










-
Road traffic victims are no trivial matter. Yearly world total road deaths, probably underestimated at about 1.3 million, were still increasing[1], if at a decreasing speed, from 2007 to 2013 as claimed by the World Health Organization[2]. But this global tally, which has grown by 46% over the decades 1990−2010, includes a subset of 18 national series, analysed here over the period 1965−1999, showing instead downward trends in road deaths over the last 45 years, or so. Nonfatal road injuries warranting medical care (about 78.2 million per year globally in 2018 and growing) also reached a maximum in the same year as that of deaths in most of these 18 countries with long-falling road deaths trends. Why all those peaks?
The unexplained 1970−1974 cluster of maxima of victims
-
We wish to ask why, in those 18 OECD countries, yearly road traffic deaths (and often nonfatal injuries as well) reached a national maximum during the 1970−1974 lustrum, and have since all seen downward trends. This clustering of global maxima and turning points, of 12 peaks within 13 months, is unique in the history of national or regional safety performance. If there existed a convincing 'good explanation' of this cluster, forecasts of global fatalities would use it to predict the timing of maxima in other countries, such as Algeria, Brazil, China, India or Nigeria. A 'good idea' would end panic forecasts whereby road deaths will seemingly climb from 9th to 5th rank among causes of fatal world 'diseases' between 2004 and 2030[3]. Analysts would then sensibly forecast the occurrence of maxima for particular countries, which should all eventually peak and turn, as long occurred to others – and not just in the clustered subset of 18.
Ups and downs and the effect of 'our lack of good ideas'
-
This failure to make convincing sense of the evolution and timing of the key road safety indicator, fatalities, in the subset of 18 OECD countries implies that one also fails to understand why a few other countries each saw their own global maximum occur in years other than 1970−1974. By implication, reasonable questions about upward or downward trending road fatality forecasts and outcomes cannot be duly asked, let alone sensibly answered, for any country. This disarray is obvious in the European Union (EU) of 28 countries where, after several years of stagnation and an increase during 2015, the number of deaths from car crashes dropped 2% in 2016, according to figures published in March 2017. For one, EU Transport Commissioner Violeta Bulc seemed relieved when she announced these numbers on 28th March 2017: 'I think the stagnation was mostly because we ran out of good ideas', she said; but a further drop of 2% in 2017 elicited no similar comment in 2018. Evidently, if turning points are unexplained, targets or asymptotes make dubious sense and even downward trends or stagnations are very hard to be made sense of[4], even for a given country with good data, as demonstrated for Denmark[5]. A new 'good idea' is indeed needed.
Answers from models
-
What types of models can then explain global turning points in national series? To this day, certainly not disaggregate models which are still at pains to correctly derive aggregate safety indicators pertaining to any urban, regional or country population for even a single year, to say nothing of a series of years. This is demonstrated in the seminal and most advanced of extant disaggregate safety tools, applied to the Province of Quebec in simulations not of yearly totals but only of their expected variations due to specific safety restrictions or measures[6−8]. The tradition of disaggregate road safety models, founded in splendour by an American statistician[9−12] ignored by all of his successors everywhere (and not just by Canadian road safety economists), has yet to produce meaningful yearly regional aggregates of deaths and injured victims − anywhere.
Economic development proper
-
We must seek answers from aggregate analyses whose less provincial authors tend to recognize the landmark anteriority of Smeed[13,14] and of Smeed & Jeffcoate[15,16] in the history of such models, a recognition strangely missing in say Peltzman[17] or Zlatoper[18]. But the occurrence of peaks destroys Smeed's monotone Motor vehicle availability (N/Pop) model, which is not restored by the substitution of GDP for N or by the addition of variables from the driver/vehicle/way triplet[19,20] unless a turning form is artificially imposed, say on time[21,22] or on GDP itself[23]. Here we impose no turning form at all but simply enrich a basic yearly model explanation of road victims in terms of GDP with a seemingly new naturally turning economic development variable I, Road traffic intensity of GDP, assumed to track Total to Final output ratio changes[24].
-
In the structural model analysis of road accidents, there exists a natural tendency to concentrate on the endless visible interactions among drivers, vehicles and infrastructures and to neglect the less obvious role of the many economic activities that explain the presence of any traffic in the first place, 'activities' being understood, as in Table 1, as levels of all trip purposes of persons or freight. This neglectful ignorance of their role leads representative national[25,26] and international[27,28] road safety documents to either compare cross-sections for given years or to focus on trends and on consensus factors likely to respond to intervention and induce shifts − but not turning points − in the unexplained trends.
Table 1. Recurrent intermediate and/or final activities present in the DRAG-2 model (1956−1993).
Demand for road use (DR) by gasoline and diesel vehicles Crash frequency (A) & severity (G) Gasoline road use demand:
elasticity of veh-km with respect toDiesel road use demand:
elasticity of veh-km with respect toEffect of DR and trip purpose demand mix, i.e. of each (activity level/DR), on A or G Work 0.40 Manufacturing: deliveries 0.80 Work/DR Yes Shopping 0.24 Shopping/DR Yes Vacation and summer fairs 0.05 Vacation/DR Yes Home deliveries 0.05 Home deliveries 0.04 Forestry output 0.14 Forestry output/DR Yes Residential construction input 0.02 Large dam construction inputs 0.03 Residential construction input/DR Yes Engineering works: deliveries 0.02 Agricultural output 0.05 Agricultural output 0.02 DR Yes Sum of gasoline elasticities evaluated at sample means: 0.81 Sum of diesel elasticities evaluated at sample means: 1.05 Each such trip purpose ratio indicator is significant relatively to reference (other). Source: Appendix 1. Detailed Model Outputs, § 1.2, Fournier & Simard[29]. Ch. 15, p. 347, Gaudry & Lassarre[30]. Distinguishing between intermediate, final and total economic activity in structural models
-
Which activities then matter? Road safety outcomes are not just linked to the final output components of GDP but also to its intermediate output structure, i.e. to total economic activity as defined in inter-industry and input-output economics. This linkage to all parts of total output is entirely absent from yearly (cross-sectional, time-series, or pooled) models, which at best include only a measure of final value added such as GDP ̶ a limitation to be lifted below ̶ and perhaps a trend representing misspecification and modeler ignorance, as in Peltzman[17] where the trend is the dominant explanatory variable for his post-war sample (1947−1965). [Note in passing that, in his accident rate tables, Table 2 (death rates) and Table 3 (injury and property damage rates), the proportion of young drivers is the second most significant variable and per capita income (four measures of which are tried) the third. There is no measure of intermediate output or of transport intensity of the US economy. The sample precedes the turning point of 1972.] By contrast, linkage to all components of the economic structure is readily present in the equations of monthly time series models, which often include many intermediate and final trip purpose indicators, even as additions to Smeed's vehicle availability N.
Table 2. Smeed's original country set data base, specification and results with various samples.
Smeed’s original equation Years n. obs. R2 S-1 (Killed/Vehicles) = k (Vehicles/Population)–2/3 S-2 (Killed) = k (Vehicles)1/3 / (Population)2/3 S-3 (Killed) = k (Vehicles)1/3 / (Population)2/3 S-4 Ln (Killed) = Ln (k) + 0,333 Ln (Vehicles) + 0,667 Ln (Population) 1938 20 Our estimates with Smeed’s own equation with more recent data S-5 Ln (Killed) = Ln (k) + 0,408 Ln (Vehicles) + 0,699 Ln (Population)
(16,31) (20,41) 1938*
to 1946210 0,98 S-6 Ln (Killed) = Ln (k) – 0,058 Ln (Vehicles) +
1,100 Ln (Population)
(-3,36) (55,92) 1965
to 1998918 0,88 Note 1. Ln denotes natural logarithm and (t-statistics) are provided in parentheses.
Note 2. Sample S-5 is from Smeed (1949) and sample S-6 is from MAYNARD-DRAG.* The 17 countries for
1938 in sample S-5 are:Portugal Finland South Africa Canada Australia USA Ireland Norway New Zealand Italy Netherlands France Northern Ireland Sweden Denmark Great Britain Switzerland Table 3. Regressors in MnM-2 model of accident frequency, their severity and victims by category.
P Price Minimum gasoline price M Motorization Proportion of cars in total vehicle fleet Congestion Percentage of urban population in total population N Network Legal Highway speed limit (km/h) Seatbelt regulation (dummy) Climate Temperature (yearly average) Total yearly precipitation (mm) Y Driver Age Percentage of 18-24 years old in total population Percentage of 65 years old or older in total population A Final economic output GDP per capita Total/Final economic output Road traffic intensity of GDP (Vehicle-km/GDP) index I ETC. Leap year, Dummy by region relative to that of reference region r Among monthly models, DRAG-1 (in French[31] or in English[32]) has the most detailed representation of intermediate, final and total activities. They appear both in the two equations that explain demands for road use DR (by gasoline and by diesel vehicles) and in those that explain accident frequency A and severity G, these risks being notably (but not exclusively) dependent on total road demands DR and on its mix of trip purposes (ratios of distinct activity levels to total road use demand). Table 1 lists of economic activities or 'traffic purposes' jointly document changes in the structure of intermediate and final activities as no aggregate yearly model has ever done. But let us be more precise.
Table 1 presents the elasticity estimates from a published version of DRAG-2[29] estimated from a continuous sample of 445 months (December 1956−December 1993) for the Province of Quebec as a whole. Note that, if all 10 recurrent activity levels are doubled, their elasticities evaluated at sample means imply that demand for road use DR is approximately doubled. Note also that some activities, such as shopping and home deliveries, are components of final output but that others, such as forestry, agriculture and construction, pertain primarily to intermediate flows while still others, such as work (employment), are linked to all parts of total output, both intermediate and final. In the real economy, road use consists in flows derived from all activities, and not derived just from final (GDP) ones.
Smooth fitting of output indicator-rich models with series containing a notable global maximum
-
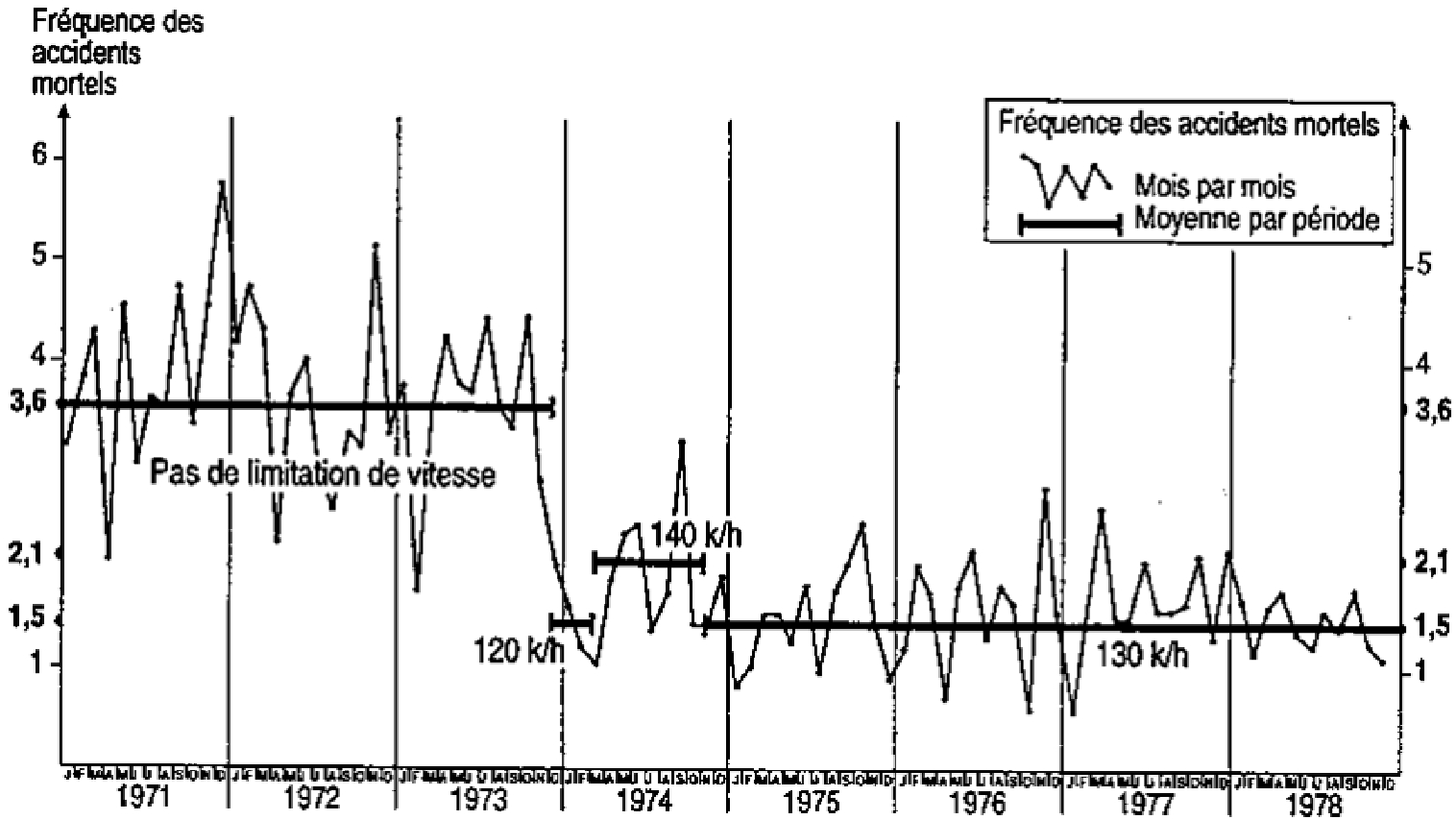
But why are many monthly model fits as published so good if they all include the year of the national or regional peak in fatalities? The (1956−1993) DRAG-2 model includes 1973 for Quebec; the (1968−1989) SNUS-2.5 model[33,34] includes 1972 for West Germany; the (1957−1993) TAG-1 model[35−37] includes 1972 for France, etc. Crucially, all such monthly DRAG-type family models include stationary multiple-order autoregressive schemes which explicitly bring in as regressors the order-lagged values of the dependent and explanatory variables, thereby implicitly transforming static models into dynamic ones[38]. Careful analysis of their residuals reveals that, if and when they overshoot somewhat immediately after the occurrence of their global maximum, they recover rapidly afterwards. [This was also often confirmed at INRETS in Arcueil, France, during the summer periods of 2001 and 2002, by visual analyses of fits in Sylvain Lassare's ARIMA models of fatalities in France, using few or many dummy intervention variable shifts. Clearly, interventions modelled by such dummy variables never induce turning points (cf. Fig. 1)].
Fitting yearly models without the presence of intermediate economic output indicators
-
If monthly models of single regions containing intermediate and final output indicators (10 in DRAG-2, listed in Table 1; six in SNUS-2.5; 5 in TAG-1, etc.) easily 'miss' the presence of a global maximum by surfing gently over it, as it were, yearly models devoid of intermediate activities will notice the presence of a peak by failing to fit it both visually and parameter-wise. This occurs with Smeed's model, limited to the scale indicator Motor vehicle availability N, but also with models using N-km or real GDP instead.
