









-
Incident Commanders (ICs) are required to make decisions under time constraints during extreme conditions on the fireground. The decision-making processes, or the 'size-up' processes, require the ICs to collect information rapidly about the current resources and personnel at the scene of a fire. This research is designed to provide the firefighting ICs with enhanced access, and a better grasp of the up-to-date information of resources and personnel on-site, to consequently help them make more effective decisions on the fireground.
The researchers will discuss how to train Artificial Intelligence (AI) object detectors to calculate the fire apparatus and firefighters on the ground. Firefighters have recently started utilizing various new technological devices (e.g., drones) to capture real-time images and videos for firefighting purposes[1,2]. With these images and videos, deep learning image analyses, which are able to extract high-level features from the raw images, have been successfully applied to solve various environmental health issues[3]. Given the early studies in this field, the mechanisms of these technologies are not well understood. As such, early research in the field indicates optimism that we believe these technologies can be widely adopted by fire departments.
To advance this literature, we train an AI object detector to automatically calculate fire trucks and firefighters at the scene of a fire with the use of image resources from Google Images and a local fire department. We then compare the AI performances by utilizing the two resources. First, the system facilitates the collection and use of information to improve situational awareness at the scene of a fire. Second, by calculating the available resources and personnel, responders will no longer need to walk across an active scene of a fire to locate resources. Therefore, the technology considerably reduces the risk of lives of firefighters performing practical and expected activities on the fireground. Finally, by calculating the number of firefighters using the trained object detection model and by comparing images taken at different response periods, the ICs will have the ability to conduct an accountability system on a broad area. The system can calculate the number of firefighters at the scene every couple of seconds and automatically warn the ICs if fewer firefighters are found. Consequently, this research can assist the ICs in tracking every firefighter on location and immediately identify those responders who may need to be rescued which helps mitigate some of the safety and health hazards associated with firefighting.
Current advances
-
Firefighting is an activity that relies heavily on teamwork. As a result, leaders in fire departments are required to quickly grasp environmental information, make decisions based on the environmental changes, and eventually orchestrate the on-site firefighting activities. The above processes are called 'size-up' for fire officers, which includes obtaining critical information, such as construction, life hazard, water supply, apparatus, and workforce on-site[4,5].
To fight fires, the ICs must consider the fuel, topography, road access, structural exposure, water supplies, and the number and types of suppression resources dispatched[6]. Since fire departments normally respond to fires that impact a broad area – many of which typically spread quickly and last for a prolonged period of time – the ICs are expected to make decisions based on safety, speed, and suppression[7]. Safety aims to prevent possible harm to firefighters by tracking their locations and then directing them to safe places. Speed refers to realizing the situational awareness cues (such as weather, risks to life, resources, and so on) to make sound and timely decisions[8]. Suppression means formulating technical decisions to suppress a fire by establishing how many firefighters are required and what resources are available at the scene of the fire.
These situational conditions demonstrate that a real-time firefighting resource and personnel management system is imperative for fire decision-makers. With enhanced awareness of suppression resources on the sites, the ICs would have to contend with fewer uncertainties in their decision-making process at the fireground. Moreover, the improved aggregate of information provides an easier path to implement preferred suppression strategies in conditions that require consideration of multiple decision factors[9−11]. As a result, the objective of this research project is to assist IC's abilities to improve the management of on-site fire apparatus and firefighters. To reach this objective, we incorporate an AI object detection model to facilitate the fire incident command and firefighter accountability.
Convolutional Neural Networks (CNN) have been applied successfully in many areas, especially in object detection[12−15]. Over the last few decades, the deep neural network has become one of the most powerful tools for solving machine learning problems. CNN has become one of the most popular deep neural networks due to its ground breaking results compared to others. CNN can reduce the number of parameters to solve complex tasks, and obtain abstract features in deeper layers from the raw images. One popular state-of-the-art CNN-based model for detecting objects in an image is 'You Only Look Once' or YOLO proposed by Redmon et al.[16]. YOLO version 3 (YOLOv3) expands on its previous version, YOLO version 2 (YOLOv2), by utilizing a Darknet-53 (a CNN algorithm with 53 convolutional layers) as its backbone compared to its previous version that utilized Darknet-19 (19 convolutional layers)[17,18]. Depending on the architecture, a CNN model contains multiple convolutional layers, where we apply multiple filters to extract features from images. Although the precision has been greatly improved in YOLOv3 compared to YOLOv2 due to the added convolutional layers, these additional layers also make it slow. YOLO version 4 (YOLOv4) has been developed to improve both the precision and speed of YOLOv3, and it is considered one of the most accurate real-time (23−38 frames per second) neural network detectors to date[19]. YOLOv4 has been successfully applied in various industries after it was published in 2020, including autonomous driving vehicles, agriculture, electronics and public health[20−24]. Due to its efficiency and power, everyone can use a 1080 Ti or higher Graphics Processing Unit GPU to train a fast and accurate object detector. In addition, YOLOv4 is an open-source code, which presents an opportunity to create a readily accessible application for personal computers, smartphones and tablets. Various image resources are available for training AI software; however, they might not be suitable for characterizing the local features.
