








-
Although cars have undoubtedly improved people's lives, they have also introduced higher risks of traffic accidents and fatalities due to factors like fatigue, drowsiness, and road conditions. From the past to the present, various solutions have been developed to establish the infrastructure for assisted driving (ADAS) and autonomous driving. ADAS aims to assist drivers and vehicles in identifying potentially hazardous situations and taking emergency measures to enhance the safety and comfort of the driving experience.
Deep learning-based methods have demonstrated their excellence in assisted driving tasks, including traffic sign detection[1], lane detection[2], pedestrian detection[3], and other tasks. And traffic sign detection is a crucial component of it. Traffic sign detection systems are crucial components of both intelligent transportation systems and autonomous driving systems. The accuracy and real-time performance of traffic sign detection technology are critical in enabling these systems to make informed decisions. As such, achieving a balance between real-time performance and accuracy is of utmost importance in ensuring the effectiveness of these technologies[1]. Therefore, we want to assist drivers in driving by deploying traffic sign detection on edge devices to achieve real-time detection.
The key components of traffic sign detection and recognition include feature extractor, classification, and localization of traffic signs, among which localization is focused on by researchers as a part specific to object detection. With the rapid development of deep learning technology, object detection algorithms, such as Faster RCNN, YOLO, SSD, etc. have been widely used in traffic sign detection.
In research on traffic sign detection, Wang et al.[4] proposed a deep model for traffic sign detection and recognition in complex road conditions, incorporating innovations like Coordinate Attention (CA), angle loss, SimOTA for label assignment, and a Hierarchical-Path Feature Fusion Network (HPFANet). Their model significantly improves precision, recall, and mAP over YOLOv5s, demonstrating superior performance and robustness across various datasets. Lai et al.[5] introduced STC-YOLO for traffic sign detection, enhancing YOLOv5 with advanced data augmentation, modified architecture for small object detection, and a novel feature extraction module with multi-head attention, yielding substantial accuracy gains compared to traditional approaches. Chu et al.[6] developed a model with a global feature extraction module using self-attention and a lightweight parallel detection head to enhance small traffic sign detection accuracy, supported by extensive data augmentation for improved robustness.
While deep learning methods have made some progress in traffic sign detection tasks, they still face limitations when dealing with complex natural environments and real-time edge detection. For example, when deployed to edge platforms, the inference speed is low, and the accuracy is low. To address the above problems, this paper presents several enhancement strategies based on the lightweight version of the YOLOv8 algorithm, namely the YOLOv8-CE algorithm.
(1) Coordinate Attention is a feature extraction mechanism that enables the model to better pinpoint and recognize the target area, while also capturing inter-channel connections.
(2) Changing the localization loss function to EIoU helps the model converge quickly and makes the regression process more stable, which improves the regression accuracy of the prediction box.
-
Traffic sign detection stands as a pivotal area of research in autonomous driving. Many researchers have introduced diverse algorithms aimed at classifying and identifying road traffic signs. Broadly speaking, these algorithms fall into two categories: the first utilizes traditional detection techniques such as color-based, shape-based features, and feature fusion. The second category is rooted in deep learning methodologies.
Traffic sign detection-based traditional techniques
-
Since the 1970s, a group of researchers has been working on traffic signs. Firstly, the traditional traffic sign detection, where researchers extracted features manually, such as color features, shape features, and fusion features, and performed the corresponding detection: de la Escalera et al.[7] segmented by color to extract the region of interest (ROI), and then got shape features for analysis to detect traffic signs. Fleyeh[8] first converted RGB images into IHLS color space and then used segmentation algorithms to extract the color features of traffic signs for detection. However, these algorithms are not able to obtain the expected results consistently, they face various challenges such as internal and external conditions of the traffic sign environment, the external conditions are some environmental factors such as weather conditions, lighting conditions, occlusion degradation of traffic signs, these conditions are not changeable, so some researchers try to solve these problems, but often can not take care of all the cases so the detection effect is limited. On the other hand, internal conditions are variables that can be controlled by algorithms such as response time and detection accuracy, and these series of challenges to improve accuracy and increase detection speed contributed to the development of traditional traffic sign detection. After this, with the development of machine learning, support vector machine SVMs were also applied to sign recognition, and Maldonado-Bascón et al.[9] used support vector machines (SVMs) for shape classification and content recognition.
Traffic sign detection-based deep learning
-
However, in actual driving, for high-speed vehicles, the requirements for traffic sign speed are very strict, and this method does not meet the demand for real-time detection, researchers have consequently turned their attention to convolutional neural networks. Cireşan et al.[10] were able to attain a classification accuracy of 99.15% on the GTSRB dataset through the utilization of a convolutional neural network (CNN). The arrival of convolutional neural networks (CNN) opened a new era in image processing. Since the introduction of AlexNet, CNN has been continuously optimized with increased depth and more complex structures. Its results in the field of computer vision have been extremely good. Deep learning methods have allowed traffic sign detection accuracy to be greatly improved. In comparison with traditional sign recognition methods such as color and shape and machine learning methods, better recognition and detection can be obtained, faster and can be adapted to more complex scenes.
The current mainstream detection algorithms can be classified as two-stage and one-stage. The two-stage mainly includes R-CNN[11], Fast R-CNN[12], Faster R-CNN[13], etc. The R-CNN series of algorithms first obtains the region containing the object, and then uses the classifier for classification and regression. The one stage mainly includes YOLO[14−17] as the main representative, the YOLO series algorithms directly use CNN for feature extraction and consider the task as regression to directly complete object classification and location localization.