In the beginning, there was no global yearly peak
-
Let us see how. In his first piece from 1949, Smeed[13] (cf. Table 2) used Vehicles and Population to explain fatalities for a 1938 cross-section of countries by a simple logarithmic relationship amenable to slope estimation with a slide rule and graph paper. His famous equation S-1 was obtained by a log-linear adjustment (S-1 to S-4) between the yearly number of killed individuals per registered vehicle and the number of Vehicles per capita for 20 countries, a data set that included the 17 points shown in Fig. 2. He also declared himself satisfied with how the relationship fitted Britain for the 1909−1947 period[40,41] and in tests with a sample of 68 countries for the period 1957−1966[14,15]. [Discussing at Université de Montréal in 1973 or 1974, Smeed himself said he did not know why his relationship 'held']. Adams[40,41] retested it for 62 countries in 1980 and was himself satisfied that the slope coefficients had barely changed from those of (S-1/S-4), but he provided no numerical estimates or t-tests, only graphs of fitted lines. He then claimed that, S-1 holding, safer driver-vehicle-way triplets clearly had no role in the explanation of the most recent road death numbers: drivers must just have re-established their risk at its previous level, chosen before triplets of new 'safety clothes' had been forced on them.
The breakdown of Smeed's relationship
-
We retested it with one of Smeed's data bases, S-5, and again with another, much more recent, pooled S-6 sample for which the estimated coefficient of the first variable changes sign (cf. Table 2), demonstrating clearly that the relationship breaks down. Detailed analysis by many[42,43] indicates that failure happens in the mid-1970's as the model (S-1)−(S-4) starts to grossly over-predict fatalities in advanced countries. To see how this could occur, compare the data set for 1938 from S-5, found in Fig. 2, with that found in Fig. 3 that also includes pre-war values for 1931 from Smeed[13] and from the S-6 sample.
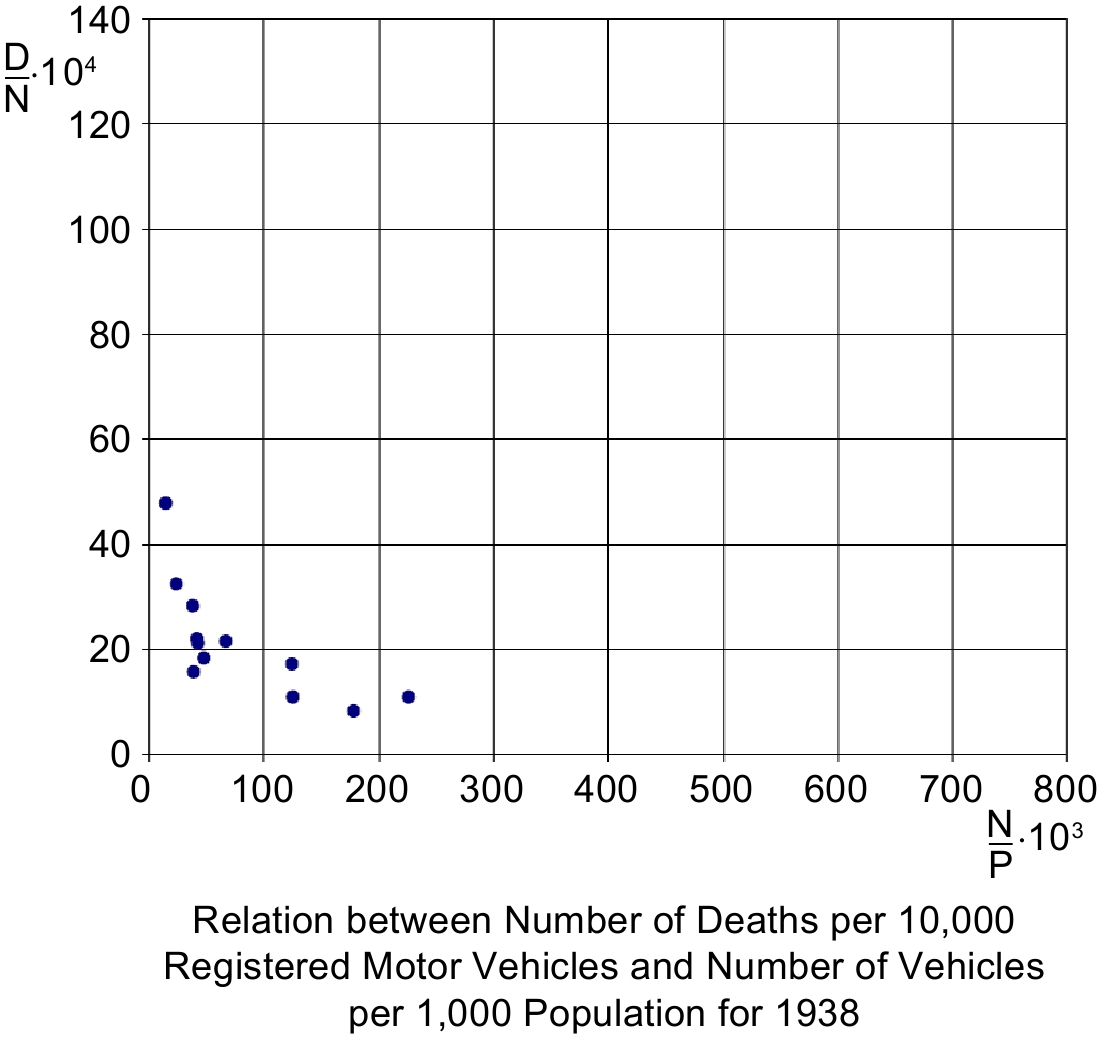
Figure 2.
Fatalities per vehicle and vehicles per capita (Smeed's 1938 data in S-5 sample).
Figure 3 contains data for all 26 countries, for the years 1931 and 1938 together and for 1965, 1970, 1980, 1990 and 1998. Shown chronologically in Fig. 4, the film reveals clouds of points gradually moving down to the right and collapsing to a straight line approaching zero. Note also that all (red) points from S-5 (for 1931 and 1938) are to the left of 230 vehicles per 1,000 persons indicated on the x-axis but that (blue) points from S-6 (for 1965; 1970; 1980; 1990; 1998) are more evenly distributed.
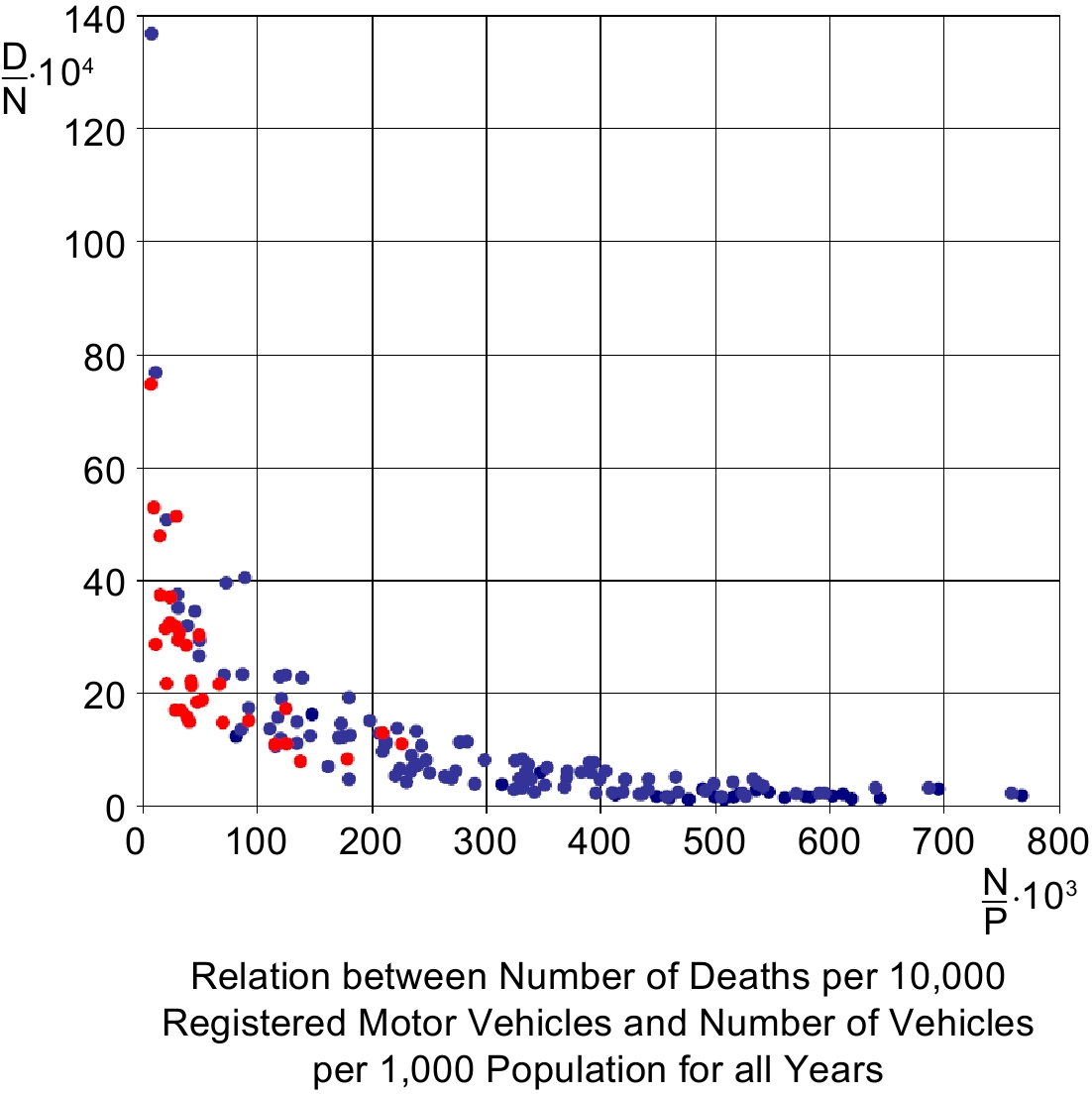
Figure 3.
Fatalities per vehicle and vehicles per capita (Smeed‘s 1931; S-5 and S-6 samples).
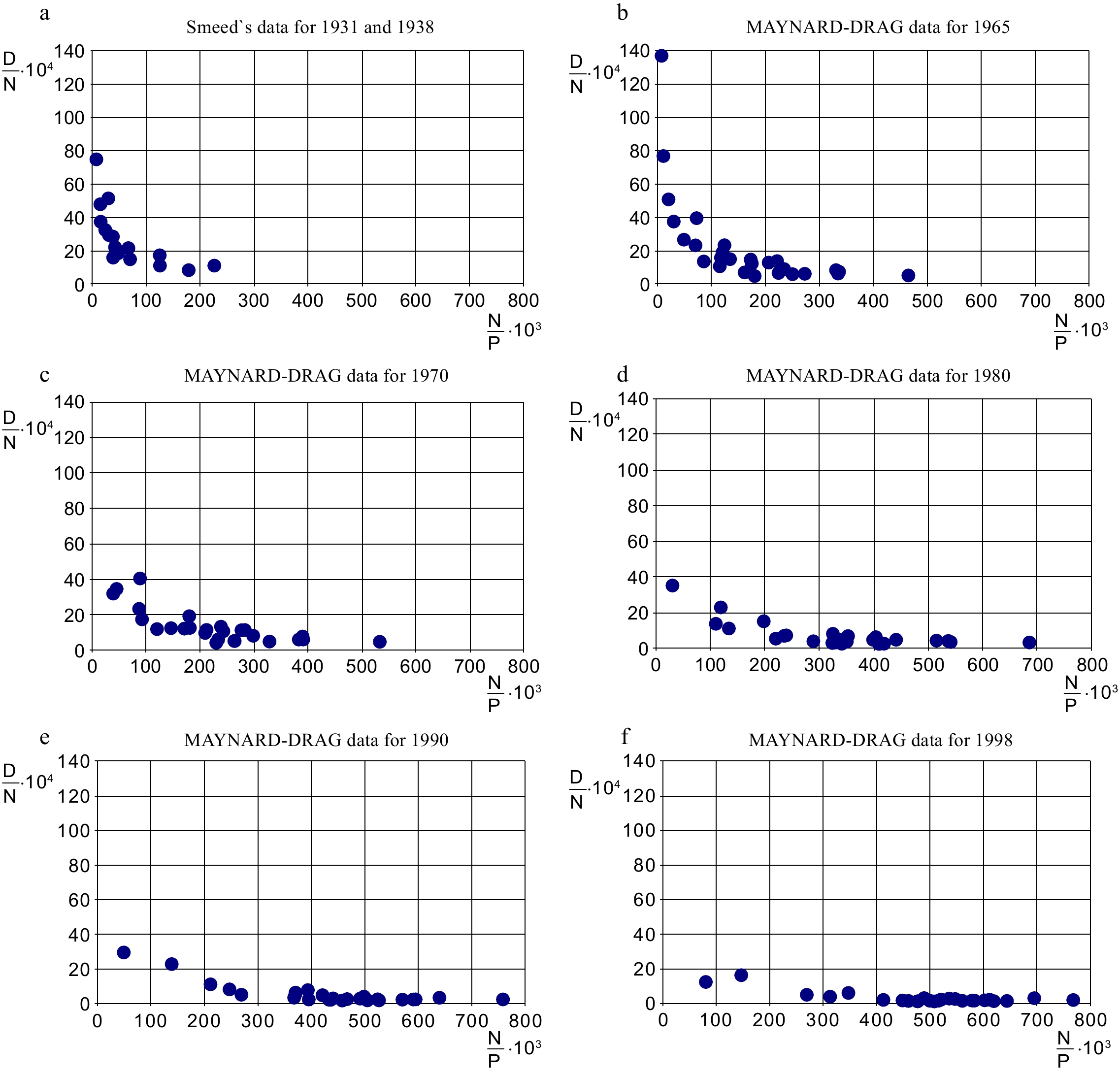
Figure 4.
Fatalities per 10,000 vehicles and vehicles per 1,000 inhabitants over time in 26 countries.
Clearly, changes happen over time and it is strange to claim for the USA (cf. Fig. 5b also) that 'death rates due to motor vehicle traffic appear to be largely independent of the number of vehicles in circulation and stable [Marchetti's own data for the USA show variation from 16 to about 32 with sharply falling variance over time between 1920 and 1990 ─ hardly, as stated in his Fig. 15, 'a basic instinct in risk management' ─ to say nothing about accident rates in aviation where the view of any anthropological constancy across cultures or civilisations would be no less preposterous] around 22 per 100,000 inhabitants since Henry Ford's times'[44].
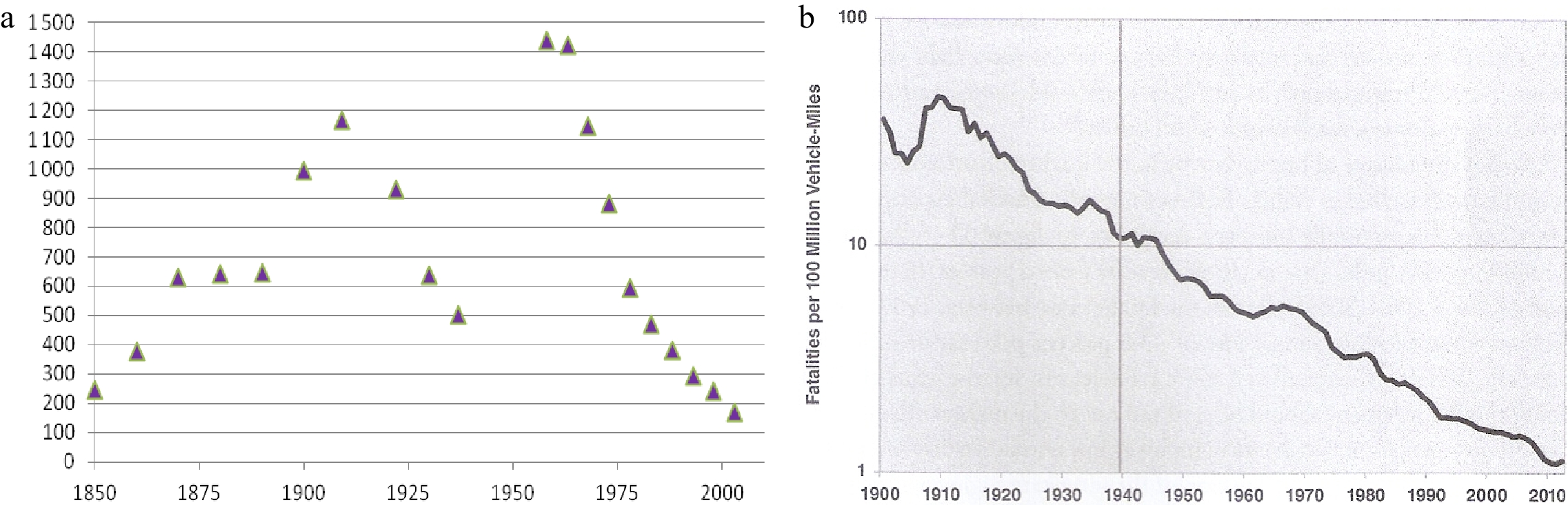
Figure 5.