Therefore, the researchers utilize the YOLOv4 to recognize and count on-site fire trucks and firefighters, and to differentiate the firefighters from non-firefighters. We tested two visual datasets used for training the model, including: (1) images downloaded from Google Images; and (2) images obtained from a local fire department in Taiwan. Then, we discussed the potential of using an AI object detection model to improve on-site IC and personal accountability
-
We compared the YOLOv4 performance at the threshold value (or probability of detection) of 0.5 (@0.5) using the two visual datasets. The results for testing images showed that the mean average precision (mAP) @0.5 using the visual dataset 2 from on-site images from a local fire department in Taiwan achieved 91%, which is much higher than the mAP@0.5 of 27% using the visual dataset 1 from Google Images. The four model evaluation metrics (Accuracy, precision, recall, and F1-score) are summarized in Table 1. For both training and testing datasets, the model performances using visual dataset 2 were much higher than using visual dataset 1.
Table 1. Comparison of model performances using the two datasets.
Training Testing Visual
dataset 1
(Internet)Visual
dataset 2
(Taiwan onsite)Visual
dataset 1
(Internet)Visual
dataset 2
(Taiwan onsite)Accuracy 0.78 0.96 0.37 0.71 Precision 0.77 0.97 0.51 0.83 Recall 0.83 0.97 0.38 0.77 F1-score 0.80 0.97 0.44 0.80 We compared the average precision for each class using the two datasets as shown in Table 2. The results show that using the on-site images from the local Taiwan fire department could better differentiate the firefighters from non-firefighters, indicating that using the local fireground images was preferable in order to capture local features.
Table 2. Comparison of the average precision for each class using the two datasets.
Training Testing Visual
dataset 1
(Internet)Visual
dataset 2
(Taiwan on-site)Visual
dataset 1
(Internet)Visual
dataset 2
(Taiwan on-site)Firefighter 0.88 0.99 0.40 0.75 Non-firefighter 0.73 0.98 0.07 0.98 Firetruck 0.57 1.00 0.35 1.00 -
Based on the previous results, we found that using a well-trained AI object detection model can accurately identify and count the number of firefighters and fire apparatus numbers at the location of a fire. In Fig. 1, we brainstormed the possible future fire safety management practice procedures using AI. When fire companies initially arrive at the scene of a fire, the cameras begin capturing images/videos and then transfer them to Cloud servers at an off-site location. The cameras can be installed on drones, vehicles, and firefighters. Then, the on-site images/videos are sent to trained AI models and the visual database from the Cloud. Finally, ICs on-site receive needed decision-making information, including the number of fire trucks, number of firefighters, other objectives, and number of hazardous activities. As a result, we proposed three possible applications of this research in the future.
