentially expressed PUB genes from MT data based on RPKM values, including (a) different developmental stages and (b) different organs. Red bars represent up-regulated genes and blue bars represent down-regulation.
qRT-PCR analysis of PUB genes in different tissues, and their response to salt and cold stress
-
The expression profiling of 30 PUB genes was randomly selected and then quantified by qRT-PCR in five different tissues including root, stem, leaf, flower bud, and flower (Fig. 6a). As shown in Fig. 6c, the same genes were tested in response to salt and cold stress, as well as control (CK). In most tissues, the majority of genes were highly expressed, and only a few genes were down-regulated such as SlPUB3, SlPUB23, SlPUB25, and SlPUB47. Similarly, findings showed that most PUB genes expressed distinctly in response to both stresses, implying that these genes can play a variable role in tomato plant resistance. When it came to salt stress, for example, most of the genes were significantly up-regulated, especially SlPUB10, SlPUB33, SlPUB30, SlPUB43, SlPUB5, SlPUB13 and SlPUB31. When compared to low temperature, SlPUB10, SlPUB43, SlPUB13 and SlPUB31 were significantly up-regulated. Several genes, including SlPUB3, SlPUB16, and SlPUB34, were down-regulated in both stress conditions. In response to both treatments, the rest of the genes showed either poor or moderate expression. Additionally, we also performed principal component analysis (PCA) to gain deeper insights into their involvement in different tissues and against abiotic stress. For different tissues, PCA analysis of PUBs transcripts showed 39.37% variation in PC1 and 31.06% variation in PC2, with 67.03% in PC1 accounting for 32.07% of total variation in PC2 for stress conditions (Fig. 6b).
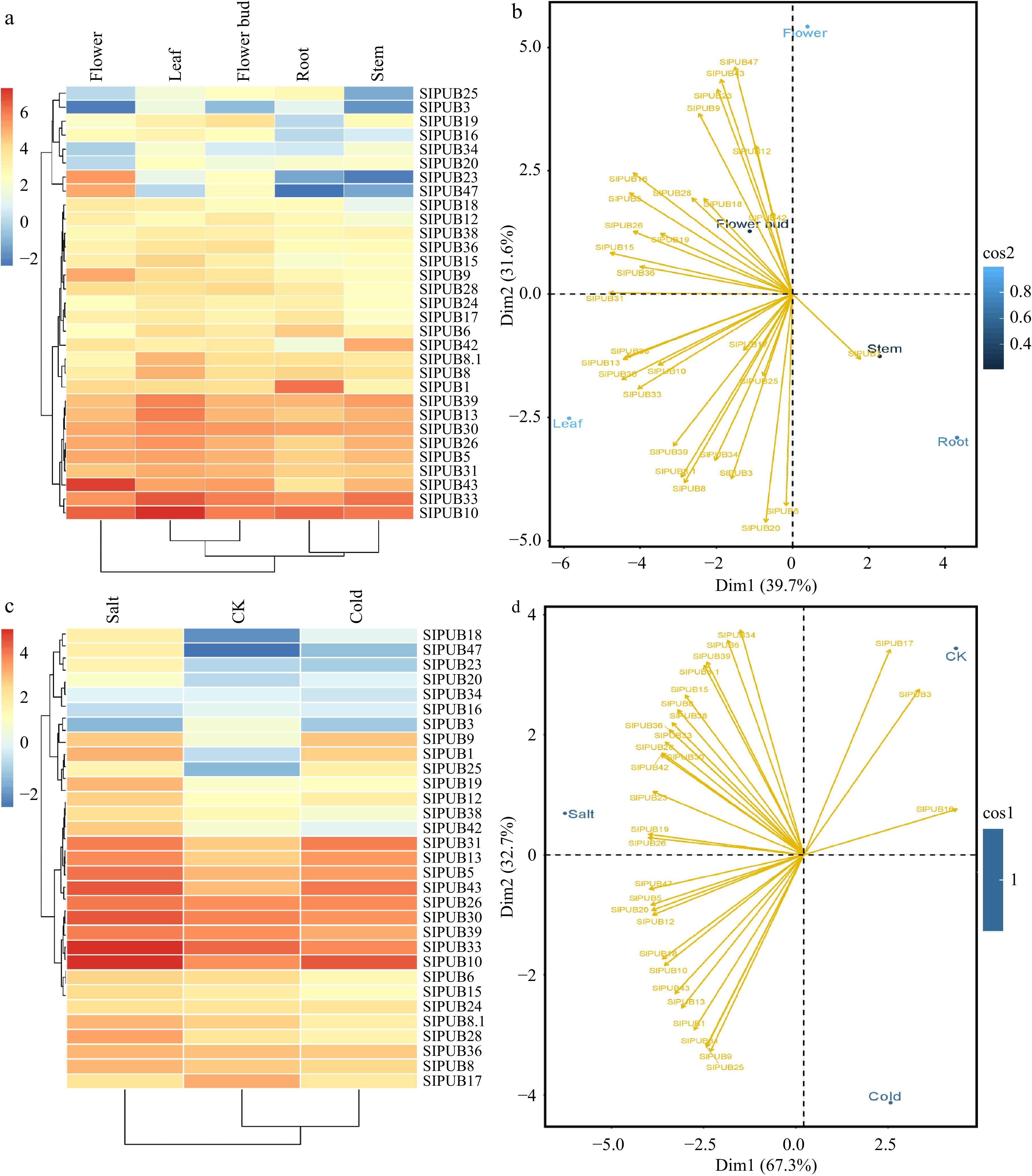
Figure 6.