Secular fatality intensity of road traffic in France (1845−2005) and the USA (1900−2012). (a) Index of the fatality intensity of total road traffic. Deaths caused by horses, horse-drawn carriages and automobiles in France, 1845−2005 (mostly quintannual) (Source: [45], Figure 4.F, p. 14). (b) Logarithm of motor vehicle road deaths per 100 million vehicle-miles in the USA, 1900−2012 (yearly) (Source: [46], Figure 11-6, p. 386).
Bad dreams of imagined anthropological constants aside, the reason for the over-prediction in some 18 countries from about 1975 onwards is in fact that their fatalities stopped increasing and started falling, after having reached a global maximum between 1970 and 1974 (nine of which, listed in Table 4, are in 1972 alone) as indicated in Fig. 6. This clustering of maxima (the other maxima listed in Table 4 are less concentrated), at first diagnosed as 'The Mystery of 1972−1973'[47,48], was later relabelled 'The Matterhorn' peak [Meadow (English) or Cervin (French)][13,49].
Table 4. Evolution of per capita fatalities and injuries in 26 countries and Quebec, 1972−1998.
Appendix 2 values: Fatalities per 10,000 inhabitants Injuries per 10,000 inhabitants 13 regions included
in MnM model sampleIn 1998
(Rank 1-26)% change
1972−1998Speed rank
(1−26)In 1998
Unranked% change
1972−1998Speed rank
(1−26)Australia 0.940 (10) −63.795 7 11.114 −83.686 1 1. Austria 1.192 (15) −70.423 3 63.230 −36.737 8 2. Belgium 1.470 (21) −53.975 14 69.345 −34.893 9 11. Canada 0.966 (11) −65.849 6 71.503 −27.094 12 3. Denmark 0.856 (9) −61.690 8 16.767 −66.208 2 Finland 0.776 (4) −68.843 4 17.654 −48.756 6 4. France 1.515 (23) −56.743 11 28.640 −61.874 3 Germany (East) 1.417 (20) 0.755 25 63.181 123.166 25 5. Germany (West) 0.842 (7) −72.476 1 60.013 −30.165 11 6. Great Britain (UK) 0.594 (1) −58.237 10 55.917 −13.355 13 Greece 2.117 (25) 64.779 26 31.780 10.670 21 Hungary 1.356 (19) −22.071 21 26.095 0.974 19 Iceland 0.985 (12) −10.457 23 51.022 −10.765 15 Ireland 1.236 (16) −41.591 17 34.475 16.418 22 Italy 1.098 (14) −50.070 15 51.024 3.622 20 Japan 0.855 ( 8) −55.724 13 78.244 −5.681 17 Luxembourg 1.336 (18) −56.519 12 36.545 −51.246 5 7. Netherlands 0.679 (3) −72.269 2 31.560 −39.975 7 New Zealand 1.324 (17) −46.121 16 32.730 −57.435 4 8. Norway 0.794 (5) −36.251 19 27.347 −4.954 18 Portugal 2.133 (26) −16.477 22 69.163 73.759 24 13.Quebec (0.987) (12−13) (−69.774) (3−4) (64.194) (−22.418) (12−13) 12.Spain 1.513 (22) −9.965 24 35.909 30.490 23 9. Sweden 0.600 (2) −59.194 9 24.126 −7.813 16 10.Switzerland 0.840 (6) −67.879 5 39.108 −32.709 10 Turkey 1.011 (13) −26.192 20 18.201 223.304 26 USA 1.534 (24) −41.007 18 118.091 −11.304 14 Portugal / Great Britain 3.6 ≡ Max / Min 26/1 1.2 24/13 USA / Australia 1.6 18/7 10.6 ≡ Max / Min 26/1 (1.06; 1.15) ≡ (Median; Mean) of 26 36.23; 44.72 ≡ (Median; Mean) of 26 Source: all series are from the MAYNARD-DRAG database[50]. 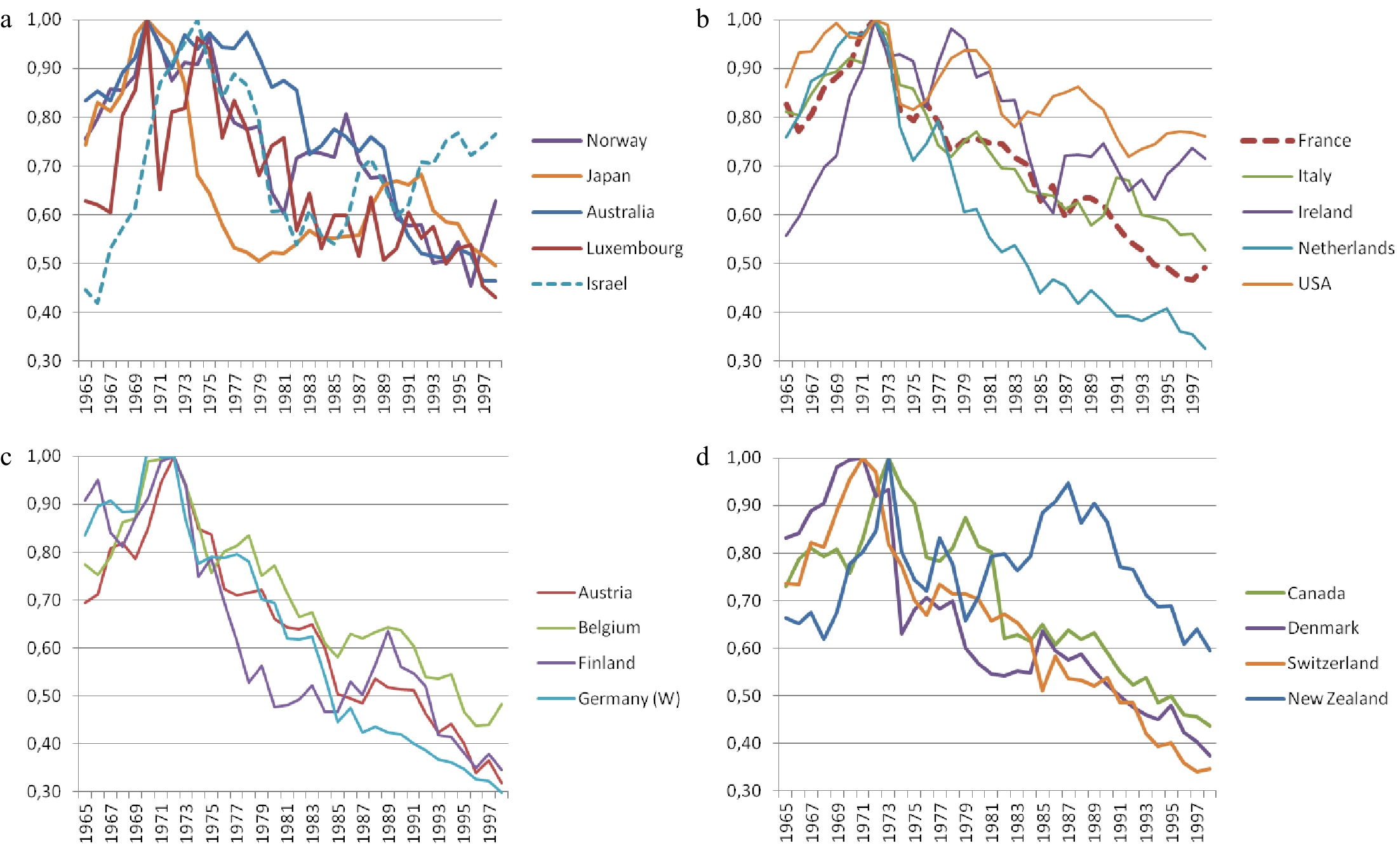
Figure 6.
Meadow-shaped evolutions of yearly road fatalities in the 18 OCDE lustrum countries. (a) Fatality indices, 1965−1998: Norway, Japan, Australia, Luxemburg (1970 = 1.00), Israel (1974 = 1.00). (b) Fatality indices, 1965−1998: France, Italy, Ireland, Netherlands, USA (1972 = 1.00). (c) Fatality indices, 1965−1998: Austria, Belgium, Finland, West Germany (1972 = 1.00). (d) Fatality indices, 1965−1998: Denmark & Switzerland (1971 = 1.00), Canada & New Zealand (1973 = 1.00). Source: Gaudry[51], except the series for Israel from
www.cbs.gov.il/publications16/acci15_1643/pdf/gr01_e.pdf .From 18 to 26 country maxima
-
If one extends this 1970−1974 lustrum time window in both directions, the number of fatality maxima increases to 26, as show in Table 5. Interestingly, analysis of monthly data shows that all 1972−1973 peaks occur well before the first oil crisis of October 1973, typically in late summer or early autumn. In fact, the global national maximum is reached by nine countries during the same quarter of 1972 and by two more about a year later, which raises the question: can these 11 peaks within 15 months be a random result?
Table 5. Year of the global maximum of road fatalities in 26 countries, 1965-1998.
Year n The 26 countries of Appendix 1
(plus Israel, minus Turkey)*1965−1966 2 Great Britain, Sweden 1970 4 Australia, Luxemburg, Norway, Japan 1971 2 Denmark, Switzerland 1972 9 Austria, Belgium, France, Finland, Germany (W), Ireland, Italy, Netherlands, USA 1973 2 Canada, New Zealand 1974 1 Israel 1975 1 Portugal 1977 (1/2) Germany (E) before reunification 1988 1 Iceland 1989 1 Spain 1990 1 Hungary, 1991 (1/2) Germany (E) after reunification 1998 1 Greece * Note: to define a global national maximum, WWII years are excluded for Great Britain which really peaked in 1940−1941. -
In the above sections, we were on purpose slightly vague about injured road victims warranting medical care. To the extent that economic activities critically determine total traffic levels, they should be expected to peak at the same time as fatalities, but this expectation is muted by the possibility that they can also act as substitutes in a multi-commodity (deaths, injuries, material damages only) demand system of accident frequency or of their damage outcomes. Injuries might also increase their share when interventions aimed at extreme or risky behaviour, or when high congestion, exist, or when the final private (final) consumption share of traffic, as identified in Transport Satellite Accounts[52], sharply increases after the peaking of Road traffic intensity of GDP.
But there is a greater difficulty still with injuries, linked to their general underestimation and to changes in police accident reporting procedures (always less thorough than coroner analyses of traffic deaths) calibrated without benchmarks and very differently across countries and motor vehicle insurance systems, as the analysis of Table 4 data demonstrates. [Quebec was considered by itself and added to the sample at the request of a principal funding agency in 1999−2002, Société de l'assurance automobile du Québec, then hoping an unambiguous road safety ranking indicator could be found].
International differences in the definition of road injuries
-
An examination of the per capita series of Appendix 2 confirms the well-known fact that the definition of a road fatality varies much less across countries than the definition of a road injury. Consider the values for the end of our series, 1998, reproduced in two columns of Table 4. Whereas the ratios of the maximum to the minimum for fatalities is 3.6 [= (Portugal = 2.1)/(Great Britain = 0.6)], it is 10.6 [= (USA = 118)/(Australia = 11.1)] for injuries. Although slight differences in the way fatalities are reported by the police (mainly due to the number of days of hospitalization considered to decide whether a road victim deceased, e.g. 1 d, 3 d, …7 d) may be consistent with a ratio of 3.6 that reflects real differences, there is no way that injury rates can vary by a factor of 10,6 across extremely similar countries (for instance the USA and Australia, that differ merely by a factor of 1.6 in fatality rates).
In addition to the levels of individual fatality and injury risk in 1998, it is interesting to note in Table 4 the evolution of these indicators since the dominant peak year (1972): the median and mean values of the fatality rate are 1.06 and 1.15 and those of the injury rates are 36.23 and 44.72, respectively. Since 1972, the percentage changes of both indicators exhibit variations that are in no way parallel, as the changing ranks of the 26 countries demonstrates: only Eastern Germany remains 25th on both speed counts calculated over the 26 years 1972−1998.
Our position
-
Considering only the 18 countries with fatality peaks during the 1970−1974 lustrum, nine have their injury peak either simultaneously with their death peak (the five whose injury peaks are shown in Fig. 7a) or within 2 years before it (the four whose injury peaks are shown in Fig. 7b); the other half all have them after their death peaks, as can be verified in Appendix 1. Note already in Fig. 7, even before consulting Table 4, that the downside slopes of the injury indices of countries with injury peaks occurring earlier than their death peaks (in Fig. 7b) are on average lower (and more grouped) than those of countries with simultaneous death and injury peaks (in Fig. 7a), a difference that also requires explanation and suggests again the presence of a shared structural economic factor change.
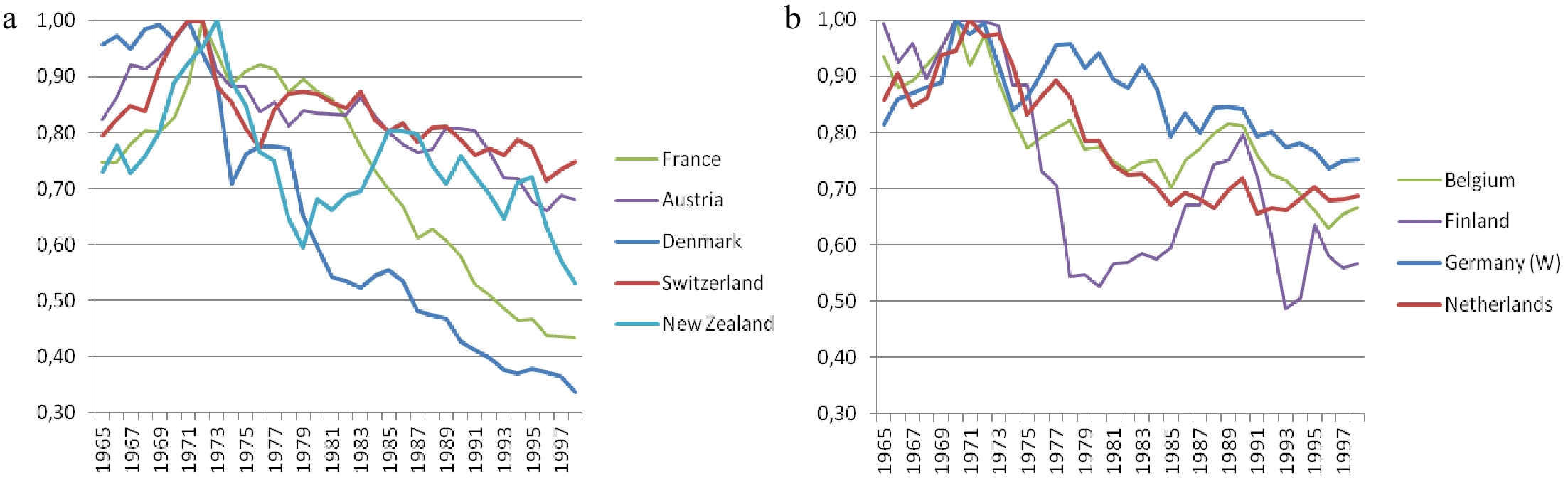
Figure 7.
