








-
The herbaceous peony, a well-known traditional flower in China[1], is characterized by its large and aesthetically pleasing flowers. The herbaceous peony is a member of the family Paeoniaceae[2], displaying notable adaptability, and significant ornamental value[3]. Studies on aromatic ornamental plants involve an examination of aromatic components, and genetic mechanisms[4], including Rosa rugosa Thunb.[5], Lilium brownii var. viridulum Baker[6], and Paeonia suffruticosa Andr.[7], Pyrus communis L.[8], Dendrobium officinale [9], Nymphaea tetragona[10], Rhododendron simsii[11], Jasminum sambac[12], studies were conducted on Chrysanthemum morifolium[13], Osmanthus fragrans[14], Camellia japonica[15], Malus[16], and Iris tectorum Maxim.[17] Historically, research has focused on factors such as flower shape, color, blooming season, and resilience, with less attention given to the floral scent[18].
The floral scent has been identified as a significant ornamental attribute of herbaceous peony[3,19], and is also a prominent feature in numerous plant species[20]. It is frequently described as the 'essence of flowers'[21] and is derived from a range of volatile compounds that are synthesized within the plant and subsequently released into the atmosphere[22]. To date, over 1,700 volatile compounds have been identified in a variety of plants, with a multitude of applications in the manufacture of perfumes, cosmetics, culinary seasonings, and pharmaceuticals[23,24]. The composition and concentration of these volatile compounds exhibit considerable variation across different species, genus, and cultivars. Nevertheless, there is a paucity of research dedicated to the analysis of fragrance constituents and their respective concentrations in herbaceous peony and tree peony[25]. Song et al.[4] identified a total of 130 volatile compounds across 30 cultivars of herbaceous peony, encompassing 72 aromatic constituents. The 24 cultivars exhibiting heightened fragrance were categorized into five distinct aroma profiles: woody scent, fruity scent, lily scent, rose scent, and an orange blossom scent. Zhao et al.[26] conducted a study in which 68 volatile compounds and 26 significant aroma constituents were identified from a sample of 87 herbaceous peony cultivars. The researchers determined that herbaceous peony contain characteristic aromatic substances, including linalool (resembling lily of the valley), geraniol (exhibiting a pleasant geranium-like scent), citronellol (evoking a fresh and light rose and leaf fragrance), and phenylethyl alcohol (noted for its distinctive rose aroma), based on the content and odor threshold of these main aroma components. In a separate study, Li et al.[27] identified 128 volatile compounds from 24 tree peony cultivars, with the predominant classes being terpenes, alcohols, and esters. The distribution pattern of these primary fragrance constituents led to the categorization of 24 tree peony cultivars into four types: grass scent (ocimene), woody scent (longifolene), lily of the valley scent (linalool), and fruity scent (2-ethyl hexanol). It has been demonstrated that the distinctive fragrances of different plant species are the result of the presence of specific volatile compounds in varying quantities and ratios. Furthermore, the quantity of fragrance emitted by flowers is contingent upon their developmental stage[28].