Huang et al.[1] introduced asymptotic feature pyramid network (AFPN) into YOLOv8 with the goal of highlighting the influence of key layer features after feature fusion and solving the direct interaction of non-adjacent layers. Chen & Fan[18] introduced Multi-Scale Group Convolution to replace the C2f module and integrated Deformable Attention into the model to improve the detection efficiency and performance of complex targets. While the parameters are reduced by 59.6%, the accuracy remains at a high level. Zhang et al.[19] proposed a multi-scale traffic sign detection model, CR-YOLOv8 based on YOLOv8. By incorporating an attention module in the feature extraction stage and an RFB module in the feature fusion stage, the model enhances key features and improves multi-scale object detection with minimal computational overhead.
The advancement of convolutional neural networks has been accompanied by significant growth in the field of cloud platforms[20], but at the same time, numerous issues have arisen, making it challenging for centralized cloud services to fulfill the real-time demands of most intelligent transportation applications amidst the current deluge of big data. Therefore, transferring computing resources from cloud centers to network edge devices close to users has become an inevitable requirement for IoT technology development, real-time computing, and achieving network edge intelligence. In response to the existing situation, many researchers have started to focus on lightweight neural networks and use some lightweight methods to deploy detection algorithms to inexpensive embedded devices to achieve edge detection and share the computational pressure of the central computer. Luo et al.[21] opted to use Ghostnet as the feature extraction network. This lightweight network reduced the number of parameters and computations. The author's test results on the edge device Raspberry Pi was 790 ms. Additionally, Artamonov & Yakiomov[22] utilized the processing power of NVIDIA mobile platforms, such as Jetson TX1 and Jetson TX2, to deploy the YOLO algorithm for continuous video traffic sign detection with GPUs.
-
To better train the model and make it more generalizable, processing of the data is required. The techniques utilized in this section for handling data involve Mosaic, MixUp, adaptive image scaling, and adaptive anchor box calculation. Firstly, the data augmentation method is used in YOLOv4 to stitch four images with random scaling respectively. Then combining them into one image, which improves the detection of small objects more effectively. Then, adaptive image scaling was used to obtain a standard image of 640 × 640 for training. In addition, if the difference between the anchor box and the object size is large, the K-means algorithm was employed to find the most suitable anchor box size and use it for training. The image after data processing is shown in Fig. 1.

Figure 1.
Results of data processing.
YOLOv8
-
YOLOv8 is the most mainstream single-stage object detection algorithm. According to the depth and height of the network, it can be divided into five models YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x. As it is to be deployed to embedded devices, YOLOv8n, which has the smallest volume, is chosen as the basic network model in the present paper.
Structure of the network
-
The network architecture of YOLOv8 is illustrated in Fig. 2. YOLOv8 consists of four components: input, backbone, neck, and head.
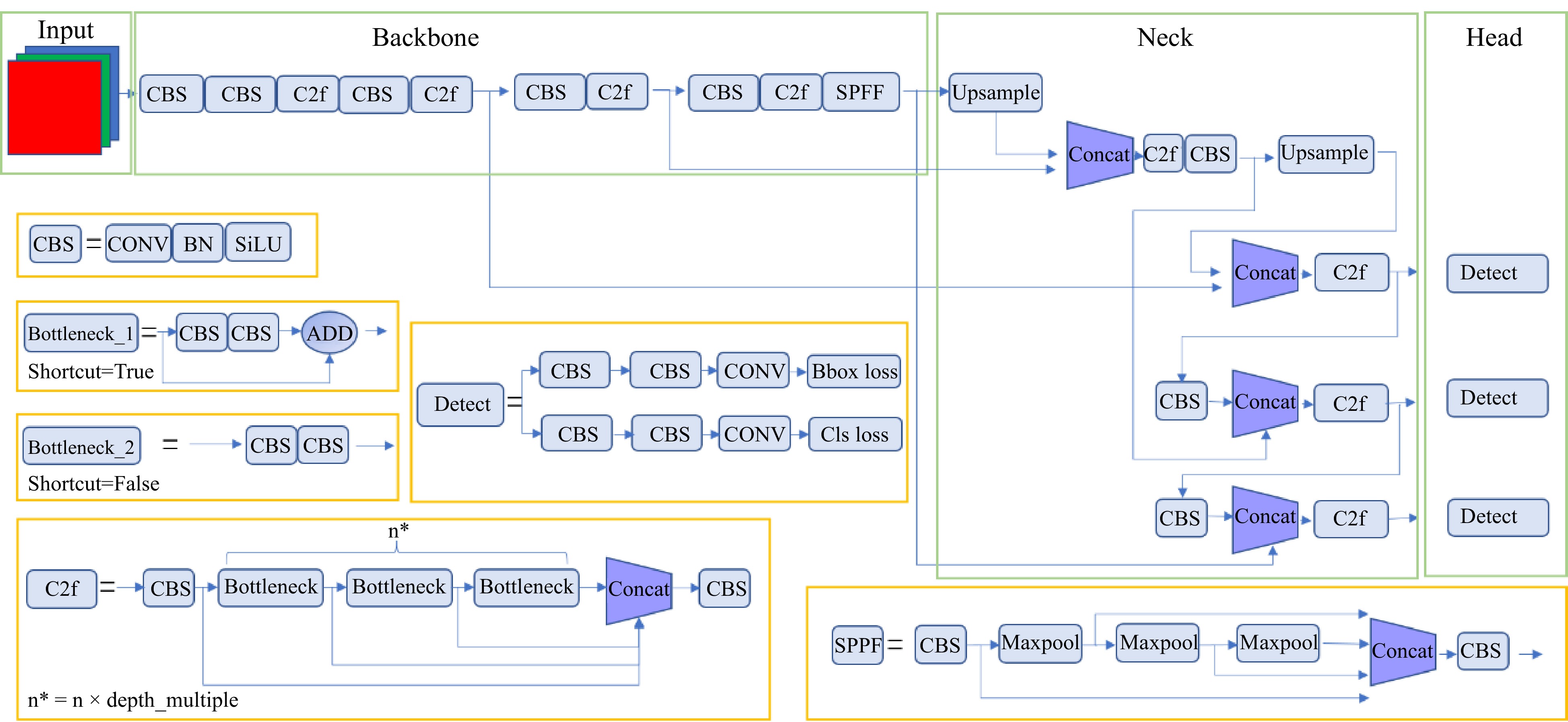
Figure 2.