Relative expressions of SlPUBs (a) and (c) in five different tissues including root, stem, leaf, flower, and flower bud, and two stress conditions i.e., salt (200 mM) and cold stress (4 °C). The principal component analysis for (b) different tissues and (d) stress conditions.
SlPUB10 can effectively regulate tomato's tolerance to low temperature and salt stress
-
Due to the relatively high expression of SlPUB10 in roots and leaves, and the significant increase in expression after low temperature and salt treatment, we conducted further research on this gene. The localization of protoplasts shown that SlPUB10 were expressed in the nucleus and cytoplasm (Fig. 7a). In the leaves of mock-treated plants, there was no genotypic effect on the activity of any of reactive oxygen species (SOD) or Peroxidase (POD) (Fig. 7b). This was not the case when the plants were challenged by salt and cold stress: here, the genotypic ranking for SOD and POD was OX>WT>RNAi when treated by salt or low temperature. In the salinity treatment, the activity of the two enzymes were higher than CK. The determination was consistent with the relative expression of SlPUB10 in transgenic lines and wild-type[24] (Fig. 7c). After salt or cold treatment, the overexpression lines of SlPUB10 did not show any difference from those before treatment, while RNAi lines showed more severe wilting than the WT (Fig. 7d), which suggested that SlPUB10 can enhance the salt tolerance and cold resistance of plants.
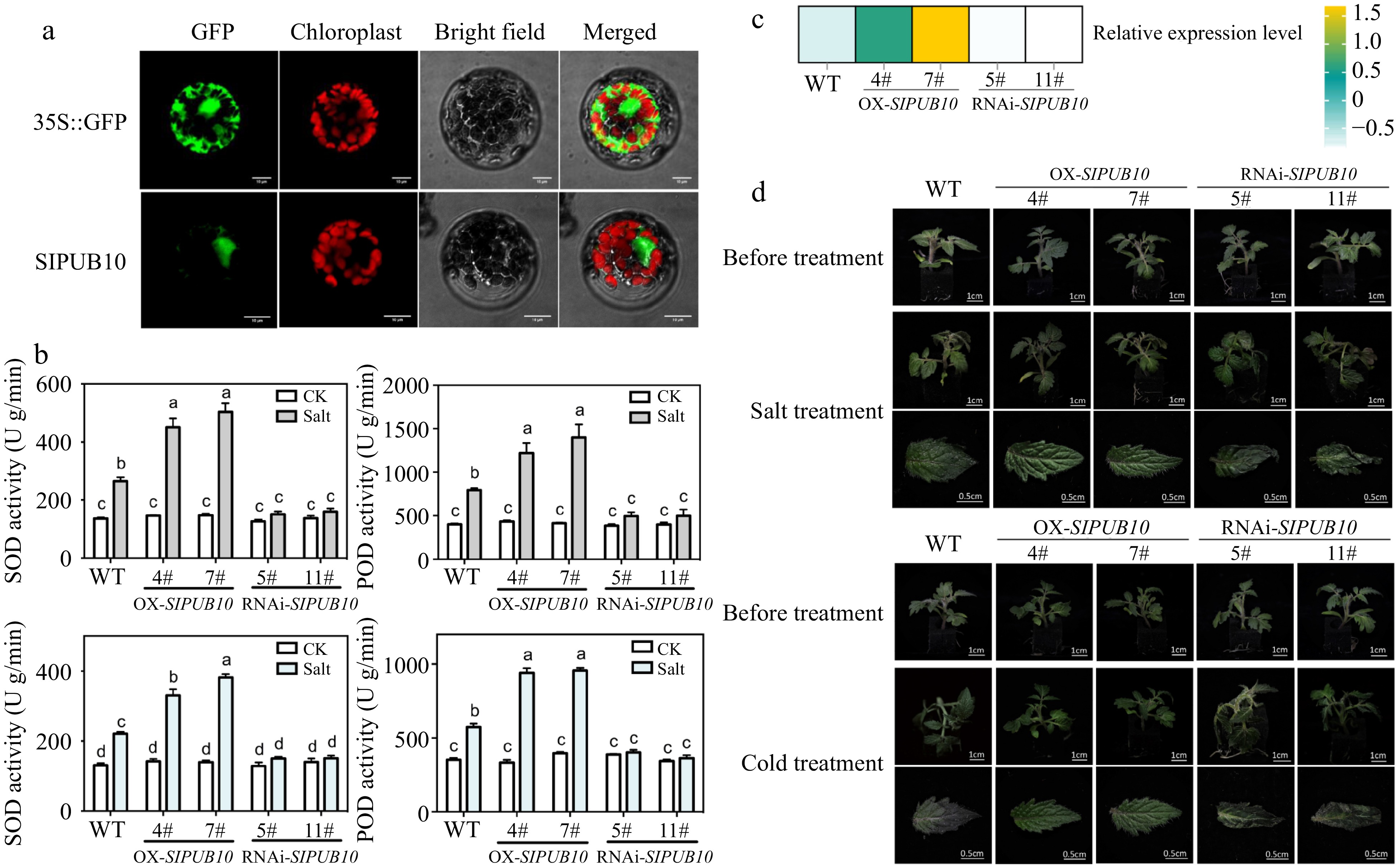
Figure 7.
Gene function verification of SlPUB10. (a) The proteins’ subcellular locazation in Arabidopsis protoplasts. (b) The activity of SOD and POD in leaves of wild-type (WT) and transgenic tomato lines after salt (200 mM NaCl) and cold treatment (4 °C) for 4 h. The P values indicate the results from pairwise comparisons of one-way ANOVA tests. Different letters represent a significant difference at P < 0.05. (c) The relative expression level of SlPUB10 in transgenic lines. (d) Phenotypes of WT and transgenic lines after 48 h of salt (200 mM NaCl) and cold treatment (4 °C).
-