Floral substances derived from plants are classified as secondary metabolites, which are released by flowering plants and predominantly comprise a range of volatile compounds characterized by relatively low molecular weights. In a comprehensive analysis of the aromatic compounds present in P. rockii and P. ostii 'Fengdan', Wu et al.[29] employed two-dimensional gas chromatography coupled with time-of-flight mass spectrometry (GC × GC-TOF/MS). The results indicated that the aroma profile of P. rockii was primarily characterized by the presence of alcohols, alkanes, and acids, while the aroma profile of P. ostii 'Fengdan' was predominantly defined by aldehydes, alcohols, and terpenes. In a separate investigation, Li et al.[30] sought to identify and analyze the volatile compounds present in the flowers of seven pear cultivars (Anli, Bayuesu, Golden, Brown Peel, KorlaXiangli, Lyubaoshi, and Xizilü). The findings indicated that certain aldehydes constitute significant characteristics of these cultivars and are recognized as essential active odorants, which emit pronounced citrus and floral fragrances. Yang et al.[31] successfully identified and characterized 34 volatile compounds in the Dendrobium officinale flowers. Of these, 18 compounds were identified as principal odorants, including 1-octen-3-ol, hexanal, nonanal, phenylacetaldehyde, linalool, 4-oxoisophorone, theaspirane, and methyl salicylate. Furthermore, Kimani et al.[32] identified geraniol, β-caryophyllene, 2-phenylethanol, citronellol, and 1,8-cineole as the primary aromatic constituents in 24 cultivars of herbaceous peony, including P. lactiflora 'LianTai' and P. lactiflora 'Hongyan Feishuang'. Aromatic compounds are recognized as the primary chemical constituents of aromatic plants, playing a crucial role in the synthesis of secondary metabolites[33], and fragrance development. These compounds exhibit a diverse range of forms. For example, phenethyl alcohol is found in rose, mint contains menthol, and lemon includes citric acid[22,34,35].
This study employed a combination of dynamic headspace sampling technology[36] and GC-MS to analyze the volatile components and concentrations in 100 international herbaceous peony cultivars during the half-opening stage. The objective was to elucidate the aromatic profile of the herbaceous peony. The findings of this study establish a fundamental framework for further investigation and exploitation of the fragrances of herbaceous peony flowers and provide a valuable resource for enhancing the economic value of herbaceous peony.
-
The experimental materials used in this study were obtained from the Luoyang Academy of Agriculture and Forestry Sciences (Luoyang City, Henan Province, China) between 20 April and 8 May 2022. The majority of the materials were collected between 10 and 12 am. The subjects of the experiment were herbaceous peony plants sourced from the herbaceous peony resource garden affiliated with the Henan University of Science and Technology. As outlined in Table 1 and Fig. 1, herbaceous peony cultivars demonstrating consistent growth patterns and flowering stages were identified, and the methodology entailed the repetition of each sample on three occasions.
Table 1. Names and numbers of 100 herbaceous peony cultivars.
100 herbaceous peony cultivars 'Hangbaishao' 'Hongrongqiu' 'Biandihong' 'Zijin Daipao' 'Zixia Yingxue' 'Fenchi Dicui' 'Xishifen' 'Yinlong Hanzhu' 'Yinxian Xiuhongpao' 'Jindaiwei' 'Luhong' 'Xueyuan Hongxing' 'Mozijin' 'Yahong' 'Wulong Tanhai' 'Hongyan Zhengshuang' 'Xingguang Chanlan' 'Yanlihong' 'Hongling Chijin' 'Fenzhuangyuan' 'Taohua Huancai' 'Zhongshenghong' 'Ziling' 'Luxihong' 'Zifurong' 'Hongling Chijin' 'Huguang Shise' 'Hongyuqiu' 'Yanzhi Dianyu' 'Lantian Piaoxiang' 'Zhushapan' 'Hongyun Yingri' 'Yanzi Xiangyang' 'Yanzhihong' 'Zaoyuanhong' 'ChilongCaifeng' 'Chaoshihong' 'Qingwen' 'Shaifugui' 'Ziyanshuang' 'Gaoganfen' 'Qundiehui' 'Meirenmian' 'Meiju' 'Dafugui' 'Zhifeng Zhaoyang' 'Xueyuan Hongxing' 'Dahongpao' 'Zixiuqiu' 'Canglong' 'Gaoganhong' 'Hongyan Feishuang' 'Dabanhong' 'Zifengyu' 'Hongpan Jinqiu' 'Hushui Dangxia' 'Yinlong Huihai' 'Baihuazi' 'Taohuafen' 'Wawamian' 'Fenpanjinxing' 'Heixiuqiu' 'Shuanghonglou' 'Changshouhong' 'Hongyan Lushuang' 'Tuopan Jinhua' 'Hongling Chijin' 'Linglongyu' 'Jinzan Ciyu' 'Xiangyang Qihua' 'Jinbian Hongge' 'Duoyezi' 'Fenzilou' 'Furong Jinhua' 'Fenkui' 'Guifei Chacui' 'Huolian Jingang' 'Hongguanfang' 'Fenmian Taohua' 'Taoranzui' 'Zhaoyanghong' 'Hongfengyu' 'Fumantang' 'Shaonvfen' 'Danfeng' 'Liantaizi' 'Meiguihong' 'Fenfurong' 'Fenling Hongzhu' 'Fenqiu' 'Fencuiqiu' 'FengChao Chuyu' 'Lanju' 'Jinsanhong' 'Zhaoyuanfen' 'Hongfeng' 'Qiaoling' 'Tuanye Jinqiu' 'Guohong' 'Tongquechun' The numbers 1−100 are listed from top to bottom, left to right respectively. 