Structure of YOLOv8.
Firstly, the input layer is enriched with the Mosaic data augmentation method to enrich the dataset with low hardware device requirements and the final input is 640 × 640 standard-size images.
In backbone, the core of the network consists of Conv, C2f, and SPPF modules, which are responsible for extracting features from images. The Conv module comprises a combination of Conv2d, BN, and the Swish activation function. The C2f module is an improvement over the C3 module, with adjustments to the number of channels for different scale models, representing a refined tuning of the model structure that significantly enhances performance. The SPPF module is an improvement over SPP[23], using multiple small-sized pooling kernels in series instead of a single large-sized pooling kernel in the SPP module. This modification retains the original functionality of fusing feature maps with different receptive fields, thereby enriching the feature map's expressiveness while further improving running speed.
In addition, the neck part is mainly composed of FPN[24], and PANet[25] for fusing feature information at different scales, and on the basis of FPN, PANet introduces a bottom-up path, which can make the bottom-up feature fusion after the top-down feature fusion, so that such bottom-up location information can also be transferred to the deeper layers, thus enhancing the localization capability at multiple scales.
Finally, the head section has been replaced with the current mainstream decoupled head structure, separating the classification and detection heads. Additionally, it has shifted from an Anchor-Based to an Anchor-Free approach.
Loss function
-
The loss function of YOLOv8 consists of two components: classification loss and regression loss:
● Classification loss, calculate whether the anchor matches the correct category.
● Regression loss, indicates the error in the position between the predicted box and the Ground Truth. It includes CIoU Loss and Distribution Focal Loss.
YOLOv8 uses BCE-With-Logits-Loss to calculate the classification loss (
$ {L}_{\mathrm{c}\mathrm{l}\mathrm{s}} $ $ Loss=-\dfrac{1}{n}{\sum }_{i}^{n}\left[{y}_{i}\cdot log\left({\sigma }\left({x}_{i}\right)\right)+\left(1-{y}_{i}\right)\cdot log\left(1-{\sigma }\left({x}_{i}\right)\right)\right] $ (1) $ \sigma \left(a\right)=\dfrac{1}{1+exp\left(-a\right)} $ (2) The metric often used to calculate the localization loss in YOLOv8 is IoU, which represents the overlap ratio between true box and predicted box, and that is:
$ IoU=\dfrac{\left|b\cap {b}^{gt}\right|}{\left|b\cup {b}^{gt}\right|} $ (3) In the original YOLOv8, the regression loss function is CIoU[26], which incorporates a penalty term
$ {\alpha }v $ $ {R}_{CloU}=\dfrac{{{\rho }}^{2}\left(b,{b}^{gt}\right)}{{c}^{2}}+\alpha v $ (4) Therefore, the loss calculation formula for CIoU is:
$ {L}_{CloU}=1-IoU+\dfrac{{{\rho }}^{2}\left(b,{b}^{gt}\right)}{{c}^{2}}+\alpha v $ (5) where,
$ \alpha =\dfrac{v}{\left(1-IoU\right)+v} $ (6) $ v=\dfrac{4}{{{\pi }}^{2}}{\left(arctan\dfrac{{w}^{gt}}{{h}^{gt}}-arctan\dfrac{w}{h}\right)}^{2} $ (7) where, b and bgt are the prediction box and label box respectively. wgt and hgt represent the width and height of the labeled box. w and h are the width and height of the prediction box respectively. ρ represents the distance between the center points of the two boxes, and c is the maximum distance between the boundaries of the two boxes.
Improved algorithm model YOLOv8-CE (YOLOv8-Coordinate Attention-EIoU)
YOLOv8 based on the Coordinate Attention module
-
The visual attention mechanism is a specialized signal-processing mechanism in the human brain for processing visual information. Humans encounter some obstacles in processing information. Therefore, they will focus on some of the information and ignore some of the less useful information[27]. Similar to the selective visual attention mechanism in humans, the attention mechanism in neural networks are designed to extract the information relevant to the current task for processing. The important information is enhanced by introducing an attention mechanism that assigns different weights to each input part. The aim is to focus attention on the more important information and reduce the attention on the remaining minor information, thus reducing the computational burden and improving the model performance[28]. In the present paper, Coordinate Attention[29] is added to the backbone network.
Hou et al. proposed an attention mechanism – Coordinate Attention (CA) in 2021, which not only captures cross-channel information but also incorporates direction-aware and position-sensitive information, precise object region detection and finer localization of traffic signs in small objects. This not only enhances model accuracy, but also requires minimal computational overheads[29].
CA encodes the channel relationship and long-term dependency by precise location information. Firstly, we embed Coordinate information and then generate Coordinate Attention. The structure diagram is shown in Fig. 3.