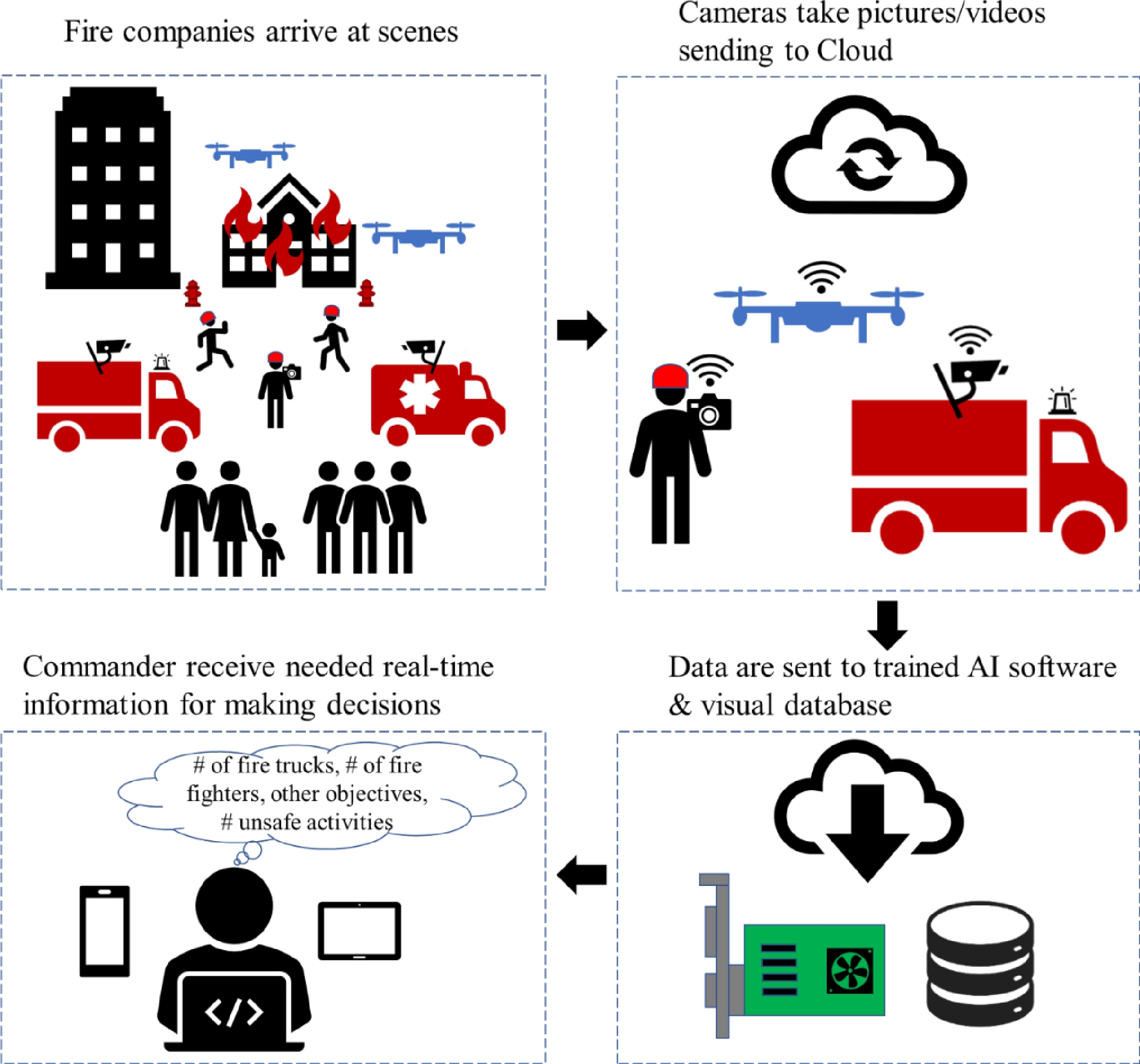
Figure 1.
Brainstorm of the procedures of fire safety management practices using AI.
Firstly, this research would increase situational awareness on the ground. If researchers train the AI to recognize additional objects, for example, such as different types of vehicles, fire hydrants on the streets, and specific uniforms worn by firefighters, Emergency Medical Technicians, and police officers, the fire commanders could quickly and precisely grasp the critical information (e.g., number of fire apparatus) on-site.
Also, by connecting cameras to wireless or satellite networks, the system with an AI object detection model incorporated in this article will be able to continuously calculate and compare the number of firefighters and fire apparatus on the ground. This method can be applied to maintain the fireground personnel's accountability in a continuous protocol. Once a firefighter is no longer recognized at the scene, the IC can contact the individual for the first time to determine if they need to send additional personnel to search and rescue the firefighter.
Last but not least, by continuously monitoring firefighting activities, the software will be able to identify dangerous activities on-site in real-time. As previously mentioned, AI-powered image recognition has been applied to improve occupational safety in different fields (e.g., building construction). When additional training images and/or videos are added to the datasets, AI will be able to identify those signs of fatigue from firefighters. For instance, firefighters’ helmets touching the ground is a clear sign of fatigue, and the AI software will identify the activity and immediately notify other firefighters on the ground.
-
This pilot study successfully utilized images of firegrounds for training an AI model to count the number of firefighters, non-firefighters, and firetrucks in real-time. As firefighters lost on the ground is one of the major causes of American firefighter fatalities, fire departments can apply this research to improve the fireground personnel safety in their jurisdictions.
Moreover, the results showed that the trained AI object detector using images obtained from a local fire department performed better than those downloaded from Google Images. Therefore, when applying this research to local fire departments, we recommend that fire departments establish their image database, with local firefighter and fire apparatus images to improve the AI model performances tailored to fit regional characteristics.