Lustrum country injury peaks simultaneous to, or preceding, their own fatality peaks. (a) Injury peaks synchronized with death peaks, 1965−1998: Denmark, Switzerland (1971 = 1.00); France, Austria (1972 = 1.00); New Zealand (1973 = 1.00). (b) Injury peaks occurring earlier than 1972 death peaks, 1965−1998: Belgium, Finland, West Germany (1970 = 1.00); Netherlands (1971 = 1.00). Source: all series are from the MAYNARD-DRAG database[50].
Considering now only the 13 'regions' used in the regression models specified seven below (on 12 countries and Quebec), one notes that (i) seven of them will have synchronous fatality and injury peaks [Those of Fig. 7a except for New Zealand, plus Great Britain (in 1965−1966), Sweden (in 1969) and Spain (in 1989).]; (ii) three will have earlier ones [those of Fig. 7b, except for Finland.]; and (iii) three later ones [Norway (in 1977), Quebec (in 1979) and Canada (in 1989)]. We will not try to understand why some (a minority) of our model sample countries have injury peaks that are not synchronous with the fatality peaks: we just hope that the new I variable, Road traffic intensity of GDP, improves the fit for injuries as much as it does for fatalities ̶ slopes, leads and lags included. Concerning Denmark (in Fig. 7a), for instance, the downward trends of monthly accident aggregates of three categories (with killed, with seriously injured and with any injury victims) have been studied in depth by an author[5] who concluded to the failure of all explanations based on recorded variables (exposure, GDP, etc.) over a long period (1978−2001). A better fitting model should mean gains in the quality of adjustment for all categories of safety performance measures and over their full sample ranges, and not just at Matterhorn period peaks.
Methods: on previous attempts to make sense of the 1970-1974 peaks, and intuition of the new variable I
-
Before we propose our own tests, it is useful to recall how people have tried to make sense of the 1970−1974 peaks, and even of their clustering, and to intuitively document the role of a new Road traffic intensity of GDP variable I for aggregate models where final activity GNP is already present.
On past attempts to conquer the Cervin/Matterhorn/Meadow
-
First, we survey in turn the main approaches used to explain the existence of Fatality peaks since the demise of Smeed's S-1 estimate:
i) Reductions in maximum legal speeds. It is tempting to impute a turning point to a reduction in maximum speeds (or to more belt use), but this linkage is dubious for reasons of both timing and experience with such interventions, which shift trends but do not cause them to turn.
Considering solely countries where fatalities peaked in 1972, Finland imposed reductions during that year but France only in March 1973 outside of built-up urban agglomerations (and in December for highways ̶ 'autoroutes') [In July 1973, the obligation to wear belts in front seats was combined with limitations to 110 km/h on high traffic roads and 100 km/h on the rest of the network] and the USA in March 1974. More significantly and decisively, such changes tend to induce shifts, not turning points, as in Fig. 1 where the legal maximum on the large French highway network changes thrice within 11 months [to 120 km/h on 3rd December 1973; to 140 km/h on 13th March 1974; to 130 km/h on 6th November 1974].
If journalists all too easily make the linkage, for instance in France[53], professionals may also succumb in light-hearted editorials void of due statistical tests[39];
ii) Driver stock quality and congestion. Among structural variables other than speed limitations (combined with front seat belt use, or not), two candidates were examined and rejected[55].
First, the 'youth bulge' theory[56−58] whereby the wave of baby boomers would reduce the average quality of the stock of drivers, fails because its maximal impact on the average quality of the stock occurs only around 1980 in all countries concerned (Spain excepted), as young drivers of the baby boom obtain driver permits and progressively lower the average quality (based on relative risk by age) due to their exceptional cohort shares.
But the congestion theory, whereby OECD countries with fatality peaks in 1972−1973 often saw shares of public investment expenditure on highways fall after 1966, is a more credible prospect. It is noteworthy that a relative disinterest in roads occurs long before the strong increase in vehicle ownership that starts in 1970 (as baby boomers turn 22−23 or so), causing clear 10° to 15° kinks in national vehicle ownership trends and perhaps prompting OPEC to raise the price of oil in October 1973 on the background of a 4-year long bout of strong upward market pressure.
However, testing that congestion hypothesis is extremely difficult. Aggregate nation-wide congestion indices are extremely rare and consist mostly in single-year and single-country cross-sectional estimates[59], not in long time series sufficient to suggest or back simultaneous turning points around 1970−1974. And, when series are available, they pertain to the higher network, as in France where average speed on it has tended to increase between 1967 and 1997[36]. The only model containing a proper congestion index is TRULS-1[60−62] estimated from a panel data set (of 5016 monthly observations on the 19 counties of Norway, 1973−1994), which contains the variable Vehicle-km per km of road per month per county but unfortunately does not start early enough to cover 1970, year of maximum Fatalities in that country;
iii) Victim mix and de-pedestrianization. Is it possible to explain maxima in road victims by a change in the mix of say pedestrians and others sharing the road? Some[23] explain part of the decrease in numbers of persons killed since 1963 in 32 countries by the lower number of pedestrians killed; and similarly, with much hard work, an author[20] extends the exercise to all combinations of road user interactions in The Netherlands. But these approaches fail to justify any turning point in aggregate Fatalities;
iv) Safer vehicles and ways. Safer vehicles and roads are often presumed to have favourable effects on safety and to yield a net gain despite some offsetting behavior to maintain a chosen risk level. The gain may be due to limits on risk taking: for instance, lighting is installed on highways but speed limits prevent users from maintaining their desired risk level. We know of no study of this undemonstrated presumption that could convincingly claim to account for even a single national maximum, to say nothing of the cluster of almost simultaneous turning points in 18 countries;
v) Imposed turning points. As the data obviously contain them, in many cases with different slope trends before and after the maximum[63] [They examined Denmark, the United Kingdom, the Netherlands, Norway, Sweden and the USA], why not model turning points and preferably different before-and-after slopes? A first method consists in multiplying the growing indicator of interest by an exponential or logistic function of negatively weighted time, per force eventually yielding a maximum or a marginally decreasing value, depending only on the particular function and parameter of time. A second method, more amenable to yielding an asymmetric inverted U-shaped curve, fits a continuous non monotonic function, or fits splines, to a chosen structural variable, such as Vehicle occupancy or GDP per capita, as we presently see.
Concerning the first approach, for instance, some researchers[22,64] notice the 1972 peaks in 4-5 countries (The Netherlands, the USA, West Germany, the UK and Japan) and fit the data by making the safety indicator follow a negative exponential function of time and traffic a sigmoid logistic one. The first author[21] performs a similar exercise for road death peaks of 1972−1973 in the same five countries [For the UK, he neglected both the higher post-war value of 1966 (7,985) ― he uses 7,763 for 1972 ― and the true maximum in 1941. This sloppiness reduces his set from six to fove countries (keeping Israel that in fact peaked only in 1974)] plus Israel. But these exponential functions have zero asymptotes and are incompatible with current reported numbers of road casualties in developed countries[65]; moreover, mere functions of time provide no structural explanation but just curve fitting.
With the second approach, one looks for a variable that could have non monotonic effects and one applies a procedure to estimate its shape as part of the regression model. A first procedure to test the ∩-shape uses two Box-Cox transformations (BCT) on the chosen variable W, usually within a regression model where BCT are used on the dependent and other variables, namely:
$y_t^{({\lambda _{y}})} = {\beta _0} + \sum\nolimits_{k = 1}^{k = K} {{\beta _k}} X_{kt}^{({\lambda _{k}})} + {u_t},\quad {y_t} \gt 0,\;{X_{kt}} \geqslant 0 $ (1) where the BCT is defined as:
$\;{X_{vt}}^{({\lambda _v})}\,\, \equiv \,\,\,\left\{ \begin{gathered} {{\left[ {{{({X_{vt}})}^{{\lambda _v}}}\, - 1} \right]} \mathord{\left/ {\vphantom {{\left[ {{{({X_{vt}})}^{{\lambda _v}}}\, - 1} \right]} {{\lambda _v}}}} \right. } {{\lambda _v}}}\quad ,\,\,\,\quad \,\,\lambda \, \ne \,\,\,0 \\ \ln \,({X_{vt}})\quad \quad \quad \quad \,\,,\quad \,\,\,\;\lambda \, \to 0 \\ \end{gathered} \right. $ (2) and one of the explanatory variables, say W, is used twice as follows:
$ Q({W_t}) = {\beta _{Q1}}W_t^{\left( {{\lambda _{Q1}}} \right)} + {\beta _{Q2}}W_t^{\left( {{\lambda _{Q2}}} \right)} $ (3) in which case the BCT are distinct [
${\lambda _{Q1}} \ne {\lambda _{Q2}}$ ${\beta _{Q1}}$ ${\beta _{Q2}}$ ${\lambda _{Q1}} - {\lambda _{Q2}}$ $ {\lambda _{Q1}} \ne {\lambda _{Q2}} $ ${\lambda _{Q1}} = 1;{\lambda _{Q2}} \ne 2$ $ {\lambda _{Q1}} = 1;{\lambda _{Q2}} = 2 $ In monthly models, an asymmetric form [
$ {\lambda _{Q1}} = 1;{\lambda _{Q2}} \ne 2 $ Table 6. Sign conditions for a maximum or a minimum with two BCT on a repeated variable.
CASE ${\beta _{Q1}}$ $ {\beta _{Q2}} $ ${\lambda _{Q1}} - {\lambda _{Q2}}$ $ {\beta _{Q1}}({\lambda _{Q1}} - {\lambda _{Q2}})$
or $ {\beta _{Q2}}({\lambda _{Q2}} - {\lambda _{Q1}})$∩ Maximum 1 + − − − $\cup $ Minimum 1 + − + + ∩ Maximum 2 − + + − $\cup $ Minimum 2 − + − + Source: [66]. A second procedure to obtain ∩-shapes uses splines[67] on the Income variable (defined as GDP per capita) with a 1963−1999 panel data set for 88 countries. The authors' piecemeal linear approach to explain fatality rates (with 10 income groups, each having the same number of observations) was used on logs of Income, which allows the monotonic logarithmic function pieces to turn. This involved 10 different spline coefficients whereas using two BCT as in the first procedure would have involved only four parameters (two coefficients and two BCT powers). The rest of their otherwise sparse model consisted in eight (linear or logarithmic) regional time trend variables (for seven geographic and one high-income country groupings).
Their estimated turning point Income per capita is $8,600 (in 1985 international dollars), 'after which the fatality risk begins to decline'. This is a very low number if one looks at the per capita income of the countries listed in Table 4 during the year of their turning point, as documented in Table 7. Only the UK turns at that income level and countries can turn at much higher values or at much lower ones (note Portugal and Switzerland, the lowest and highest). Indeed, the standard error of actual turning point values is greater than the per capita GDP of many countries!
Table 7. Actual per capita GDP of countries at the observed turning point of their road fatalities.
Year of maximum deaths (and fatality rate) and corresponding per capita GDP (1985 US dollars) 1965 Sweden 12,291 1972 Austria 13,219 1972 USA* 14,649 1966 UK 8,306 Belgium 13,271 1973 Canada 10,638 1970 Australia 9,988 Finland 12,107 New Zealand 10,591 Luxembourg 15,550 France 13,434 1975 Portugal 4,715 Japan 15,200 Germany (West) 11,581 1988 Iceland 19,752 Norway 11,824 Italy 8,541 1989 Spain 9,825 1971 Denmark 16,579 1972 Ireland 6,001 1998 Greece 9,218 Switzerland 28,670 Netherlands 13,356 MEAN: 16,526 STANDARD ERROR: 6,409 COEFFICIENT OF VARIATION: 0,39 * MAYNARD-DRAG database values in 1995 dollars have been adjusted by 0,761 from the US GDP deflator. Clearly, a dollar of income does not have the same rough transport safety implications in the different countries and something is obviously missing from the Income-only explanation of the turning point: Greece, Luxemburg and Iceland, to say nothing of the others (the relative standard error of income for the year of the maximum is 0.4), turn at too different income levels. One suspects that something physical should complement the GDP dimension of final output in value, even if one has used splines which are more flexible than a straight quadratic [A quadratic specification of per capita GDP, imposed to explain Algerian fatalities (which have yet to exhibit a visible global maximum) is too violent[68] and would no doubt have been rejected in a test with equation (3)]. A presumed advantage of the intended addition of the Road traffic intensity measure I is the introduction of a physical dimension to characterize economic development, because a given GDP per capita money value may correspond to quite different (intermediate and even) final output basket mixes.
The idea of Road traffic intensity of GDP
-
The idea that I, Road traffic intensity of GDP, with a numerator reflecting flows derived from all activities, complements GDP already included as determinant of death levels and rates in yearly models was prompted by graphs of I for the USA[69] (where fatalities peak in 1972) and comforted by graphs for Norway (where fatalities peak in 1970). Both sets of graphs, reproduced in Fig. 8, point to a role of I in explaining the Fatality peaks.
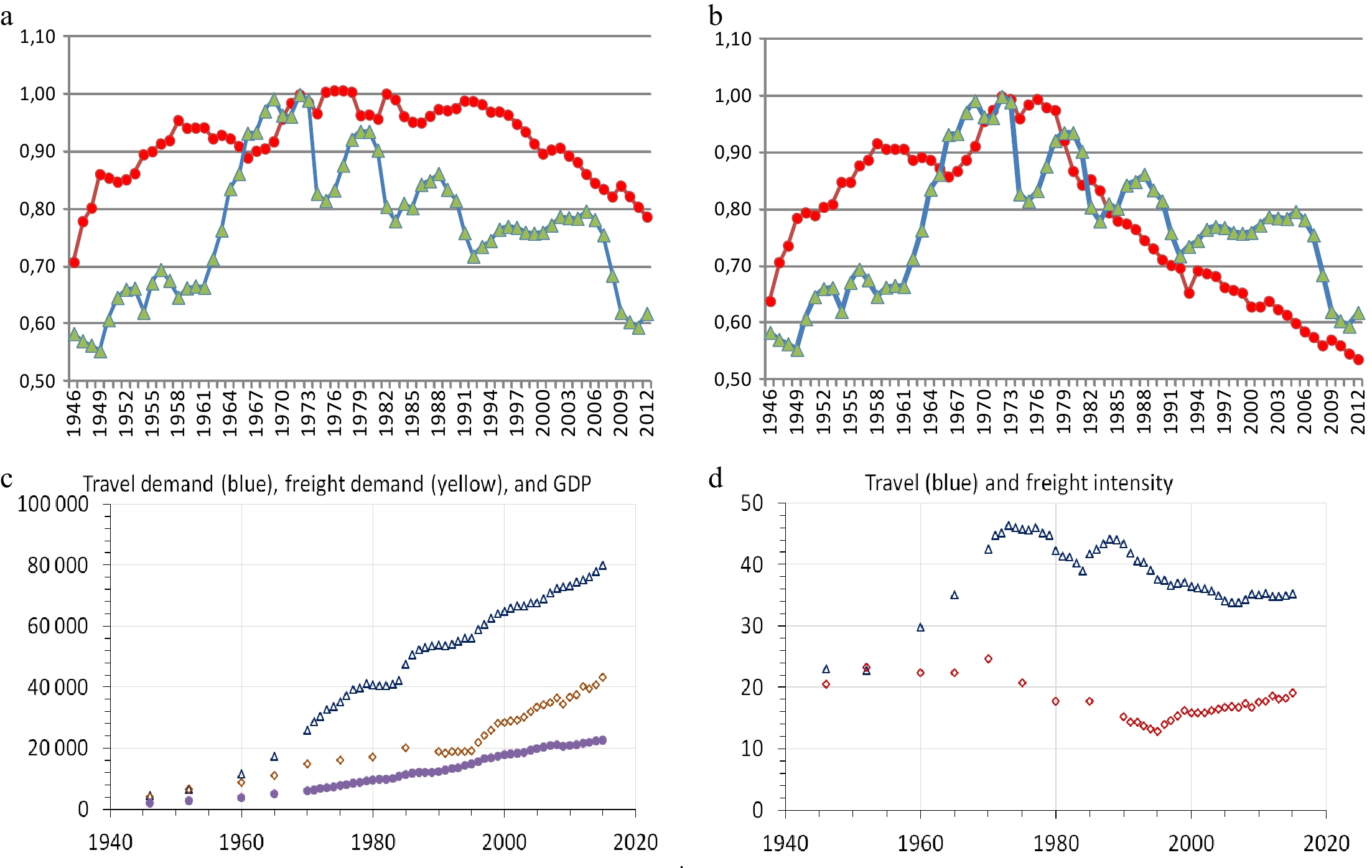
Figure 8.