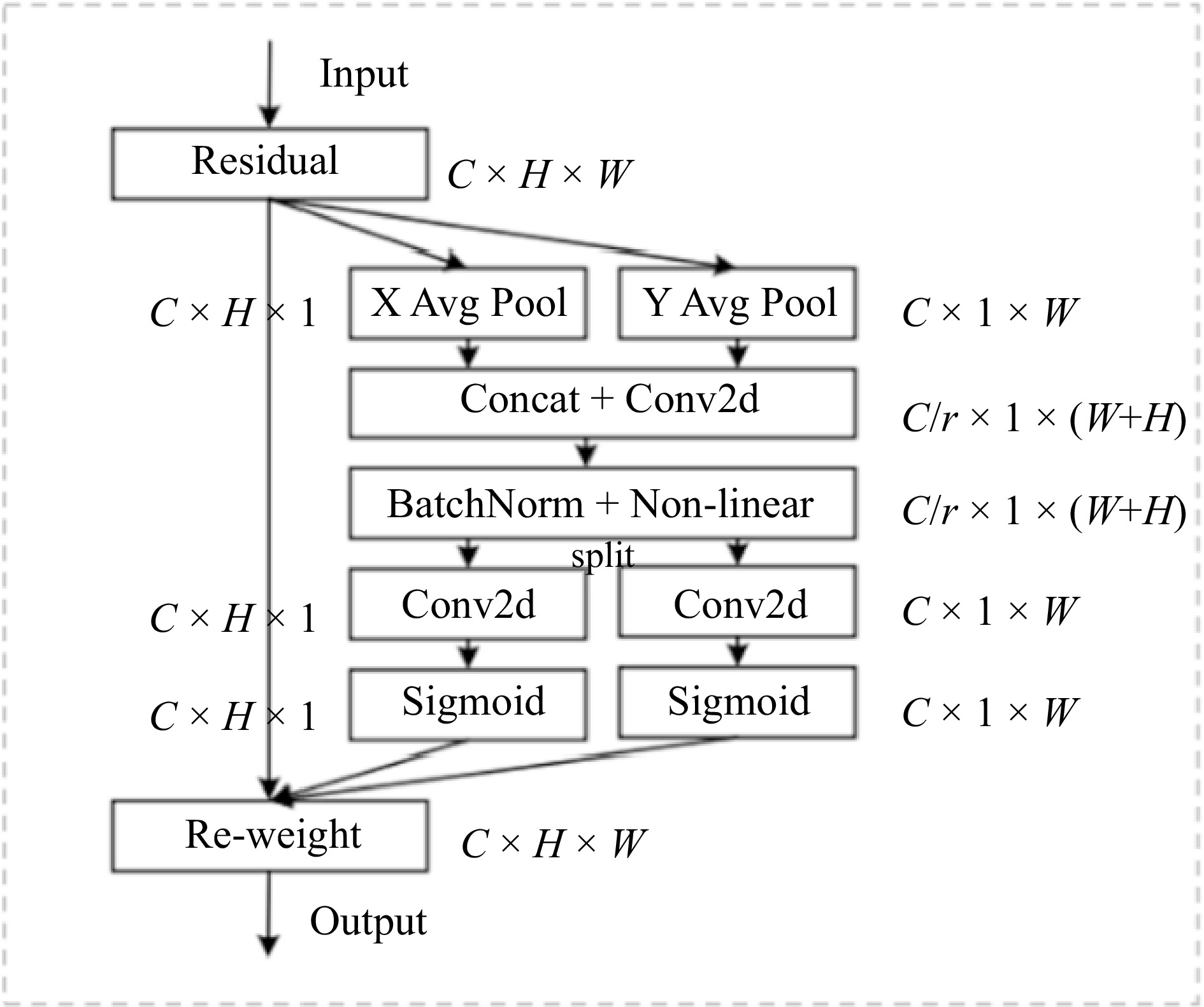
Figure 3.
Structure of coordinate attention.
The first one is Coordinate information embedding. When global encoding of spatial information of channel attention, the global pooling method, compresses the global spatial information and lacks the location information. To be able to obtain more accurate location information and capture remote spatial interactions, this paper decomposes the global pooling and converts it into a bunch of one-dimensional feature encoding operations with the following equation:
$ {z}_{c}=\dfrac{1}{H\times W}\sum _{i=1}^{H}\sum _{j=1}^{W}{x}_{c}\left(i,j\right) $ (8) The input is X. The pooling kernel of size (1, W) or (H, 1) is applied to encode each channel in horizontal and vertical coordinates respectively. Thus, the output of the c-th channel with height h can be expressed as follows:
$ {z}_{c}^{h}\left(h\right)=\dfrac{1}{W}\sum _{0\le j \lt W}{x}_{c}\left(h,i\right) $ (9) In the same way, the output of channel
$ c $ $ w $ $ {z}_{c}^{w}\left(w\right)=\dfrac{1}{H}\sum _{0\le j \lt H}{x}_{c}\left(j,w\right)$ (10) Then the Coordinate Attention is generated. After passing the transformations in the information embedding, this part concatenates the result of the embedding and then transforms it using the convolutional transform function.
$ f=\delta \left({F}_{1}\left(\left[{z}^{h},{z}^{w}\right]\right)\right) $ (11) $ {g}^{h}=\sigma \left({F}_{h}\left(\left[{f}^{h}\right]\right)\right)$ (12) $ {g}^{w}=\sigma \left({F}_{w}\left(\left[{f}^{w}\right]\right)\right) $ (13) After the above module, the final output
$ y $ $ {y}_{c}\left(i,j\right)={x}_{c}\left(i,j\right)\times {g}_{c}^{h}\left(i\right)\times {g}_{c}^{w}\left(j\right) $ (14) Improvement of loss function
-
Although the usage of CIoU in the original algorithm accelerates the regression of the predicted box to some extent, there are still certain issues. During the regression of the predicted box, if the aspect ratio of the predicted box matches the true box's aspect ratio, the predicted box's width and height cannot increase or decrease simultaneously, and the regression optimization process cannot proceed. Therefore, the CIoU function is replaced by the EIoU function in this paper[30].