PUB genes have been found in a variety of plants, including 64 in Arabidopsis thaliana, 70 Oryza sativa, 33 Chlamydomonas reinhardtii, 101 Brassica rapa, 125 Glycine mix, and 93, 96, 185, 208, from four different cotton sequenced species including, G. raimondii, G. arboreum, G. hirsutum, and G. barbadense[15−19,35]. However, a comprehensive genome-wide analysis of their identification, expression profiling, gene duplication, and evolutionary analysis is still lacking in tomato. As a result, we used multiple bioinformatics methods to investigate the PUB gene for their physicochemical properties, phylogenetic relationships, gene structure analysis, chromosomal localization, gene duplications, gene collinearity analysis, expression profiling of multiple tissues, stress conditions, and developmental stages. Additionally, we explored the mode and tempo of SlPUB duplicated gene pairs based on their transcriptional profiling to determine their functional evolution.
The comparative phylogenetic analysis between tomato (SlPUB) and Arabidopsis (AtPUB), suggested an almost identical and relatively close genetic relationship. Following the previously reported studies[18,35] on PUB with slight modifications, the PUB genes were divided into seven different groups according to the phylogenetic analysis. PUB genes were found to have high conservation and diversification, according to gene structure analysis based on coding and protein sequences. For instance, several motifs were widely scattered, but motifs 1 and 4 were strongly conserved almost across all PUB members, implying their common evolution, whereas the rest of the PUB members suggested slight structural diversification among SlPUBs. While the gene structure analysis revealed nearly identical patterns with motif composition, two members, SlPUB8 and SlPUB9, showed contrasting results. These findings indicated that most PUBs had similar characteristics and only small variations in their origins of functions as they evolved. During the process of evolution, structural diversification is vital for their important role in the multi-gene family[36].