Measures of national transport intensity of GDP (in constant national currencies). Upper pannel, Fatality (1972 = 1) and Road traffic intensity of GDP indices (1972 = 1) for the USA, 1946−2012. (a) [Fatalities (




The link between I, the Road traffic intensity of GDP, and the profile of peaking Fatalities is in fact obvious for the USA for which the author[69] defines two 'measures of the relationship between road transportation and economic activity', both presented in index form in upper pannel of Fig. 8, but fails to link them to the 1972 peak in American road fatalities (plotted here with each measure). Although he does not use the expression 'traffic intensity of GDP', he effectively calculates it with Vehicle-mileage (T1, which peaks in 1977) and with Gallons of fuel consumed (T1*, which peaks in 1972). Interestingly T1, which is actually more correlated (0.62) with fatalities than T1*, is logically and statistically the best candidate for a traffic intensity of GDP linkage to fatalities. But what of Norway?
Although lower pannel of the graphs in Fig. 8 pertain to all modes [The data pertain to domestic transport only and exclude the non-motorized travel modes (cycling and walking) and use of international travel and freight. Globalization has probably moved abroad a growing share of transport in recent decades], the overwhelming road share in these series suggests a peak in road transport intensity around 1970, year of maximum road fatalities. The changing composition of the economy is hard to detect with absolute levels of traffic and GDP in the left-hand side Graph A but comes out clearly in the right-hand side Graph B. And the distinction between freight and passengers enriches the link between economic development and the transport intensity of GDP (if not directly its specific road transport intensity) but should still allow changes in their sum, peaking with fatalities in 1970, to mimic changes in the ratio of intermediate to total output.
In short, in the absence of yearly aggregate data series on intermediate output, the new variable seems to be the simplest way to introduce that sort of economic structural change into yearly models, even if more sophisticated ones could be imagined if appropriate yearly data were available by country. The new variable I (to be defined more precisely) resembles the Transport intensity of GDP notion[70] but has different units from it because we are interested in the road mode and not in the sum of all modes.
Putting flesh on I, the yearly indicator of road transport intensity of GDP
-
But how should I be measured? Figure 9 presents an apparent dilemma because the fuel consumed measure matches peaking fatalities in Norway, as in the USA [In Belgium, Denmark and the USA, the fuel consumed-based indicator profile is somewhat closer to the Meadow-shaped profile of road fatalities than the distance-based measure], but it is the distance-derived measures that provides the same match in France. We shall use the latter measure of I, the correct one, which has a correlation of only 0.60 with the fuel measure over our sample period 1965−1998 of vehicle fuel efficiency gains [In upper pannel of Fig. 8, the correlation between the two indices for the USA is only 0.16. Vehicle fuel efficiency gains become a concern only after the first OPEC shock of October 1973].
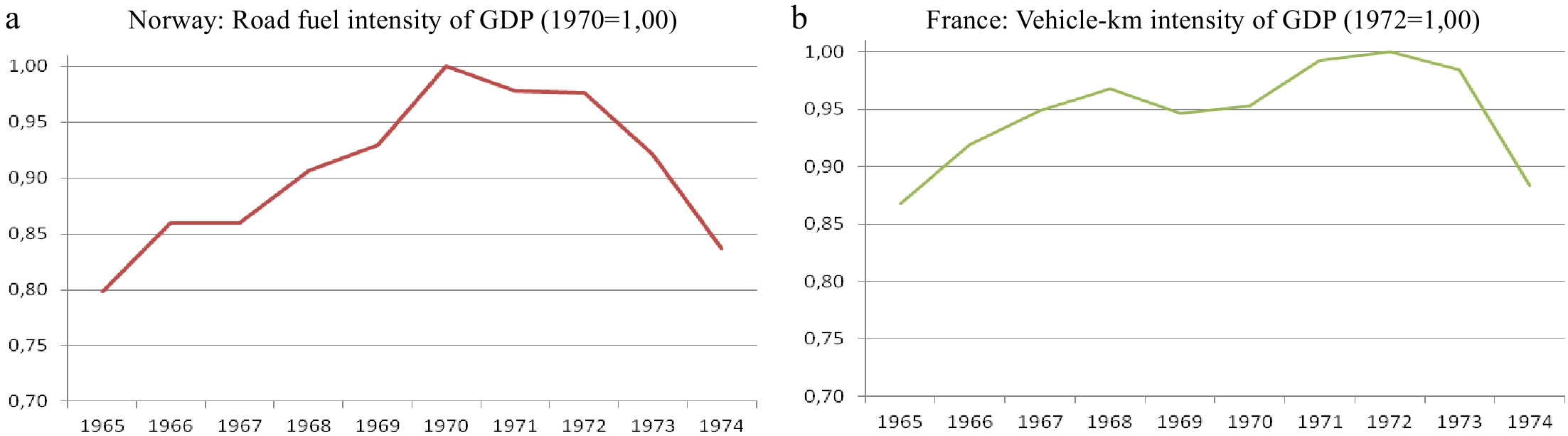
Figure 9.
Road fuel and Vehicle-km indices of road use intensity of GDP (defined over 1965−1998). Source: all series are extracted or derived from the MAYNARD-DRAG database[41] except for the GDP series for France, which is from INSEE. The traffic intensity indices are defined over the period 1965−1998.
On the evolution of I 1965−1998
-
To introduce the notion of Road traffic intensity of GDP above, we have calculated our indices over the period 1965−1998 and shown, in T1 of Fig. 8 and in Fig. 9, portions of those indices that happen to reach their global maximum of 1.00 synchronously with fatality indices. But this conjunction is secondary: a valid enrichment of the initial model by the addition of I does not require that this measure reach its maximum at the same times as fatalities. In fact, measures of I often exhibit only a weak local maximum (and not a global one, as they increase further) at the same time as fatalities, as is the case in Fig. 10 for Denmark and The Netherlands, included in our estimation sample of 12+1 countries, as well as for Finland and Italy, which are not.
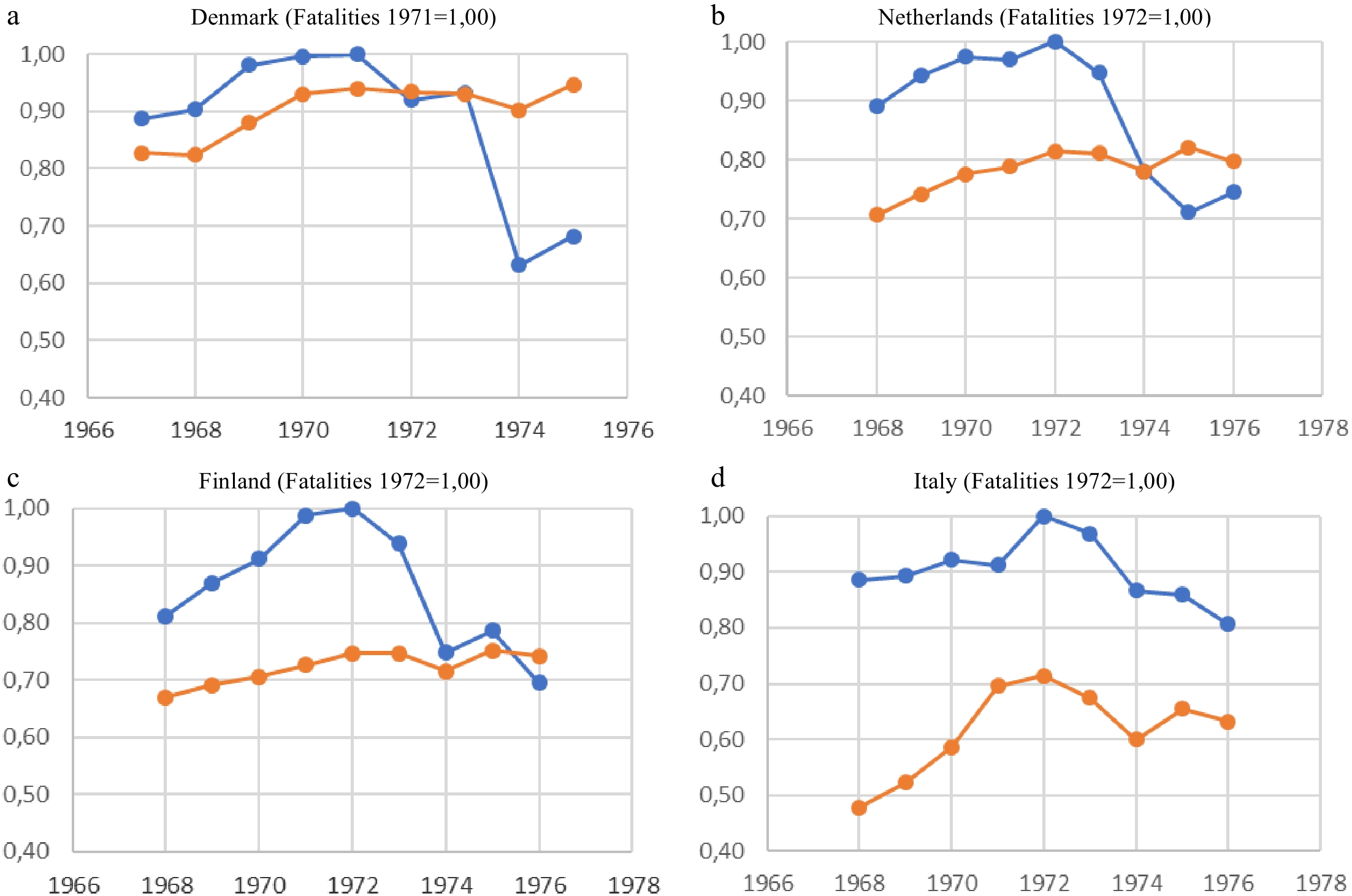
Figure 10.
Global maxima of fatalities (at 1.00) and local maxima of road traffic intensities of GDP.
I as having induced regional convergence in regional per capita incomes?
-
A significant maximum in the transport or traffic intensity of GDP is a profound economic change. Note that GDP growth rates by region seem to diverge in the USA since about 1972 and GDP growth rates by worker since about 1980 when rates in coastal states take off relatively to rates for non-coastal regions[71], ending the great post World War II convergence in regional per capita incomes.
These new divergences among American regional growth rates could reflect the evolution of the national ratio of intermediate (or total) to final output that accompanies the start of the decreasing Road traffic intensity of GDP in the USA in 1972.
On I as an economic spine for natural hill-climbing without splines
-
Our equation specifications below purport: (i) to enrich the description of economic development activity variables by adding Road traffic intensity of GDP to GDP per capita; (ii) to make no changes in the other variables, be they socio-economic (age and vehicle shares, urbanization, etc.), or climatic (average temperature and total precipitation) and perhaps subsumed in constants or in trends, dominant in some authors[17,67], especially when, like the latter authors, one resorts to intuitive country groupings manually defined a priori (i.e. not endogenously within the model). Trends, linear or turning, are not proper behavioural variables but signs of desperate model specification poverty, of modeller ignorance, or of both.
Is the Matterhorn sub-period of I atypical?
-
After specifying our equations and reporting our results, we will probe the background of The Matterhorn 1970−1974 period of interest. We will see that it is an exceptional period of worsening fatalities and fatality rates per kilometer driven that requires some reconciliation with a secular background of apparently decreasing Fatalities and Fatality intensity of traffic. It may then be that Road traffic intensity of GDP can help to understand not only the exceptional contrary periods of peaks (including that of the post-Great Depression in the USA) but also the downward evolution of the Fatality intensity of traffic itself over the 20th Century in both France and the USA. We will propose a tentative interpretative framework for this reconciliation, based on what is known of the secular behavior of the Fatality intensity of traffic in those two countries.
Selected model specification MnM-2: the frequency of bodily injury accidents, their severity rates and victims (1965−1999)
A context of fixed and flexible form modeling
-
Page[72] takes after both Smeed's 1949 model of road deaths and Peltzman's 1975 model of road deaths and injuries in that, studying yearly fatalities with an international data set, he likewise uses the Log-Log regression form while increasing the number of explanatory variables from Smeed's 2 to 7 (Peltzman had 5 plus a trend). He also claims[73] that the next decisive step in modeling after Peltzman occurred with the monthly DRAG-1 model of 1984, which included both multiple-outcome specifications (e.g. deaths; injuries by category; no injury), with those outcomes decomposed (e.g. between road use in vehicle-km, accident frequency per vehicle-km and severity per accident), and all equations estimated with Box-Cox transformations. But, despite his knowledge of the tradition of multinational specifications and of regression forms, Page did not try to model any maxima over the period 1980−1994 or to use flexible Box-Cox forms, which can also dominate fixed Linear and Logarithmic forms in yearly models (e.g. for the USA[18,74,75]). On this point, there might be an unexplained difference between monthly models, where optimal forms are never logarithmic and yearly models, where they often are (like here).
Our problem statement
-
With that background and context, our problem is simply stated: if Vehicle-km kept increasing after the 1970−1974 peak of Fatalities (and of Injuries, most of the time) in 18 industrialized countries and if road use was barely affected by the oil crises of October 1973 and 1979−1981, why did Fatalities (and often Injuries) start falling, as in Fig. 11 showing sums for the 12 countries [Despite efforts, some variables found in the database are unavailable for some countries, thereby limiting the sample] retained for our tests? In it, note growth rates of the indicators over the period decreasing successively with Vehicle-km, GDP per capita, Injured victims and Killed victims. [This is of course in part due to the fact that 9 of the 12 retained countries, Canada included, have their maxima of fatalities during the lustrum years 1970−1974, the exceptions being the UK (1965), Sweden (1966) and Spain (1989). All countries that have a maximum of fatalities during lustrum years have simultaneous injury maxima, except Canada], in that order. Our regression sample period is always 1965−1999 and its content is always that of the 12 countries plus the Province of Quebec, all 13 of which are greyed in the first column of Table 4.