The EIoU is calculated as Eqn (15), where w and h are the width and height of the minimum external box that covers the real box of the prediction box. It takes into account the overlap area, the distance between centroids, and the real distance between centroids, as well as the actual differences in width and height. Moreover, Focal Loss is introduced to address the problems of other localization loss functions, which helps the model converge quickly, makes the regression process more stable, and enhances the precision of the predicted bounding box regression.
$ \begin{aligned}L_{EloU}\; & =L_{IOU}+L_{dis}+L_{asp} \\ & =1-IoU+\frac{\rho^2\left(b,b^{gt}\right)}{c^2}+\dfrac{\rho^2\left(w,w^{gt}\right)}{C_w^2}+\dfrac{\rho^2\left(h,h^{gt}\right)}{C_h^2}\end{aligned} $ (15) where, Cw and Ch represent the width and height of the minimum external box covering both boxes.
In summary, the improved YOLOv8 model architecture is illustrated in Fig. 4.
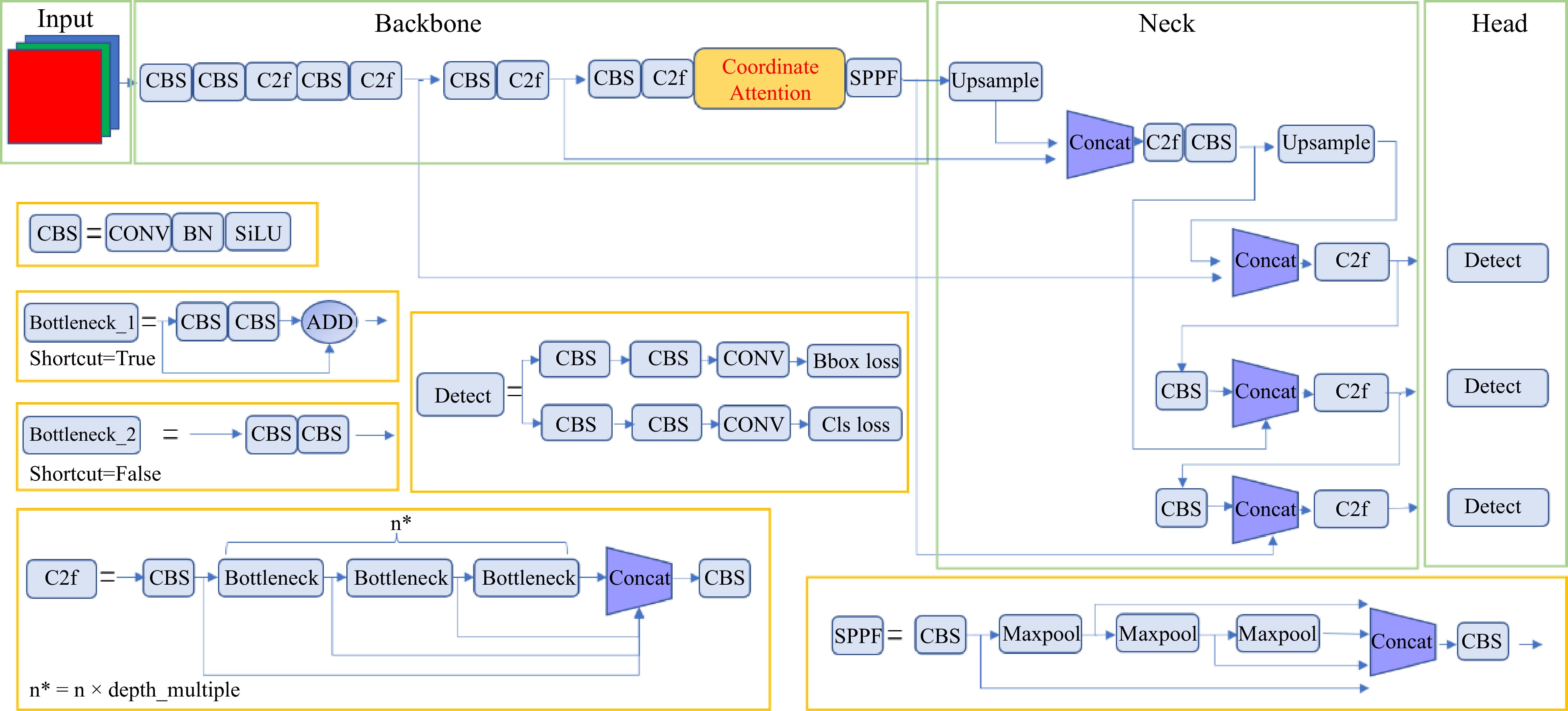
Figure 4.
Structure of the improved YOLOv8.
-
The traffic sign dataset in this paper is derived from the CCTSDB dataset[31], which was produced by the team of Zhang from Changsha University of Science and Technology (Changsha, China), in which the images are Chinese street scenes taken under the driving recorder. The dataset covers traffic sign images under various traffic environments, which is more in line with real traffic scenes.
There are 17,856 images in the CCTSDB dataset, which includes three categories of traffic signs: prohibition, indication, and warning, as shown in Fig. 5, and their locations are calibrated. The distribution of the number of each category in the training set is illustrated inFig. 6. Based on the 1,500 original test sets, the papers categorized them into six categories of multi-weather test sets, including cloud, foggy, night, rain, snow, and sunny.