Finally, we encourage researchers to focus on those practical implications we proposed in this article. With broader and more advanced AI applications developed, firefighting communities can use this technology to increase situational awareness, personnel accountability, and incident command on the ground.
-
Figure 2 summarizes the flowchart of this study. We explored two methods of collecting images for training the model: (1) downloading images from online sources; and (2) obtaining images from the scenes of fires. Deng et al. showed that, with a clean (clean annotations) set of full-resolution (minimum of 400 × 350 pixel resolution) images, object recognition can be more accurate, especially by exploiting more feature-level information[25]. Therefore, we downloaded full-resolution images from Google Images by searching firefighters and fire trucks. We used only those images without copyright in this study. In total, 612 images were obtained from online sources for the first visual dataset. Moreover, we obtained on-site images from fire events in Taiwan. A total of 152 images were obtained for the second visual dataset. After collecting the images, we annotated each image by three classes: firefighters, non-firefighters, and fire trucks. Then, the annotated images were used for training the YOLOv4 model for detection, and each visual dataset was done separately. YOLOv4 was compiled in Microsoft Visual Studio 2019 to run on Windows Operating System with GPU (GeForce GTX 1660 Ti with 16 GB-VRAM), CUDNN_HALF, and OpenCV. Finally, we compared the model performances using the two visual datasets and discussed the implications of this study. For each dataset, the images were partitioned into training and testing sets, with an 80%−20% split.
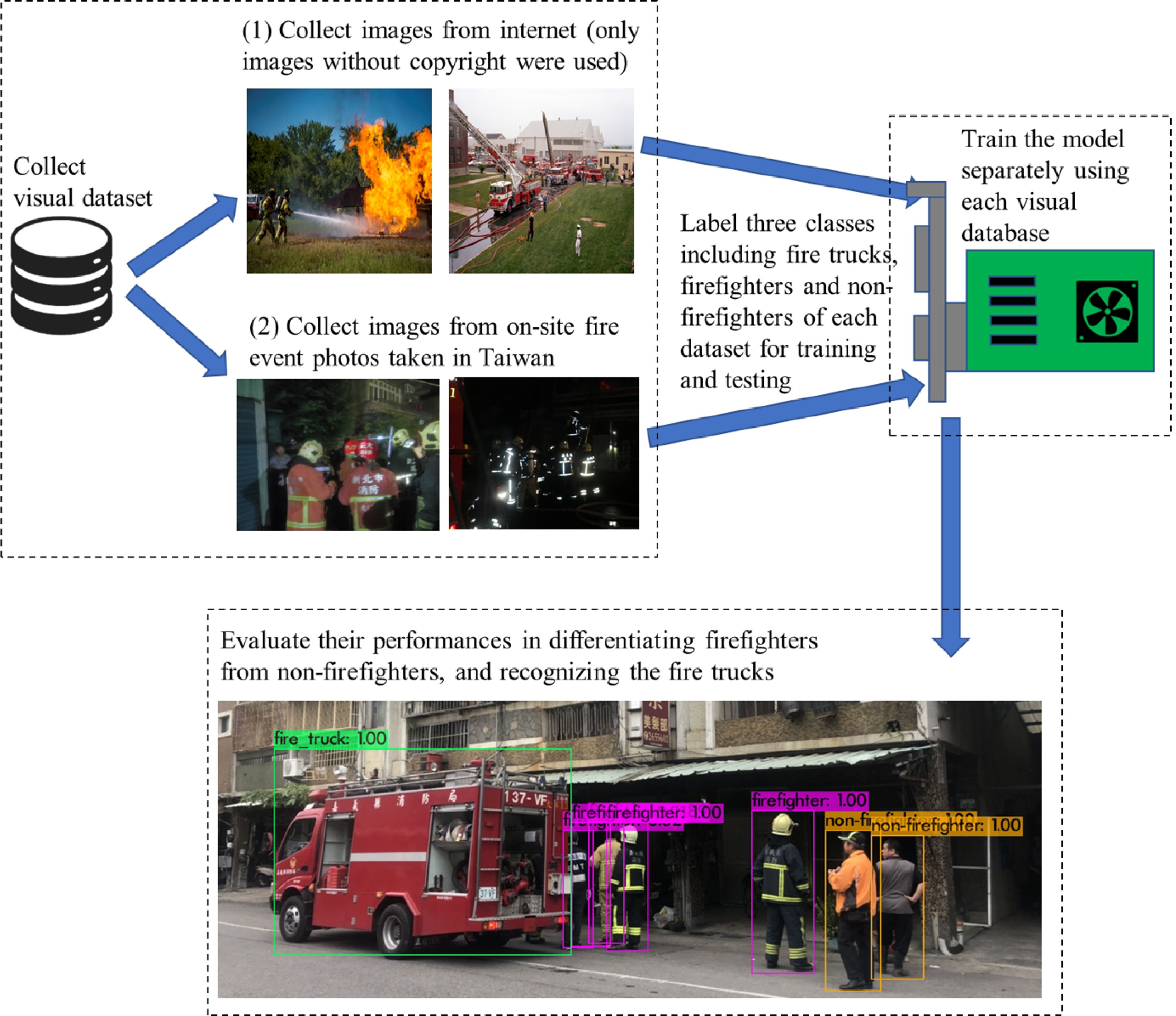
Figure 2.