Figure 1.
Morphological characteristics of 100 herbaceous peony cultivars at the half-opening stage. The order of the above pictures is relative to the order of cultivars in Table 1.
Experimental equipment and materials
Equipment
-
The Gas Chromatography-Mass Spectrometry System (GC8890-MS5977B) from Agilent Technologies, USA, and the Atmospheric Sampler QC-1S from the Beijing Institute of Labor Protection were utilized in the study.
Chemicals
-
The reagents used included Tenax TA as the adsorbent, ethyl caprate, dichloromethane, pentane, n-hexane of chromatography grade, ethyl decanoate, ethyl acetate, and a standard solution of n-alkane mixture (ranging from C8 to C40) obtained from Sigma-Aldrich, USA.
Collection methods of volatile components
-
The dynamic headspace adsorption technique employed in this study was a sampling bag (355 mm × 508 mm, Reynolds, USA) hermetically sealed at one end with an activated carbon filter tube. The bag was meticulously wrapped around a live peony flower to minimize contact and prevent damage to the bag. The bag's opposite end was connected to a Tenax TA adsorption tube (6 mm outer diameter, 100 mm length, filled with adsorbent) and an atmospheric sampler via tasteless silicone tubing. The flow rate of the atmospheric sampler was set at 400 mL·min−1 and the sampling duration was 3 h. Following the sampling period, the adsorption tube was sealed with cling film and aluminum foil, then placed in a self-sealing bag and stored in an ultra-low temperature cooler for transport to the laboratory. The sample was then eluted with n-hexane during sample processing, and the eluate was transferred to a brown sample bottle for subsequent analysis.
The following conditions were observed in the gas chromatography (GC) analysis: the chromatographic column employed is a flexible quartz capillary column, with a length of 30 mm, an internal diameter of 0.25 mm, and a pore size of 0.25 μm. The flow rate of the column is set at 1.2 mL·min−1. The temperature of the column is maintained according to a specific protocol. It is initially set at 70 °C and held for 1 min, then increased to 136 °C at a rate of 6 °C·min−1, followed by further increases to 138 °C at a rate of 1 °C·min−1, then to 142 °C at a rate of 2 °C·min−1, and finally to 143 °C at a rate of 0.5 °C∙min−1. The temperature is increased by 5 °C·min−1 and subsequently to 160 °C at a rate of 2 °C·min−1, before reaching 250 °C at a rate of 10 °C·min−1. The injector temperature is set at 250 °C, with a carrier gas of high-purity helium at a flow rate of 1 mL·min−1. The injection mode is a split injection, with a split ratio of 9:1, and the injection volume is 2 μL.
The following conditions were employed for the mass spectrometry (MS) analysis: The electron impact (EI) source is operated at 70 eV, with the interface temperature set to 250 °C and the ion source temperature maintained at 230 °C. The quadrupole temperature is controlled at 150 °C, and the scan range is from 25 to 400 amu.