Figure 5.
Traffic sign categories.
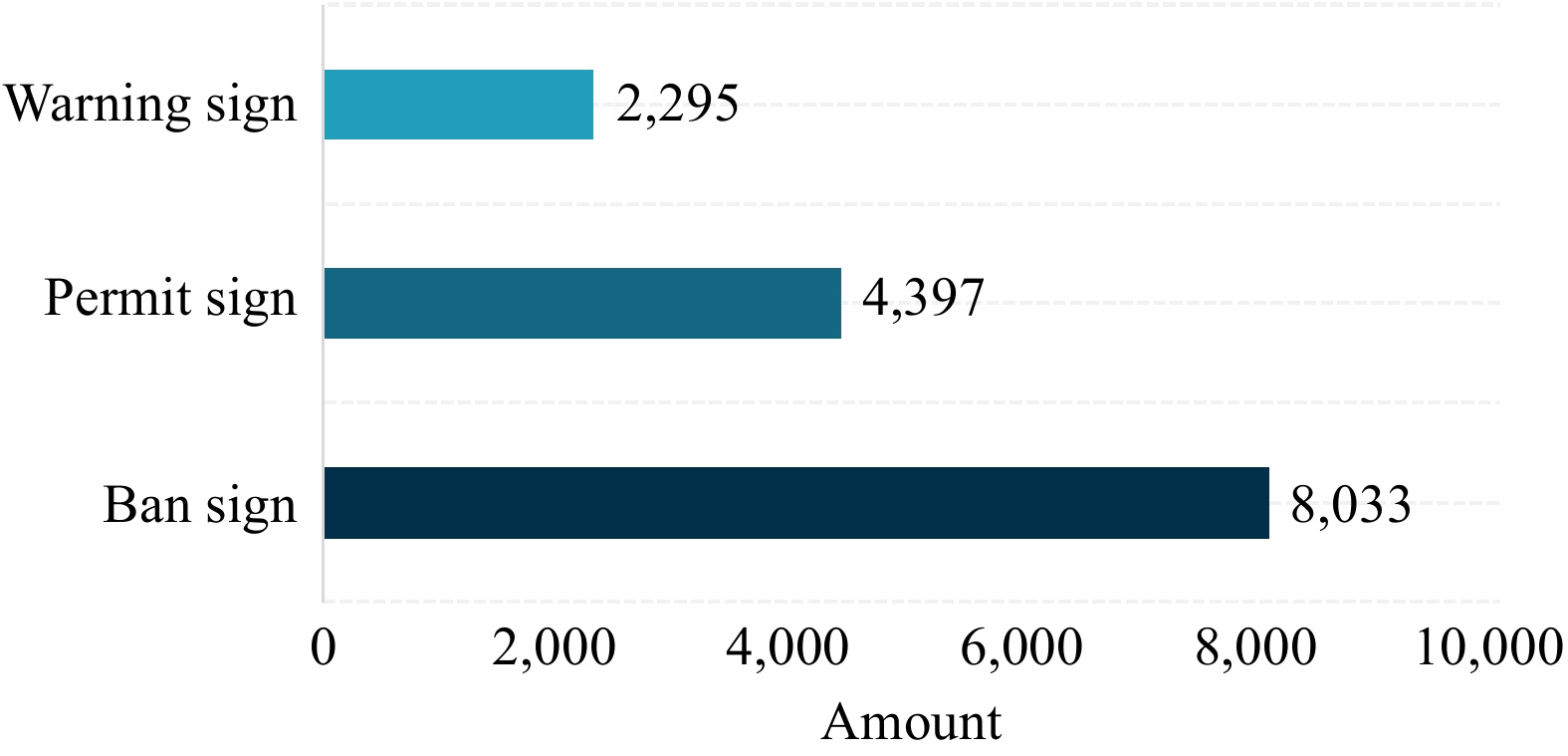
Figure 6.
Number of traffic signs for each category.
To better evaluate the model, Inference Time and mAP were chosen to evaluate the detection speed and accuracy of the model, where Inference Time is the inference time, indicating the speed of model inference. mAP is the average of the region enclosed by the P-R curve, reflecting the recognition accuracy of the model.
Experimental environment
-
The experiments in the paper are trained on a server equipped with a GPU, model NVIDIA GEFORCE RTX 2080Ti, the server's operating system is Ubuntu system with version 18.04 and with 11 GB of video memory, Python language development, Pytorch-based deep learning framework, and GPU acceleration tool CUDA11.1.
In the inference stage, to confirm the real-time effectiveness of the model, this study opts for the NVIDIA Jetson Nano embedded platform, which has a core processing unit using CPU + GPU heterogeneous computing mode, which establishes that the platform can run neural network applications for image classification, object detection, etc. Meanwhile, the deep learning inference acceleration engine TensorRT is available to accelerate the Inference time of artificial intelligence projects. In the inference stage, to confirm the real-time effectiveness of the model, this study opts for the NVIDIA Jetson Nano embedded platform, which has a core processing unit using CPU + GPU heterogeneous computing mode, which establishes that the platform can run neural network applications for image classification, object detection, etc. Meanwhile, the deep learning inference acceleration engine TensorRT is available to accelerate the Inference time of artificial intelligence projects. Figure 7 illustrates the hardware platform, while Table 1 specifies the configuration used in the study.

Figure 7.
Structure of Jetson Nano.
Table 1. Hardware parameters of Jetson Nano.