Due to gene duplications, genomic evolution and functional importance are likely to be the most popular ingredients of variations[37]. The observed special genomic functions and evolutionary innovation are also due to gene duplications[38,39]. In this study, we discovered three forms of PUB gene duplication in the tomato genome: 26 dispersed, 19 WGD, and three tandem. Two types of duplication events, segmental and tandem, are the most important contributors to gene family expansion during evolution[40,41]. Our findings showed, however, that both dispersed and WGD greatly enhanced and extended the PUB gene family in tomato. We also measured the rate of synonymous to non-synonymous mutation among the three forms of gene duplications, namely dispersed, tandem, and WGD, in light of the significance of gene duplication. It is a well-known fact that genes are typically associated with various types of selection pressure including purifying selection (Ka/Ks < 1), positive selection (Ka/Ks > 1), and neutral selection (Ka/Ks = 1)[32]. In our study, we make 23 pairs of possible combinations for Ka/Ks calculation based on their duplication types i.e., 13 pairs of dispersed, one tandem, and nine pairs of WGD. We discovered that 20 pairs of duplications from various types had a Ka/Ks ratio of less than 1.00, indicating purifying selection and reduced divergence after gene duplications. Just three scattered gene pairs, SlPUB16-SlPUB22, SlPUB30-SlPUB32, and SlPUB36-SlPUB37, had Ka/Ks standards greater than 1.00, indicating positive selection.
The angiosperm evolution is generally governed by several events such as polyploidization through the process of whole-genome duplication, followed by diploidization, which is mostly associated with considerable gene loss[42]. Several polyploidy events in flowering plants have been identified so far in different flowering plant lineages. After the event of polyploidy, the gene duplication mainly experiences several fates over the process of evolutionary time. For example, most likely the gene loss among the pairs of paralogous or become pseudogene[43]. However, the gene duplication pairs can survive for many years through the process of natural selection and numerous functional importance[44,45]. A category of gene products that include several factors like, transcription, ribosomal protein, or protein kinases are specifically reserved[46,47]. For example, the interaction of genes with one of the others in the group tends to be highly retained due to gene dosage hypothesis[48]. In summary, the gene duplication tends to undergo several evolutionary fates i.e., functional conservation, sub-functionalization, neo-functionalization, or pseudogenization[43]. To determine the functional evolution of SlPUB duplicated gene pairs, we explored its different modes based on gene transcriptional analysis that are generally used for predicting the diverse fates. Thus, we took a major benefit from the two RNA-seq datasets by calculating the Pearson correlation coefficient (r) analysis of the same duplicated gene pairs which were used for Ka/Ks ratio, across various tissues. Thus, based on predicted expression analysis of the PUB genes in tomato after the process of gene duplication might be likely involved in functional or sub-functionalization conservation (Dataset 5). In short, the possible predicted functions of PUB genes in tomato were largely enhanced and expanded through the experience of gene duplications. However, further functional validation is required to determine the fates of gene pairs either through the consequences of structural variation or epigenetic modification.
Gene expression profiling is useful to the approach for predicting its gene functions. In this work, we have utilized the three major datasets of Illumina RNA-seq dataset of various multiple tissues from cultivated tomato (Solanum lycopersicum cv. Heinz), the wild relative Solanum pimpinellifolium[33,34] and MT. Both Heinz and our MT data showed an almost identical expression pattern and slight inconsistency with it wild relative such as, SlPUB4-SlPUB19, SlPUB22, SlPUB24, SlPUB26, SlPUB28, SlPUB30-SlPUB39, SlPUB41-43, SlPUB47, and SlPUB48 significantly expressed in both. While, the wild relative showed that SlPUB4-SlPUB17, SlPUB19, SlPUB22, SlPUB24, SlPUB26, SlPUB28, SlPUB30-SlPUB34, SlPUB36-SlPUB39, SlPUB41-43, SlPUB47, and SlPUB48 displayed high expression among all tissues, involving their foremost contribution in tomato growth and developmental based on their high tissue-specific response. The remaining PUB genes displayed a very modest or weak transcriptional response among the different tissues and organs used in our study, which further suggested their slightly restricted role in tomato development. Further, the RT-PCR analysis of 30 PUB genes in five different tissues and their response to salt and low temperature was performed. These results showed most of the genes were significantly up-regulated in the majority of the tissues, and response to salt stress when compared to low temperature. Thus, these analyses supporting the hypothesis that PUB genes play a vital role in tissue-specific patterns and various environmental stimuli. While, together with the multiple tissue-specific patterns and abiotic stresses, these analyses provided basic resources for the examination of tomato development and stress resistance.