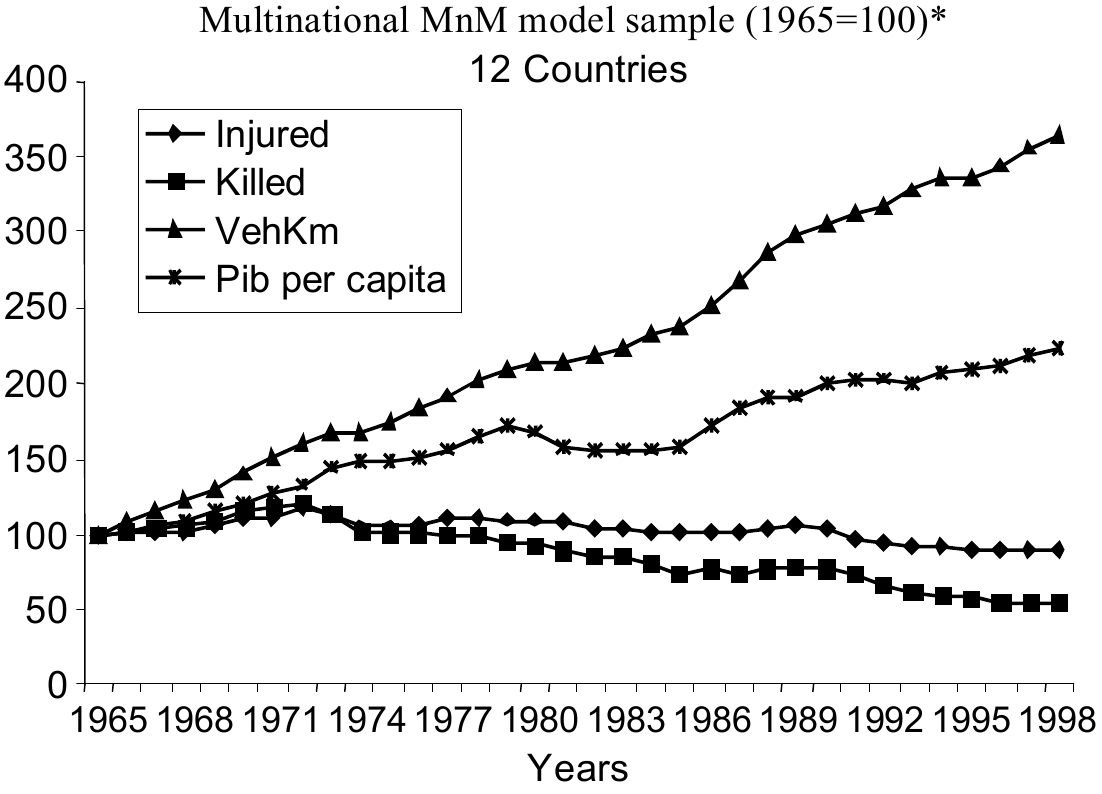
Figure 11.
Indices of road use, GDP per capita, and killed or injured victims in our sample. * The 12 OECD countries selected in Table 4 (1965−1998 data).
A multinational model
-
To test the new hypothesis and obtain a natural, non-imposed, maximum from a naturally turning (non-monotonically increasing or decreasing) variable, we suitably modify the (multinational) MnM-1 model specification[19] that previously failed to correctly account for fatality and injury peaks by inclusion of a turning form of type (3) on the Vehicle occupancy ratio (Population/Vehicle) explanatory variable.
Although Table 5 proposes much more than a dozen candidate countries for the estimation sample, and the documented MAYNARD-DRAG database is relatively complete for many countries, the latter does not cover all of the countries listed in the table (Israel, for instance) and may be incomplete for some countries covered. The size of the estimation sample will then depend on two model specification dimensions: the number of retained explanatory variables and the number of explained variables. Concerning the first, there exist for instance no Vehicle-km data for Luxembourg, Hungary or Greece; concerning the second, our desire to explain Morbidity and Injured victims rules out countries where the definition of injuries has notoriously changed (cf. Appendix 1), such as Australia (in 1979−1980) and the United States of America (in 1971−1972). One ends up with 12 countries (and Quebec).
Our MnM-2 specification, borrowed from that of MnM-1 to which the new I variable will be added, and estimated with the L-1.4 algorithm[76] implemented in Version 2.0 of TRIO[77], is consequently as follows:
i) The retained DRAG-type decomposition is: (Frequency) × (Severity) = (Victims). One then obtains five distinct equations: one for Accident frequency (the sum of fatal and non-fatal bodily injury accidents), two for Morbidity (Injured victims per bodily injury accident) and Mortality (Killed victims per bodily injury accident) rates and two more for the products of the frequency and severity terms, Injured and Killed victims. The application of Box-Cox transformations, in accordance with (1), to the dependent and up to five groupings of explanatory variables never led to really clear and significant gains over the logarithmic form, which was then retained for all equations, except for the significant heteroskedasticity correction (4) in some of the equations;
ii) The retained explanatory variables common to all five equations, listed in Table 3, belong to familiar categories in road safety models. We have added to category A our new Road traffic intensity of GDP variable I. Here GDP per capita is the key determinant of the demand level, in contrast with monthly DRAG-type models which use Vehicle-km (which here is uncorrelated (+0.01) with GDP per capita but is correlated (+0.90) with Road traffic intensity of GDP). When the inverse of Smeed's N/Population was added, it was never statistically significant and was not retained. An intercept guarantees invariance of BCT estimates to units of measurement of the Xk and Zm[78];
iii) Tests of heteroskedasticity were performed with[79]:
${u_t} = {\left[ {\exp \left( {\sum\nolimits_m {{\delta _m}Z_{mt}^{({\lambda _m})}} } \right)} \right]^{1/2}}\;{v_t} $ (4) and the Zm variable Vehicle-km found to make a significant contribution in three of the five equations;
iv) For each equation, we have performed Box-Jenkins analyses. At first, of the existence and stationarity of the constant variance residuals vt assumed to follow a multiple-order process
$ {v_t} = \sum\nolimits_{\ell = 1}^{\ell = r} {{\rho _\ell }} {v_{t - \ell }} + {w_t} $ (5) and, after correction, of the final residual wt to guarantee that a white noise had been obtained.
Autocorrelation and heteroskedasticity have not been dealt with previously in multinational yearly models, although Page[72,73] reported that he tended to obtain first differences (ρ1 = 1 in (5)) in his exploratory trials and consequently assumed ρ1 = 0 to avoid this predicament. We found some significant 1st order estimates in three of the five equations, but no 2nd order ones. Contrary to Page's result, all three of these 1st order processes are stationary, but barely so with values of ρ1 between 0.95 and 0.97;
v) The t-statistics of all βk and δm were computed conditionally upon the optimal values[80] of the BCT by a method of first derivatives[81] that avoids unit of measurement and other rescaling pitfalls[82];
vi) The tested specification for the five equations, for any given country
$i = 1,...,13$ $t = 3,...,35$ $\begin{aligned}& \left[ {\frac{{y_{i,t}^{({\lambda _y})}}}{{\sqrt {\exp ({\delta _Z}Z_{i,t}^{({\lambda _Z})})} }} - \sum\limits_{\ell = 1}^{\ell = 2} {{\rho _\ell }\frac{{y_{i,t - \ell }^{({\lambda _y})}}}{{\sqrt {\exp ({\delta _Z}Z_{i,t - \ell }^{({\lambda _Z})})} }}} } \right] =\\& {\beta _0}\left[ {\frac{1}{{\sqrt {\exp ({\delta _Z}Z_{i,t}^{({\lambda _Z})})} }} - \sum\limits_{\ell = 1}^{\ell = 2} {{\rho _\ell }\frac{1}{{\sqrt {\exp ({\delta _Z}Z_{i,t - \ell }^{({\lambda _Z})})} }}} } \right] + \\ &({\beta _i} - {\beta _r})\left[ {\frac{1}{{\sqrt {\exp ({\delta _Z}Z_{i,t}^{({\lambda _Z})})} }} - \sum\limits_{\ell = 1}^{\ell = 2} {{\rho _\ell }\frac{1}{{\sqrt {\exp ({\delta _Z}Z_{i,t - \ell }^{({\lambda _Z})})} }}} } \right] + \\ &\sum\limits_{k = 1}^K {{\beta _k}\left[ {\frac{{X_{ki,t}^{({\lambda _k})}}}{{\sqrt {\exp ({\delta _Z}Z_{i,t}^{({\lambda _Z})})} }} - \sum\limits_{\ell = 1}^{\ell = 2} {{\rho _\ell }\frac{{X_{ki,t - \ell }^{({\lambda _k})}}}{{\sqrt {\exp ({\delta _Z}Z_{i,t - \ell }^{({\lambda _Z})})} }}} } \right]} + {w_{i,t}} \end{aligned} $ (6) where
${\beta _r}$ vii) The optimal forms of
${\lambda _y}$ ${\lambda _X}$ ${\lambda _Z}$ Table 8. Initial MnM-2 model for 12 countries and Quebec, 1965−1999, 455 observations.
Column 1 2 3 4 5 I. Sample elasticity (conditional t-statistic) Variant = acc7 mbe7 mte7 ble7 tue7 Version = 23 4 4 6 4 DEP. VAR. = Accidents Morbidity Mortality Injured Killed P - Price Minimum price per li of ordinary gazoline PrixEss −0.052 0.001 0.071 −0.087 −0.088 (−2.98) 0.08 1.73 (−3.83) (−2.81) M - Motorization Percentage of cars in the total of vehicles PctAuto 0.114 −0.118 0.807 0.166 0.274 −0.75 (−2.58) 3.66 1.00 1.34 Urban population (% of total population) PctUrban 1.044 0.103 0.548 1.847 1.055 (1.17) (1.42) (2.05) (2.09) (0.99) N-L - Network-Regulations Highway speed limit HwySpeed −0.023 −0.014 −0.241 −0.018 −0.069 (−0.86) (−0.57) (−2.68) (−0.63) (−1.64) SeatBelt regulations SeatBelt −0.029 0.000 −0.101 −0.036 −0.043 === (−2.19) (0.00) (−3.64) (−2.85) (−2.00) Y - Socio-economic Percentage of the population 65 and older Pop65 0.192 −0.052 −0.661 0.240 0.529 (0.62) (−3.28) (−6.71) (0.63) (1.09) Proportion of the population 18-24 years old PopYoung 0.305 −0.082 0.444 0.137 0.342 (3.61) (−7.35) (5.97) (0.96) (1.84) A - Economic activity GDP per capita PibCapit 0.310 −0.029 −0.421 0.478 0.501 (3.78) (−3.53) (−8.70) (4.61) (3.83) ETC.- Other Leap year AnneeBis 0.002 −0.001 −0.001 −0.001 0.001 === (0.75) (−0.31) (−0.05) (−0.31) (0.11) CS – Country-specific and Climate See Appendix 4 Regression Constant CONSTANT − − − − − (0.44) (1.54) (0.16) (−0.53) (−0.97) DELTA coefficient in Heteroskedasticity structure Vehicle-Kilometer VehKm −0.000 −0.002 −0.019 (−5.97) (−10.96) (−3.08) II. Parameters Heteroskedasticity Structure BOX-COX Transformations: Unconditional [t-statistic = 0] and [t-statistic = 1] LAMBDA(Z) VehKm 7.469 −0.061 3.729 [t = 0] [4.37] [−0.27] [2.23] [t = 1] [3.79] [−4.75] [1.63] Autocorrelation Order 1 RHO 1 0.953 0.967 0.974 (86.09) (75.98) (116.80) III. General Statistics LOG-Likelihood −3970.60 867.981 1624.209 −4146.47 −2794.25 PSEUDO-R2 : - (E) 0.997 0.847 0.870 0.996 0.992 - (L) 0.999 0.885 0.916 0.999 0.999 - (E) Adjusted for D. F. 0.997 0.837 0.863 0.996 0.992 - (L) Adjusted for D. F. 0.999 0.878 0.911 0.999 0.998 Average Probability (Y = limit observation) 0.000 0.000 0.000 0.000 0.000 SAMPLE - Number of observations 429 429 429 429 429 - First observation 27 27 27 27 27 - Last observation 455 455 455 455 455 Number of estimated parameters - Fixed Part : BETAS 24 24 24 24 24 BOX-COX 0 0 0 0 0 Associated dummies 0 0 0 0 0 - Autocorrelation 1 0 0 1 1 - Heteroskedasticity Deltas 1 1 0 0 1 BOX-COX 1 1 0 0 1 viii) All results were carefully checked for robustness with respect to multicollinearity using Belsley-Kuh-Welsh[84] indices as duly reinterpreted[85];
ix) Neglecting region subscripts, the Rosett-Nelson[86] model with Gauss-distributed
$N \sim (\sigma _w^2,I)$ ${w_t}$ $\Lambda \, = \,\prod\limits_{t = 1}^T {\frac{1}{{\sqrt {2\pi \sigma _w^2} }}} \exp \,\left( { - \frac{{w_t^2}}{{2\sigma _w^2}}} \right)\,\left| {\frac{{\partial {w_t}}}{{\partial {y_t}}}} \right| $ (7) where
$\left| {\partial {u_t}/\partial {y_t}} \right| = y_t^{_{{\lambda _y} - 1}}$ Table 9. Enriched MnM-2 model for 12 countries and Quebec, 1965−1999, 455 observations.
Column 1 2 3 4 5 I. Sample elasticity (conditional t-statistic) Variant = acc7 mbe7 mte7 ble7 tue7 Version = 22 3 3 5 3 DEP. VAR. = Accidents Morbidity Mortality Injured Killed P - Price Minimum price per li ordinary gasoline PrixEss −0.049 0.008 0.069 −0.073 −0.079 (−2.58) (1.02) (1.65) (−2.85) (−2.46) M - Motorization Percentage of cars in PctAuto the total of vehicles PctAuto 0.106 −0.069 0.805 0.122 0.112 (0.74) (−1.60) (3.65) (0.77) (0.56) Urban population (% of total population) PctUrban 1.020 0.094 0.547 1.707 0.132 (1.10) (1.25) (2.04) (1.90) (0.12) N-L - Network-Regulations Highway speed limit HwySpeed −0.009 0.009 −0.246 −0.002 −0.006 (−0.33) (0.37) (−2.70) (−0.07) (−0.16) SeatBelt regulations SeatBelt -0.027 -0.004 -0.100 -0.033 -0.039 === (−1.95) (−0.92) (−3.55) (−2.59) (−1.79) Y - Socio-economic Percentage of the population 65 and older Pop65 0.207 −0.134 −0.632 0.161 0.645 (0.65) (−5.35) (−4.82) (0.42) (1.46) Proportion of the population 8−24 years old PopYoung 0.323 −0.064 0.438 0.195 0.297 (3.89) (−5.36) (5.71) (1.33) (1.65) A - Economic activity GDP per capita PibCapit 0.571 −0.010 −0.425 0.718 1.718 (5.99) (−1.07) (−8.56) (6.67) (7.19) Road traffic intensity of GDP RtiGDP 0.272 0.042 −0.018 0.300 1.290 (6.13) (4.40) (−0.34) (6.33) (5.94) ETC. - Other Leap year AnneeBis 0.002 −0.001 −0.001 −0.001 0.002 (0.86) (−0.52) (−0.05) (−0.24) (0.31) CS – Country-specific and Climate See Appendix 5 Regression constant CONSTANT − − − − − (0.44) (1.54) (0.16) (−0.53) (−0.97) DELTA coefficient in Heteroskedasticity structure Vehicle-Kilometer VehKm −0.001 0.027 −0.708 (−6.50) (−11.15) (−4.91) II. Parameters Heteroskedasticity structure BOX-COX transformations: unconditional [t-statistic = 0] and [t-statistic = 1] LAMBDA(Z) VehKm 6.764 0.033 0.723 [t = 0] [4.70] [0.15] [2.14] [t = 1] [4.01] [−4.37] [−0.82] Autocorrelation Order 1 RHO 1 0.958 0.970 0.991 (111.70) (93.74) (369.51) III. General statistics LOG-likelihood −3963.48 879.288 1624.269 −4138.26 −2766.18 PSEUDO-R2 - (E) 0.997 0.854 0.870 0.996 0.993 - (L) 0.999 0.891 0.916 0.999 0.999 - (E) Adjusted for D.F. 0.997 0.845 0.862 0.996 0.993 - (L) Adjusted for D.F. 0.999 0.884 0.911 0.999 0.999 Average probability (Y = limit observation) 0.000 0.000 0.000 0.000 0.000 Sample - Number of observations 429 429 429 429 429 - First observation 27 27 27 27 27 - Last observation 455 455 455 455 455 Number of estimated parameters - Fixed part · BETAS 25 25 25 25 25 · BOX-COX 1 0 0 0 0 · Associated dummies 0 0 0 0 0 - Autocorrelation 1 0 0 1 1 - Heteroskedasticity · DELTAS 1 1 0 0 1 · BOX-COX 1 1 0 0 1 -
The initial specification and its results listed in Table 8 are representative of yearly models principally because the variable GDP per capita is included as implicit generator of road demand, and therefore of accidents and victims. In Table 9, the newcomer I variable, Road traffic intensity of GDP, is simply added without any other change to the specifications. Results are in 3 parts:
i) Part I. presents elasticities of y and t-statistics of the regression coefficients. When the code name of the variable is underlined twice (for instance SeatBelt in Tables 8 & 9 or Country-specific Dummies in Appendices 4 and 5), the elasticity measure approximates, for a variable containing some null observations, the discrete percentage impact on y of the presence of the variable. The expressions used to estimate these discrete 'elasticities' are from a paper[87] where a thorough 10-page summary of elasticity notions for all types of explanatory variables is found.