Parameter Technical specifications AI performance 472 GFLOPs GPU 128-core Maxwell Memory 4 GB 64-bit LPDDR4 25.6 GB/s CPU Quad-core ARM A57 @ 1.43 GHz CPU max frequency 1.43 GHz Storage microSD (not included) Connectivity Gigabit Ethernet, M.2 Key E USB 4x USB 3.0, USB 2.0 Micro-B Power 5 W - 1 0W During training, the model takes 640 × 640 pixel input images and employs the Adam optimizer with an initial learning rate of 0.01, runs for 300 epochs with a batch size of 16, and a weight decay of 0.0005.
Experiment results and analysis
Ablation study
-
To confirm the validity of each part of the improvement methods, ablation studies are conducted on the CCTSDB dataset, based on YOLOv8n, combining Coordinate Attention, and EIoU to verify the effect of different improvement methods for the network. Precision, Recall, and mAP @0.5 are used as evaluation metrics. The resolution of 640 × 384 is selected, and the complex integrated image test set is chosen, and the outcomes of the ablation study are presented in Table 2.
Table 2. Results of the ablation study.
Model Precision Recall mAP@0.5 YOLOv8n 88.7% 73.6% 83.3% CA 89.6% 75.4% 84.9% EIoU 87.9% 75.1% 84.5% CA + EIoU 90.2% 78.1% 86.1% Comparing YOLOv8 with the models CA and EIoU, it is evident from the results that both CA and EIoU enhance the models' performance, and improve by 1.6% and 1.2% on mAP, respectively. After YOLOv8 combines all the improvements, the model performs well in terms of Precision, Recall, and mAP. Compared with the baseline model, the improvement in mAP was 2.8%. According to the findings from the ablation experiments, it is known that the CA and EIoU enhancements are effective.
Comparison with other algorithms
-
To further validate the comprehensive performance effect of the YOLOv8-CE algorithm in terms of detection accuracy and inference speed on different types of test sets, five object detection algorithms were selected, including YOLOv8n, YOLOv8-ghost, YOLOv8-ghostv2, YOLOv8-shufflenetv2, and YOLOv8-mobilenetv3, to compare with this algorithm. The comparison experiments were performed on the seven test sets delineated in this paper, and 640 × 384 resolution was selected. Four metrics, Precision, Recall, mAP, and Inference time on Jetson Nano, were selected to evaluate each algorithm. Table 3 illustrates the results of the comparison of accuracy and inference speed among different algorithms. Table 4 illustrates the results of accuracy comparison between different algorithms under different weather test sets. Figure 8 presents the detection results of YOLOv8-CE under different weather test sets.
Table 3. Comparison of traffic sign detection models.
Model Precision Recall mAP@50 mAP@50-95 Inference time (ms) YOLOv8-CE(ours) 90.2 78.1 86.1 57.2 96 YOLOv8n 88.7 73.6 83.3 53.7 92 YOLOv8-ghost 89.2 72.5 82.1 52.1 243 YOLOv8-ghostv2 89.1 71.6 82.2 52.5 230 YOLOv8-shufflenetv2 81.1 53.6 61.8 61.8 110 YOLOv8-mobilenetv3 73.4 54.6 61.4 35.7 65 Table 4. Comparison of traffic sign detection models under different weather test sets.
Model Orinal Cloud Foggy Night Rain Snow Sunny YOLOv8-CE(ours) 86.1 92.5 81.6 76.5 43.1 86.5 94.8 YOLOv8n 83.3 89.5 68.3 73.8 32.7 77.8 93.2 YOLOv8-ghost 82.1 88.8 77.9 75.5 29.8 82.5 91.3 YOLOv8-ghostv2 81.9 89.2 63.9 73.0 39.9 70.0 91.3 YOLOv8-shufflenetv2 61.4 74.9 53.7 40.6 10.8 45.7 80.0 YOLOv8-mobilenetv3 61.8 75.9 55.2 40.6 16.9 58.6 77.6 
Figure 8.
Detection results of YOLOv8-CE under different weather test sets.
It can be seen that the mAP at the highest in all three test sets is YOLOv8-CE, whose mAPs are 86.1% on the original test set, and the inference time of this model on Jetson Nano is only 96 ms. YOLOv8n exhibits the shortest inference time on Jetson Nano, but it has lower accuracy compared to the algorithm used in this study on all test sets. In comparison to YOLOv8n, YOLOv8-CE achieved an accuracy of 2.8% on the original test set, while detecting only 4 ms slower. Meanwhile, YOLOv8-CE showed the best overall performance on all data sets. The algorithm outperforms YOLOv8n by an average of 6.1% in terms of accuracy. For the other algorithms in the experiment, the algorithm shows better performance. The algorithm ensures real-time detection of embedded devices while also improving detection accuracy to a certain extent, and performs well in extreme weather conditions and other conditions.
Results of field tests
-
To confirm the real-time performance of the model on embedded devices, the trained model in this paper is deployed into the NVIDIA Jetson Nano embedded system, and the input resolution is set to 640 × 384 to complete the traffic sign detection in the live video of Harbin, China. The hardware system of Jetson Nano is shown in Fig. 9 and the detection results are shown in Fig. 10.

Figure 9.
Hardware system of Jetson Nano.

Figure 10.
Field test on Jetson Nano in Harbin, China.
In addition, this paper compares the Jetson Nano with the Raspberry 4B Pi and deploys the same algorithm on both devices for testing and comparing the inference time, as shown in Table 5. It can be seen that the computational volume and Weight Size of the algorithm in this paper are similar to YOLOv8n, and the inference time is around 96 ms. The inference time on Jetson Nano is 1/7 of that on Raspberry Pi 4B. Although the inference time of YOLOv8-CE is not the fastest, its overall performance is the best and the inference time is within 100 ms, which is far enough to meet the requirements of real-time detection. In addition, it can also be seen that the inference time of all models on Jetson Nano is within 250 ms, which achieves real-time detection.