In summary, 48 PUB genes were comprehensively discovered and presented in the tomato genome. Based on evolutionary phylogenetic relationships and high sequence similarities with Arabidopsis, the PUB genes in tomato were classified into seven groups. Gene duplication analysis suggested that the PUB gene family in tomato were mainly expanded as a consequence of dispersed and segmental duplications. The multiple transcriptional profiling of RNA-seq and RT-PCR analyses provided a valuable clue to their tissue-specific abundance, developmental stages and response to salt and low temperature. The expression correlation analysis further suggested that putative neo-functionalization largely was observed among the SlPUB of at least one of the duplicated pairs compared to functional conservation or sub-functionalization. These results will greatly facilitate the critical role of PUB genes in tomato and other crop species. Moreover, SlPUB10 was screened out and verified as a key gene in salt and cold stress response.
-
The PUB genes were identified using the 64 reference sequences of Arabidopsis (TAIR10) against tomato (version 3) genome by BLASTP search at 1E-100 with the help of BioEdit tools. Both of their genomes sequences were retrieved from online sources such as phytozome (version 12.1) (
https://phytozome.jgi.doe.gov/pz/portal.html )[49] and the Arabidopsis information resource TAIR (www.arabidopsis.org )[50]. Domain analysis for each of SlPUB was further examined by two major servers such as the NCBI-Conserved Domain (version 3.18) (www.ncbi.nlm.nih.gov/Structure/cdd/wrpsb.cgi )[35] and SMART (version 8.0) (http://smart.embl-heidelberg.de/ )[51]. Those PUB sequences with error either in length (< 100 aa) or absence of their domain were removed before any further analysis.Phylogenetic analysis of the PUB gene family
-
Phylogenetic analysis was performed with the help of Molecular Evolutionary Genetics Analysis (MEGA: version 7.0)[52], firstly the multiple sequences alignment (MSA) of PUB genes for both tomato and Arabidopsis genome was implemented by MUSCLE[53] in MEGA. Several models were tested before proceeding with the neighbor-joining tree with the help of Jones, Taylor, and Thornton amino acid substitution model (JTT model), and keeping 1,000 replication as bootstrap. These 1,000 replications were tested only to satisfy the consistency of the phylogenetic analysis, and other parameters in MEGA were set as the default option.
Synonymous (Ks) and non-synonymous (Ka) for duplicated pairs of PUB genes
-
Synonymous with non-synonymous (Ka/Ks) mutation analysis was performed for different types of duplicated PUB gene pairs identified in tomato with the help of MEGA [52]. These ratios from synonymous with non-synonymous were also calculated by using the MEGA and the Nei-Gojobori method (Juke-Cantor) model was tested by performing 1,000 bootstrap replications.
Gene structure, motif composition, and physicochemical analysis of PUB protein
-
A generic file format (GFF3) was download from the tomato genome, and then gene structure analysis was performed by using TBtools software[54]. Similarly, the motif composition of PUB proteins was carried out by using the MEME suite: version 5.1.1. The following parameter was set-up: the number of motifs 10 and width ranged from 50−100 while keeping the other parameter as the default option[55]. Both the GFF3 and XML file were utilized for gene structure visualization with the help of TBtools software[54], and the XML was downloaded from the MEME server.
Further, the ExPASY PROTPARAM server (
http://web.expasy.org/protparam/ ) was utilized aimed at different sequence properties of each PUB gene in tomato including, molecular weight (MW), isoelectronic points (PIs), and GRAVY). Subcellular prediction analysis was performed with the help of the WOLF PSORT online resource (https://wolfpsort.hgc.jp/ ).Gene collinearity and duplication analysis of PUB genes in tomato
-
Tomato genomic resources were downloaded from Phytozome as discussed above, both gene collinearity and duplication analysis were carried out by utilizing the tomato genomic sequences, protein sequences, and GFF3. These genomic resources were utilized with the help of TBtools software[54], and the collinearity analysis was demonstrated with the help of Circos.