Note that all signs are reasonable, at least for the equations for Accident frequency, Injured and Killed victims for which we have anticipations, and no doubt correct for the two Severity equations for which sign anticipations are unclear: indeed, our sign intuition is typically more about accident frequency and victims than about severity rates. It is then very interesting to see how some variables, like the pair of population age share variables, can have their most important impacts on the severity of accidents and not on their frequency or victims.
In Appendices 4 and 5, the Average yearly temperature is a very significant factor in the explanation of the frequency of accidents and of the number of victims, a result which is consistent with results of monthly national time series models where temperature variations across months of the year are significant generators of similar outcomes.
As the number of victims by category is the product of the accident frequency by particular severity rates by category, the sum of their elasticities theoretically would equal the elasticity of the number of victims of that category if it were not estimated within its own equation. We therefore provide here two ways of making sense of the elasticities of variables on victims: directly estimated or resulting from the sum of frequency and severity elasticity estimates.
ii) Part II contains parameters estimated to compensate for heteroskedasticity and autocorrelation. Note that two t-statistics are supplied for the λz from (4): with respect to 0 and to 1.
iii) Part III lists general statistics, including maximized Log-Likelihood (LL) values and the selected estimation sample size [The sample for estimation starts at observation 27 because, with 13 regions and the 455 observations stacked by year and region (year 1, region 1,…, region 13 ; … ; year 35, region 1,…, region 13), estimation of second order autocorrelation in (6) requires use of the first 26 observations. Starting the estimation at observation 14, in view of the absence of second order autocorrelation, and thereby increasing the estimation sample by 3%, made little difference. Each year, the 13 region values appear in the same order (indicated in Table 4 and in Appendices 4 and 5)].
Summary of key results
-
Note in summary Table 10 that adding the variable Road traffic intensity of GDP increases the LL considerably (except in the Morbidity equation, a result neither expected nor surprising) and also clarifies the role of the GDP per capita variable, i.e. its elasticity and t-statistic.
Table 10. Impact of adding the I variable on the Log-Likelihood and on the GDP per capita elasticity.
(All values are drawn from Tables 8 & 9) Accidents Morbidity Mortality Injured Killed LL of reference model (Table 8) −3,970.60 867.981 1,624.209 −4,146.47 −2,794.25 LL of enriched model (Table 9) −3,963.48 879.288 1,624.269 −4,138.26 −2,766.18 Gain in LL (one degree of freedom) 7.12 11.30 0.06 8.21 28.07 Elasticity with respect to GDP per capita (Table 8) 0.310 −0.029 −0.421 0.478 0.501 (t-statistic) (3.78) (−3.53) (−8.70) (4.61) (3.83) Elasticity with respect to GDP per capita (Table 9) 0.571 −0.010 −0.425 0.718 1.718 (t-statistic) (5.99) (−1.07) (−8.56) (6.67) (7.19) Gain in t-statistic (of GDP per capita) 2.21 −2.48 −0.14 2.06 3.36 Elasticity with respect to Road traffic intensity of GDP (Table 9) 0.272 0.042 −0.018 0.300 1.290 (t-statistic) (6.13) (4.40) (−0.34) (6.33) (5.94) Column 1 2 3 4 5 The contribution of Road traffic intensity of GDP
-
The results gathered in Table 10 demonstrate that it is bad economics to neglect the role of intermediate output indicators, and to limit oneself to final output ones, in explaining national road safety performance for the 35 years of economic growth from 1965 to 1999. Although we cannot here expect the single yearly indicator I of Total to Final output activities to yield as refined a contribution as that of 5−10 distinct intermediate and final monthly factors used in monthly models, results obtained are still completely convincing. Indeed, the addition of I dramatically boosts LL estimates in all equations except that of Mortality (Column 3). It is noteworthy that the fit of Morbidity (Column 2) is so much improved, but we limit our supplementary comments on residuals to the more intuitive Accident (Column 1), Injured (Column 4) and Killed (Column 5) equation dimensions. For this, we look at ratios of residuals wt before and after adding I.
Although residuals of any equation always have a mean of 0, by construction, the ratios of their initial to enriched values shown in Fig. 12 can tell us much about the source of LL gains imputable to the added I variable. LL fit notably improves by reducing some relatively high error values of the lustrum period: (i) in the equation for Accidents (Part A), the addition of I corrects mostly one-sided outliers, one of which, in 1971 (for Quebec), is 16 times higher before than after correction; (ii) in the equation for Injured victims (Part B), the addition of I corrects an error of 1972 that is 46 times higher than before the correction and another one of 1970 that is 30 times smaller (both of which pertain to The Netherlands); (iii) in the equation for Killed victims (Part C), the addition of I corrects residuals in both directions, one of which (for Norway) in 1974 is 37 times higher before correction.
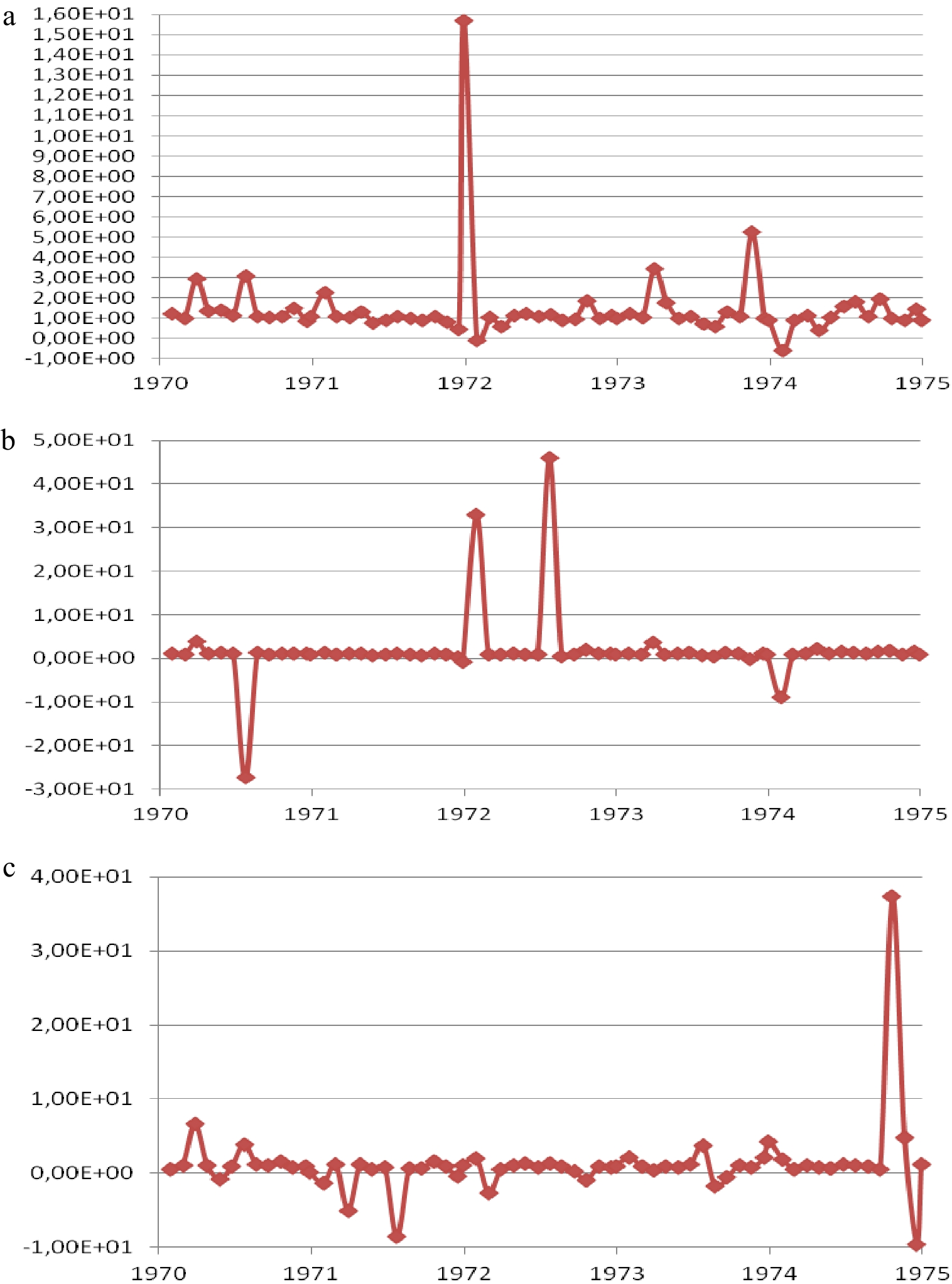
Figure 12.
Ratio of initial to enriched residuals wt during the five lustrum Matterhorn years 1970−1974. (a) Accident equation, 65 observations for the Matterhorn period, 13 regions per year for 5 years (1970−1974)*. (b) Injured equation, 65 observations for the Matterhorn period, 13 regions per year for 5 years (1970−1974)**. (c) Killed equation, 65 observations for the Matterhorn period, 13 regions per year for 5 years (1970−1974)***. [* The average ratio of initial to enriched Accident errors values for the full estimation sample period (1967−1999) is 0.96. ** The average ratio of initial to enriched Injured errors values for the full estimation sample period (1967−1999) is 1.14. *** The average ratio of initial to enriched Killed errors values for the full estimation sample period (1967−1999) is 0.32.]
Discussion: lustrum period spurts in Fatalities and in the Fatality intensity of traffic
-
It is one thing to claim that, in the absence of the proper macroeconomic indicators of intermediate output activities constructed in monthly models to accompany final activity generators (cf. Table 1), yearly models have to do just with I, Road traffic intensity of GDP, at least during the post WW II years that include the clustered peaks in road fatalities, but it is another to claim that this proxy could be readily used on a secular basis in just the same simple way. On this, our lustrum period of interest, seen until now as a time of global national maxima of road fatalities, also needs to be positioned as a special sub-period bout with respect to some known evolutions of the Fatality intensity of traffic.
This statistic is available since 1845 for France and since 1900 for the USA, as shown in Fig. 5, where both indicators measure the Fatality intensity of road traffic, but for France the mostly quintannual data cover all road deaths (by horse or hippo-mobile included), in contrast with the yearly motor vehicle USA series (which excludes horse crash data). The share of horse-linked deaths (not shown in this figure) fell steadily from almost 100% in 1910 in the USA and in France, for which the source of Fig. 5a notes that it was still 14,85% in 1937, the average year for 1935−1940.
Neglecting road injuries warranting medical attention and remaining focused for simplicity only on road deaths, it is important to note first that the national peaks in Fatalities of Fig. 6, objects of our specific inquiry, also imply peaks in the Fatality intensity of traffic (in deaths per vehicle-km) during the same 1970−1974 period: they are clearly visible for both countries in Fig. 5.
Seeking an interpretative framework to distinguish between special periods and the long term
-
To discuss the positioning of our 1970−1974 spurt in both Fatalities and Fatality intensity of traffic, we distinguish two long periods, namely 1910−2010 and 1845−1910. Our problem is to set our sub-period of interest within its very long background and, in view of the lack of explanations for the trending evolutions over those long periods, to propose an interpretative framework whereby Road traffic intensity of GDP has more than a palliative role in explanations of secular fatality intensity indices.
Essentially, using I per force as proxy for the ratio of Total (intermediate and final) to Final output makes sense for the period of the post WW II peak in road fatalities of interest here [Although some authors[88] included Miles as explanatory variable, yearly models, constrained by the absence of intermediate output measures, never conceived of, or estimated, distinct GDP and I effects proper. These could have been derived from log forms of GDP, Miles and the ratio of Miles to GDP in order to bring out, like us, the role of non final economic activities. All such models therefore implicitly assumed that intermediate output is proportional to final output.], as it would to explain the USA post-Great Depression surge, but the matter would be more complicated over long periods. To see this, assume that the information on intermediate output becomes available and that one can suddenly construct yearly ratios of Intermediate to Final, or of Total to Final, economic output.
Clearly, periods of fast industrialization may imply that both of these ratios of intermediate to final or of total to final economic output increase without much effect on I if mode choice and vehicle carriage capacity dampen, or go in the opposite direction of, impacts of macroeconomic structural change. Furthermore, the link between I and the Fatality intensity of traffic will depend crucially on vehicle density (congestion) on the road network. Consider the most recent long period of 1910−2010 first, for which there are reasons to think that congestion has increased progressively in France and in the USA, and contrast it to the previous 1845−1900 period for France for which there are grounds to think that congestion decreased in spite of strongly increasing intermediate to final economic output changes.
Bumpy 1910−2010 Fatality intensity of traffic trends
-
It is difficult to explain these two national declines in rates of more than an order of magnitude from 1910 to 2010 and there exists no real body of commentary on them, and naturally no consensus on how the diffusion of the automobile caused them.
To understand the difficulty, consider the USA where the death rate per mile of motor vehicles shown in Fig. 5b falls yearly by 3.6% on average between 1909 and 2012 but exhibits sub-periods of contrary upswings, such as the 1932−1935 post-Great Depression spurt and the big bulge of the 1960s. The author gratuitously imputes the fall of the index by a factor of 3 over the early period 1909−1926 to 'improvements in automobile quality and the first round of improved highways' (p. 386). This is unconvincing because the USA had a large high-quality network of paved roads before cars even appeared. In 1904, there were 154,000 miles of paved roads for 55,000 cars[89,90], which amounts to about 100 times the amount per car to-day, because 'road infrastructure development preceded the diffusion of the automobile'[70] (p. 127). Strangely, he is also silent on any changes in the structure of Total to Final economic activity associated with the visible post-Great Depression spurt and with the long 1960−1970 bulge, ignoring obvious trend reversals.
By his stated logic for the 1909−1926 drop, that last 1965−1972 surge should presumably be partly imputed to worsening automobile quality and worsened highways ̶ during the very decade of innovative safety regulation and diffusion for new vehicles (lap and shoulder belts; energy-absorbing steering columns, high penetration resistance (HPR) laminated windshields, padded instrument panels, dual braking systems) and of the deployment of the interstate highway system (1962−1969)!