Table 5. Experiments on different devices.
Model FLOPs
(G)Weight size
(MB)Inference time (ms) Jetson Nano Raspberry pi 4B YOLOv8-CE(ours) 8.1 5.99 96 690 YOLOv8n 8.1 5.96 92 678 YOLOv8-ghost 6.8 5.97 243 810 YOLOv8-ghostv2 6.8 5.17 230 791 YOLOv8-shufflenetv2 5.0 3.48 110 580 YOLOv8-mobilenetv3 2.8 2.52 65 313 -
In this paper, an improved detection algorithm of YOLOv8 combined with the embedded system Jetson Nano was proposed to realize real-time detection of traffic signs on self-driving or assisted-driving vehicles. The main findings are as follows:
(1) Through ablation study, the effectiveness of the improved network combining Coordinate Attention, EIoU is considered as a function in the paper is verified. The improved YOLOv8n model achieves 86.1% mAP @0.5 in the original test set. Compared to the original YOLOv8, Precision, Recall, and mAP @0.5 are improved by 1.5%, 3.5%, and 2.8%, respectively, and the accuracy is also improved in other test sets, with better results in all kinds of scenarios and stronger generalization ability. In addition, the inference time on Jetson Nano is increased by 4 ms, the model memory is increased by 0.03 MB, and the FLOPs are approximately equal. Furthermore, the improved method adopted in the paper increases the detection accuracy substantially while slightly reducing the detection speed. The experimental results demonstrate the superiority of the YOLOv8-CE method adopted in this paper.
(2) The superiority of the YOLOv8-CE model is further confirmed by comparing it with classical lightweight models such as YOLOv8-mobilenetv3, and YOLOv8-ghost. The improved model outperforms the other three models in terms of accuracy and detection speed in general, showing the best performance. The experimental results further demonstrate that the improved approach adopted in the paper has good detection performance.
(3) By conducting live video tests on different embedded devices, it can be seen that the Jetson Nano far outperforms the Raspberry Pi in the detection of traffic signs, and the detection speed of YOLOv8-CE enters within 100 ms on the Jetson Nano, reaching 96 ms, achieving the performance of real-time vehicle traffic sign detection. The experimental results demonstrate the feasibility of this paper's model for edge computing platforms.
To summarize, the YOLOv8-CE model can detect the type and location of traffic signs more accurately and quickly, which serves as a foundation for future advancements in real-time traffic sign detection and provides a basis for the implementation of autonomous driving. In addition, future studies will concentrate on the following fields:
(1) Some lightweight methods, such as model pruning[32,33], model quantization[34,35], and knowledge distillation[36,37], will be used to be less computationally intensive and consume less model, while combining lightweight network models to create a lightweight network with better performance that is compatible with detection in small mobile devices to further enhance the speed of traffic sign detection.
(2) Collecting data sets from more situations for model training and processing the data to make the model more generalizable and able to adapt to traffic sign recognition in various situation scenarios.
(3) The network model is going to be further improved and self-attention will be added to fuse features more effectively, which in turn will better detection performance of the model.
-
The authors confirm contribution to the paper as follows: study conception and design: Luo Y, Ci Y; data collection: Luo Y, Zhang H, Wu L; analysis and interpretation of results: Luo Y, Ci Y, Zhang H, Wu L; draft manuscript preparation: Luo Y, Ci Y. All authors reviewed the results and approved the final version of the manuscript.
-
The data that support the findings of this study are available in the github repository. These data were derived from the following resources available in the public domain:
https://github.com/csust7zhangjm/CCTSDB . This work was financially supported by Heilongjiang Provincial Natural Science Foundation of China (LH2023E055), and the National Key R & D Program of China (2021YFB2600502).
-
The authors declare that they have no conflict of interest.
- Copyright: © 2024 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Luo Y, Ci Y, Zhang H, Wu L. 2024. A YOLOv8-CE-based real-time traffic sign detection and identification method for autonomous vehicles. Digital Transportation and Safety 3(3): 82−91 doi: 10.48130/dts-0024-0009 

A YOLOv8-CE-based real-time traffic sign detection and identification method for autonomous vehicles
- Received: 08 July 2024
- Accepted: 23 July 2024
- Published online: 30 September 2024
Abstract: Traffic sign detection in real scenarios is challenging due to their complexity and small size, often preventing existing deep learning models from achieving both high accuracy and real-time performance. An improved YOLOv8 model for traffic sign detection is proposed. Firstly, by adding Coordinate Attention (CA) to the Backbone, the model gains location information, improving detection accuracy. Secondly, we also introduce EIoU to the localization function to address the ambiguity in aspect ratio descriptions by calculating the width-height difference based on CIoU. Additionally, Focal Loss is incorporated to balance sample difficulty, enhancing regression accuracy. Finally, the model, YOLOv8-CE (YOLOv8-Coordinate Attention-EIoU), is tested on the Jetson Nano, achieving real-time street scene detection and outperforming the Raspberry Pi 4B. Experimental results show that YOLOv8-CE excels in various complex scenarios, improving mAP by 2.8% over the original YOLOv8. The model size and computational effort remain similar, with the Jetson Nano achieving an inference time of 96 ms, significantly faster than the Raspberry Pi 4B.
-
Key words:
- YOLOv8-CE-based /
- Real-time /
- Traffic /
- Signs /
- Detection