Tissue-specific transcriptional profiling of the PUB gene family in tomato
-
The tissue-specific transcriptional profiling of SlPUB genes in numerous tissues was utilized by two major publically available RNA-seq datasets, these resources were utilized from the Tomato Functional Genomics Database (TFGD,
http://ted.bti.cornell.edu/cgi-bin/TFGD/digital/home.cgi ). The two Illumina RNA-seq datasets based on several multiple tissues were used from cultivated tomato (Solanum lycopersicum cv. Heinz) and the wild relative Solanum pimpinellifolium[33,34]. The data from the RNA-seq data of the model variety Micro-Tom (MT) was also utilized for four different tissues at various stages such as root 30, 45, and 85 d post germination (DPG), stem 30, 45, and 85 DPG, leaf 30, 45, and 85 DPG, and flower 30 and 45 DPG. 10 DPA (55 DPG), 20 DPA (65 DPG), immature green (IMG) at 75 DPG, mature green (MG) at 80 DPG, Br (85 DPG), Br3 (88 DPG), Br7 (92 DPG), Br10 (95 DPG) and Br15 (100 DPG)[56]. The ten tissues from the cultivated tomato include bud, flower, leaf, roots, 1 cm, 2 cm, 3 cm, mature green, breaker, and breaker + 10 fruits. While the data from the wild relative, eight different tissues and organs were used, which included anthesis flower (0 DPA), 10 d post-anthesis (DPA) fruit, 20 DPA fruit, ripening fruit (33 DPA), mature leaves (ML), whole root (WR), young flower buds (YFB), and young leaves[30], were selected for analysis. Heat maps were generated based on RPKM values by using the following method: bidirectional cluster analysis, and maximum distance with complete linkage method using the ClustVis[57]. Pearson correlation coefficient (r) analysis was performed on three different RNA-seq datasets of various tissues among the duplicated pairs of PUB genes using Rstudio (Version 3.5.2).Plant material and RT-PCR analysis
-
The experiments were carried out on the Micro-Tom cultivar, which was grown in a 1:1 mixture of garden soil and vermiculite under a 16 h photoperiod (day/night temperature regime of 23 °C/18 °C, relative humidity of 70%). The plants were irrigated with 3 mL/cm3 soil of either 200 mM NaCl or placed in an incubator at 4 °C once they had grown seven to eight completely expanded leaves. Different tissues were sampled and used for RT-PCR quantification, including roots, stems, leaves, flower buds, and flowers in full bloom.
Total RNA was extracted, using the TRIzol reagent (Invitrogen, Carlsbad, CA, USA) from five different tissues and the leaves with the same pitch position from plants exposed to salinity stress for 6 h, or low temperature treatment for 2 h were used. A 1 μg aliquot of RNA was used for the synthesis of the cDNA first strand, using a PrimeScriptTMRT reagent kit containing gDNA Eraser (Takara, Shiga, Japan). The cDNA was used as the template for qRT-PCRs based on Fast SYBR Green Master Mix (www.bimake.com). The reference sequence was the SlUBI8 gene, and relative transcript abundances were calculated using the 2−ΔΔCᴛ method[58] and heatmap of fold changes was plotted on a log2 scale. Rstudio (Version 3.5.2) was used to construct a heatmap and Pearson component analysis (PCA) analysis and the set of RT-PCR primer sequences used in this study is listed in Dataset 6.
Subcellular localization
-
The full-length coding region without the termination codon was fused with 35S::GFP. It was then transformed into protoplasts of Arabidopsis after incubation for 14 h at 28 °C. A confocal laser scanning microscope was used for GFP fluorescence detecting.
Determination of antioxidant enzyme activity
-
Antioxidation enzyme activities were measured in the fifth or sixth fully expanded leaf (counting from the apex). A ~1 g sample of leaf was equilibrated in 10 mL 10 mM phosphate buffer (pH 7.8) for 40 min. SOD activity was measured as follows: the assay comprised a 100 μL aliquot of the enzymatic extract, to which was added 30 μM EDTA-Na2, 60 μM riboflavin and 2.25 mM nitroblue tetrazolium; the reaction was exposed to 4,000 lx fluorescent light for 20 min and then its absorbance was measured at 560 nm. For the estimation of POD activity, the reaction mixture comprised a 100 μL aliquot of the enzymatic extract, containing 25 mM phosphate buffer (pH 7.8), 0.05% w/v guaiacol and 10 mM H2O2. The absorbance of the reaction was measured at 470 nm.