Flowchart of the study.
YOLOv4 network architecture and model performance evaluation metrics
-
YOLOv4 consists of three main blocks, including the 'backbone', 'neck', and 'head'[19]. The model implements the Cross Stage Partial Network (CSPNet) backbone method to extract features[26], where there are 53 convolutional layers for accurate image classification, also known as CSPDarknet53. CSPDarknet53 can largely reduce the complexity of the target problem while still maintaining accuracy. The 'neck' is a layer between the 'backbone' and 'head', acting as feature aggregation. YOLOv4 uses the Path Aggregation Network (PANet)[27] and Spatial Pyramid Pooling (SPP) to set apart the important features obtained from the 'backbone'[28]. The PANet utilizes bottom-up path augmentation to aggregate features for image segmentation. The SPP enables YOLOv4 to take any size of the input image. The 'head' uses dense prediction for anchor-based detection that helps divide the image into multiple cells and inspects each cell to find the probability of having an object using the post-processing techniques[29].
The model performances were analyzed using the four metrics: Accuracy, precision, recall, and F1-score[30]. A confusion matrix for binary classification includes four possible outcomes: true-positive (TP), true-negative (TN), false-positive (FP), and false-negative (FN). TP indicates the number of objects successfully detected by the algorithm. TN indicates the number of non-objects successfully identified as not an object. FP indicates the number of non-objects that are falsely identified as objects. FN indicates the number of objects falsely identified as non-objects. Accuracy represents the overall performance of the model; or the portion of TP and TN over all data points. Precision represents the model’s ability to identify relevant data points or the proportion of data points classified as true, which are actually true. Recall is described as the model’s ability to find all relevant data points. It is the proportion of the total number of correctly identified data points given the overall relevant data points. F1-score is equated by the balance between precision and recall. Maximizing precision often comes at the expense of recall, and vice-versa. Determining the F1-score is useful in this assessment to ensure optimal precision and recall scores. Their calculations are as follows:
$ Accuracy=\frac{TP+TN}{TP+TN+FP+FN} $ $ Precision=\frac{TP}{TP+FP} $ $ Recall=\frac{TP}{TP+FN} $ $ {F}_{1}=\frac{2*Recall*Precision}{Recall+Precision} $ The authors appreciate the financial support provided by the Hudson College of Public Health at The University of Oklahoma Health Sciences Center, and the Presbyterian Health Foundation (PHF, grant number 20000243) for exploring the AI applications.
-
The authors declare that they have no conflict of interest.
- Copyright: © 2022 by the author(s). Published by Maximum Academic Press on behalf of Nanjing Tech University. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Chang RH, Peng YT, Choi S, Cai C. 2022. Applying Artificial Intelligence (AI) to improve fire response activities. Emergency Management Science and Technology 2:7 doi: 10.48130/EMST-2022-0007 

Applying Artificial Intelligence (AI) to improve fire response activities
- Received: 29 January 2022
- Accepted: 21 June 2022
- Published online: 19 July 2022
Abstract: This research discusses how to use a real-time Artificial Intelligence (AI) object detection model to improve on-site incident command and personal accountability in fire response. We utilized images of firegrounds obtained from an online resource and a local fire department to train the AI object detector, YOLOv4. Consequently, the real-time AI object detector can reach more than ninety percent accuracy when counting the number of fire trucks and firefighters on the ground utilizing images from local fire departments. Our initial results indicate AI provides an innovative method to maintain fireground personnel accountability at the scenes of fires. By connecting cameras to additional emergency management equipment (e.g., cameras in fire trucks and ambulances or drones), this research highlights how this technology can be broadly applied to various scenarios of disaster response, thus improving on-site incident fire command and enhancing personnel accountability on the fireground.