And the argument that a large network of paved roads preceded the diffusion of the automobile can also be made for France, where the indicator in Fig. 5a also falls strongly after a rise from 1900 to 1910 resembling the American one during the earliest diffusion [Sales of Ford's Model T started only in 1908, with 5,986 units, and reached 260,720 units by 1913[91]] of the automobile in both countries.
Basing the 1910−2010 trend on factors other than better driver-vehicle-way interactions
-
What is amiss if better vehicle-and-way incantations obviously fail to explain the trends since 1910? Could it rather be that, in both countries since 1910, progressively higher automobile traffic densities (congestion, reducing feasible speeds) [This role of congestion, understood as higher traffic density, is modelled in TRULS-1[60−62] estimated from a panel data set (of 5016 monthly observations on the 19 counties of Norway, 1973−1994), by use of the variable Vehicle-km per km of road per month per county] on pre-existing relatively good paved roads and the substitution of automobiles for horses and their carriages (reducing vehicle heterogeneity and the much higher hippo-mobility risk/km) combined with decreasing traffic intensities of GDP and other secular factors (e.g. gradually lower occupancy of vehicles, but not better driver-vehicle-way interactions) to yield the secular slope trend, except for sub-periods of high traffic intensities of GDP like 1970−1974?
By contrast, during the 1845−1900 period, there was an almost five-fold increase in the index of Fig. 5a in France. That was a time of intense industrialization and growth of road passenger and freight intensities of GDP (in Fig. 13b), and no doubt of increasing intermediate to final economic output, but, surprisingly, of falling Road traffic intensity of GDP (in Fig. 13g) allowing for higher speeds of progressively heavier vehicles. Decreased I (reducing Fatality intensity of traffic) would hypothetically have been more than offset by lower congestion, i.e. increased speeds (inducing the opposite), leaving remarkably uncongested networks available for the rise of the automobile in 1900.
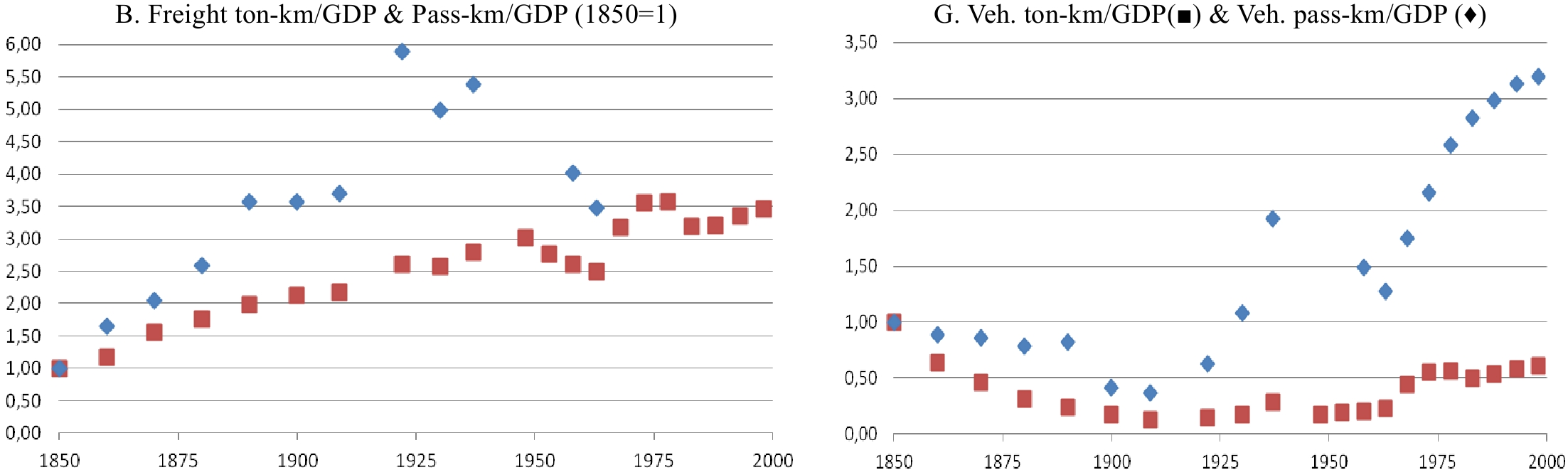
Figure 13.
Road flow and vehicle intensities of GDP (ton-km & pass-km), France 1845−2005. Source: Gaudry[24] (Fig. 2, p. 6), where the transformation from flows in B to vehicles in G is described in detail.
Vehicle traffic intensity of GDP and traffic density (congestion) could then be basic trends of opposite signs and with joint effects independent from any hypothetically lower rates of occupancy of vehicles or from better driver-vehicle-way interactions. In France the period 1845−1900 would have seen lower I (with some spurts) and decreasing congestion but the period 1910−2010 lower I (except for special sub-periods spurts) and increasing congestion. I is an imperfect substitute for the Total to Final output ratio.
Opposite effects of economic development on road safety
-
Two distinct features of economic development are conceivably also at work. First, increases in real GDP imply a slowly increasing share of services which gradually reduces the relative need for intermediate and predominantly physical supply chains and their intermediate transport flows; second, the ratio of Intermediate or Total (intermediate and final) to Final output can shift this base trend up or down, creating periods of trend reversal or acceleration. In all 18 OECD countries of Fig. 6, the accelerated diffusion of private car ownership after 1970 contributed to a higher share of services in final demand despite a general slowdown in public road building investments after 1967 ̶ as Intermediate output was also booming.
A tentative story of hewers of wood or coal and drawers of water
-
It is then possible to make some tentative sense of seemingly erratic secular series on the transport intensity of GDP and on its road traffic intensity I in particular, the latter fluctuating partly with vehicle capacity and with the intermediate to total output ratio of the Economy? Consider a development story.
Once upon a time, discretionary personal travel (i.e. visiting friends and relatives, trips to second homes, tourism) did not exist, except perhaps for the extremely rich. All travel could then be deemed 'essential', either to go to work or to market places (a final transport demand, in national accounts) or as part of work itself to produce the transport flows (an intermediate transport demand in input-output analysis) needed for inter-firm or inter-sector trade operations. Supply chains were predominantly physical (with human life often 'short and brutish') because the share of services or dematerialized consumption in final output was low, but increasing very slowly with development based on industrialization and with accompanying urbanization, both gradually emptying farms.
In 1845 France, for instance, it was frequent for people living in a part of town seldom to go for instance downtown, or never to visit even their own attractive national capital city, be it Paris. Life was all low-paid work without leisure and all travel (notably occupational) was dangerous, as measured by indices of fatalities per unit of distance travelled ̶ by any mode and by all modes. From this low GDP per capita base, growth required a relatively large quantity of material input which generated relatively high derived intermediate input and transport demand, causing the ratio of Intermediate to Total output to increase until about 1900 (as implied in Part A of Fig. 5 and shown in Fig. 13b) when a major turn occurred, just before the automobile regenerated, if it did not invent, personal travel.
Industrialization itself implied higher Intermediate to Total output, a higher I under constant modal shares and effects on economic inequality[92]. But, during the last 150 years, there were significant ups and downs in the actual ratio of Intermediate to Total output, and consequently in I. To be less tentative would require more historical data on output, modes, flows, traffic and congestion.
-
We have developed, within the framework of aggregate yearly road safety models, a new explanation of the extraordinary occurrence in OECD countries of 18 national road fatality maxima clustered during the 5-year period 1970−1974 (including 11 in 1972−1973), referred to as 'The Matterhorn', a new name for the 1997 'The mystery of 1972−1973'[47].
We have claimed that, in the long years since that diagnostic was made, no convincing explanation has been proposed of the existence of such national maxima in general and of their joint occurrence in particular. This despite significant research of common causes (e.g. congestion, baby boomer drivers' wave, new speed limits, new belt use laws, etc.) and despite resort to dodges (such as sigmoid time trends, splines and strict or flexible quadratic forms) imposed to induce a turning point of road safety performance, especially of fatalities. Such artificially forced turns were often based on GDP per capita but also on other variables such as the inverse of Smeed's vehicle availability (N/Population) interpreted as a vehicle occupancy rate. Complementarily, in the absence of a clear culprit or of 'a good idea' concerning the reasons for maxima and their clustering, it has also been much more difficult to explain the downward trends themselves, or the stagnations, in yearly national fatality and injury tallies expressed absolutely or as rates normalized by population or vehicle use.
Basic input-output economics and transport flows
-
As proposed recently[45,93,94], we have accounted for The Matterhorn by enriching with I, Road traffic intensity of GDP, a representative aggregate model using Gross Domestic Product (GDP) per capita as key determinant of road accident and victim levels. Defined as road vehicle-kilometers per unit of constant GDP, I has stood as proxy for the relative level of total to final activity in The Economy. Indeed, because its numerator reflects transport demand for all economic activities, intermediate and final, which have long successfully intervened in a number of monthly road safety models, I can mimic natural up-and-down variations in total (intermediate and final) to final output, at least during our special spurt of clustered fatality peaks.
The usefulness of road safety outcome decompositions
-
We have explained both the presence of road fatality maxima in a number of countries (and to some extent of maxima in injuries, simultaneous with those of fatalities in the majority of cases) and their clustering in OECD countries between 1970 and 1974 using a representative yearly DRAG-type decomposition with total bodily injury accidents (the sum of fatal and not fatal occurrences), their severity rates per accident (morbidity and mortality), and their victims by category (injured, killed). This has revealed effects differentiated by dimension.
An economic spine in lieu of splines
-
The gains resulting from the addition of the new naturally turning variable I have been spectacular and have led us to expect that various forms of transport intensity of GDP might contribute to the explanation of other peaks in transport fatalities, for instance that of air victims which occurred also in 1972−1974[95] and may have been partially caused by a related spurt in air traffic intensity of GDP. For countries where road fatalities have yet to peak, the next analytical safety work task is that of forecasting the profile of Intermediate to Final output in the economy of the country; it is not to collect guesses by local road safety experts on the future long-term evolution of current local indicator trends.
Road traffic intensity of GDP has a multi-secular history
-
We have also distinguished between I during The Matterhorn sub-period and during the last 175 years of variations associated with industrialization and urbanization. As Matterhorn lustrum times run counter to a downward trend in the Fatality intensity of road traffic observable since 1910 in France and the USA, we have proposed a tentative conceptual list of checkpoints, based on known secular trends, for determining whether the I proxy might make sense in another yearly road safety model tailored to a particular historical sub-period, such as the post-Great Depression spurt in the USA.
Glorious but gory
-
Overall, we noted that rising intermediate output brings out the 'bloody mathematics of our condition', as written in 1942 by Albert Camus, who died in a 1960 car accident. We have indirectly shown it to be relevant to our time of de-industrialization and delocalization of manufacturing to less economically developed countries. This no doubt also displaces many of the road safety and other negative externalities incurred by those who were there before and for whom the recent Golden 30 years of economic growth (1945−1975) were perhaps not all glory after all. This new emphasis on the link between intermediate economic output and road safety strengthens the backbone of current management of yearly safety indicators and trends, and not only in countries that have yet to see a global maximum of their fatalities.
This paper draws on three cumulative waves of research performed over the last years, all of which involved multiple researchers and students, countries, and funding sources. Firstly, the existence of the extraordinary clustering of national yearly road fatality maxima in many OECD countries in the early 1970s was diagnosed as 'The mystery of 1972−1973' in an analysis financed by Volvo AB at the invitation of the The Third International Conference on Transportation, Traffic Safety and Health (Washington, DC, USA December 2−3, 1997). Secondly, all attempts (from February 1999 to May 2002) to adequately model the peaks of road fatalities in 12 OECD countries and in 10 Canadian provinces, funded by Quebec's Fonds FCAR-MTQ-SAAQ program 'Soutien à la recherche universitaire en sécurité routière', reportedly failed. This failure was duly publicized: (i) in an 'Outstanding Presentation' at the 1st Forum of European Road Safety Research Institutes (FERSI) Scientific Road Safety Research Conference (Bergisch Gladbach, September 7−8, 2005) and at the First European Workshop on Modelling National or Regional Road Safety Performance (Arcueil, May 21, 2006); (ii) in 2009, to the team setting up the Reuben Smeed Centenary Professorial Research Associateship at University College London, UK. Wide dissemination inspired new hypotheses and reports of still more modelling failures from Stipdonk (2013) for The Netherlands, Gaudry (2014) for many countries, and even Abraham (2014) for the synchronous 1972−1974 peak in World air transport fatalities! The current third research wave, started in 2015 without funding, was helped by 2017 consulting work financed by Danmarks Tekniske Universitet (DTU) on the governance of national transport models whose workhorse Gaudry proposed the 'Road traffic intensity of GDP' hypothesis after performing collaborative key exploration tests with Fridstrøm ̶̶ who notably documented them with graphs for Norway, some of which are included here.
-
The authors declare that they have no conflict of interest.
- Supplemental Appendix 1 Death and injury indices in 26 countries, 1965-1998.
- Appendix 1
- Supplemental Appendix 2 Rates in 26 countries and Quebec, 1965-1998.
- Appendix 2
- Supplemental Appendix 3 Data used in MnM-2 model but not included in MAYNARD-DRAG database.
- Appendix 4
- Supplemental Appendix 4 Country-specific and Climate effects removed from Table 9.
- Appendix 5
- Supplemental Appendix 5 Country-specific and Climate effects removed from Table 10.
- Copyright: © 2023 by the author(s). Published by Maximum Academic Press on behalf of Nanjing Tech University. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Gaudry M, Fridstrøm L. 2023. Road traffic intensity of GDP and the explanation of national peaks of yearly road fatalities and of their clustering in 1970−1974. Emergency Management Science and Technology 3:6 doi: 10.48130/EMST-2023-0006 

Road traffic intensity of GDP and the explanation of national peaks of yearly road fatalities and of their clustering in 1970−1974
- Received: 07 March 2023
- Accepted: 22 May 2023
- Published online: 26 July 2023
Abstract: Our new explanation of the extraordinary clustered occurrence in OECD countries of 18 national road fatality maxima during the 5 years 1970−1974 consists in adding the variable ROAD TRAFFIC INTENSITY OF GDP to a basic equation specification already containing GDP PER CAPITA. The former acts as proxy for the ratio of total (intermediate and final) to final activity in the Economy. Tests of that additional factor, which peaks naturally during the period 1970−1974, are carried out using a partial DRAG-type road safety model formulation developed in 2002 by Marc Gaudry and Stéphane Gelgoot with a dozen core variables. This choice then allows for: (i) a multinational sample of 13 OECD country 1965−1999 series extracted from the public MAYNARD-DRAG database; (ii) a decomposition of their national safety outcomes (Injured and Killed victims) as products of the frequency of bodily injury Accidents by their severity (Morbidity and Mortality); (iii) an estimation of these five equations with flexible Box-Cox forms taking autocorrelation and heteroskedasticity of errors into account with the also public LEVEL algorithm of TRIO. Results from the addition of the new indicator turn out to be fully consistent with the proposed new hypothesis that the ROAD TRAFFIC INTENSITY OF GDP complements GDP PER CAPITA as key road risk generator. Overall, latent intermediate economic output de-industrialization of the OECD to less economically developed countries is shown to be a shared common phenomenon implying delocalization not only of road victims but of other negative externalities of intermediate economic production, such as CO2 emissions.
-
Key words:
- Yearly national road deaths /
- Yearly national road injuries /
- 1970−1974 cluster of national road death maxima /
- The Matterhorn puzzle /
- Road traffic intensity of GDP /
- Fatality intensity of road traffic /
- Smeed's model of yearly national road fatalities /
- Box-Cox transformations /
- Non spherical residual errors /
- European Union (EU) road safety targets /
- Société de l'assurance automobile du Québec (SAAQ) studies.