-
Herein, we identified 48 PUB genes in the tomato genome that were further characterized into seven different groups based on their phylogenetic analysis. We carried out a thorough genome-wide investigation search of the tomato genome for PUB genes identification by several bioinformatics tools, such as the physicochemical properties, gene structure, and motif composition, gene duplication, gene collinearity analysis, evolutionary rates, expression profiling, and functional evolution. Gene duplication analysis proposed mainly three different types among PUB genes i.e., segmental, tandem, and dispersed. Among these duplications notably, the dispersed genes contributed most to the expansion of PUB in tomato. The transcriptional analysis demonstrated significant changes specifically their likely diversification and fates of duplicated gene pairs during the process of evolution. The common fates among these genes were predicted to be involved during their functional or subfunctional conservation and neo-functionalization. These analyses, based on the PUB gene family, lay a solid basis for future investigation and their functional characterization in tomato.
This study was financially supported by grants from the Agricultural Science and Technology Innovation Program (34-IUA-03), the Central Public-interest Scientific Institution Basal Research Fund (S2022001), the National Natural Science Foundation of China (32200260), China Postdoctoral Science Foundation Funded Project (2020M673207), and the Fundamental Research Funds for the Central Universities (2020SCU12061).
-
The authors declare that they have no conflict of interest.
-
# These authors contributed equally: Gaofeng Liu, Qian Hu
- Supplemental Fig. S1 The LOGOS of PUB genes were also elucidated by MEME online server and were visualized through TB tools software.
- Dataset 1
- Dataset 1 The basic information of PUB genes identified in tomato.
- Dataset 2 The RPKM based values of different tissue of PUB genes for Heinz.
- Dataset 2
- Dataset 3 The RPKM based values of stages and developmental organs of PUB genes from MT data.
- 3
- Dataset 4 The RPKM based values of different tissue of PUB genes for wild relative.
- Dataset 4
- Dataset 5 Pearson correlation coefficients of duplicated gene pairs and their functional evolution.
- Dataset 5
- Dataset 6 Gene specic primers for RT-PCR analyses.
- Dataset 6
- Copyright: © 2023 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Liu G, Hu Q, Zhang J, Li E, Yang X, et al. 2023. Genome-wide identification of the plant U-box (PUB) gene family and their global expression analysis in tomato (Solanum lycopersicum). Vegetable Research 3:16 doi: 10.48130/VR-2023-0016 

Genome-wide identification of the plant U-box (PUB) gene family and their global expression analysis in tomato (Solanum lycopersicum)
- Received: 28 November 2022
- Accepted: 13 March 2023
- Published online: 16 May 2023
Abstract: Plant ubiquitination plays an important role in protein post-translational changes that occur in a wide variety of eukaryotic organisms and regulate a broad range of biological processes. However, little is known about the evolutionary relationships, gene duplication, and functional evolution of PUB genes in tomato. Herein, we explored 48 PUB genes in the tomato genome which were further classified into seven major groups based on their sequences and relative genetic similarities with Arabidopsis. Gene structure analysis suggested that most of the PUBs carry similar features and with slight differentiation in their sources of functions during the process of evolution. Collinear analysis showed a high degree of conservation among SlPUBs, with a total of ten pairs identified as collinear with potential interactions with each other and another family. Based on their duplication forms, a total of 23 pairs were chosen for Ka/Ks calculation: 13 pairs of dispersed, one tandem, and nine pairs of WGD or segmental. The majority of the gene pairs from the three forms of duplication had a Ka/Ks ratio of less than 1.00, indicating purifying selection and reduced divergence after duplication. Only three pairs i.e., SlPUB16-SlPUB22, SlPUB30-SlPUB32, and SlPUB36-SlPUB37 were perceived by higher than 1.00 values, signifying positive selection. In addition, three major RNA-seq datasets analyses from the cultivated and its relatives, as well as Micro-Tom (MT), revealed their highly tissue-specific role, with the expression correlation analysis of duplicated pairs indicating highly putative neo-functionalization as compared to functional conservation or sub-functionalization after duplication. SlPUB10 was screened out and preliminary verified as a key gene in salt and cold stress response with validation of transgenic strains. These results are indicative of their response during the gene duplication and evolution process, while further functional validation step is required to determine their specific role.
{kind=link}