Analysis methods of volatile components
Qualitative analysis
-
Before the analysis of the sample using gas chromatography, the 500 mg∙L−1 n-alkane mixed standard solution should be diluted with n-hexane at a ratio of 1:50, in accordance with the specified conditions for the chromatography. It is essential to record the retention time for each n-alkane and to compare the resulting Retention Index (RI) values with those documented in the literature to facilitate the identification of the compounds in question. The following formula is used to calculate the RI:
$\rm RI=100\times n+100\times (t_x-t_n)/(t_ {n+1} -t_n) $ The location of the aforementioned item is as follows: The retention index (RI) represents the retention time of the volatile substances under examination. The number of carbon atoms in the straight-chain alkane preceding the analyte is represented by n. The retention time of the analyte is represented by tx. The retention time of the straight-chain alkane before the analyte is represented by tn. The retention time of the straight-chain alkane following the analyte is represented by tn+1. The retention time of the analyte falls between the retention times of tn and tn+1. Qualitative analysis of volatile components is conducted through consultation with the NIST 17 spectral library, with cross-referencing of RI values, literature sources, and other pertinent resources, including books.
Quantitative analysis
-
An internal standard solution, comprising 69.32 mg∙L−1 of ethyl decanoate in ethyl acetate, is employed. A volume of 0.4 μL of the internal standard solution is added to each 80 μL sample. Subsequently, quantitative calculations are performed in accordance with the following formula:
$\begin{split}&\rm Content\; of\; each\; aroma\; substance\;({\text μ}g\cdot g^{-1})=\\&\rm \dfrac{Peak\; area\; of\; each\; aroma\; substance}{Peak\; area\; of\; the\; internal\; standard} \;\times \\&\rm Concentration\; of \;the \;internal\; standard\;(mg\cdot L^{-1})\;\times \\& \rm \dfrac{Volume \;of \;the\; internal\; standard \;({\text μ}L)}{Volume \;of\; the\; sample\; (g)}\;\times\; f\end{split}$ where, f is the correction factor of each component to the internal standard, f = 1.
Data cleaning and analysis
-
The analysis of variance can be conducted using the statistical software package SPSS, while graph plotting can be accomplished with the Origin 2022 software. The software Metaboanalyst and the Microbiome Analysis Platform are capable of performing data normalization, partial least squares discriminant analysis (PLS-DA), and cluster analysis.
-
An analysis was conducted to determine the main volatile compounds present in 100 herbaceous peony cultivars during the half-opening stage. This was achieved through the utilization of database retrieval and manual identification methods. The results are outlined in Table 2. A total of 16 volatile components were identified and classified into six distinct groups. The data revealed that alkanes constituted six types, representing 37.5% of the total volatile components. This was followed by four types of esters at 25%, three types of alcohols at 18.75%, and one type each of terpenes, ethers, and phenols, each accounting for 6.25% of the total volatile components. The results of this analysis indicate that the predominant categories of volatile compounds found in herbaceous peony cultivars are alkanes, esters, and alcohols.
Table 2. The volatile components of 100 herbaceous peony cultivars.
Compound number RT (min) CAS number Compounds Compound classification Chemical formula Retention index Calculated value Reference value 1 3.273 111-84-2 Nonane Alkanes C9H20 900 900 2 4.805 124-18-5 Decane Alkanes C10H22 1,000 1,000 3 5.727 13877-91-3 (Z)-β-ocimene Terpenes C10H16 1,038 1,037 4 7.063 60-12-8 Phenylethyl alcohol Alcohols C8H10O 1,115 1,109 5 8.133 150-78-7 Benzene,1,4-dimethoxy- Ethers C8H10O2 1,165 1,168 6 9.502 106-22-9 Citronellol Alcohols C10H20O 1,228 1,228 7 10.084 106-25-2 Nerol Alcohols C10H18O 1,220 1,219 8 10.187 103-45-7 Methyl cinnamate Esters C10H12O2 1,260 1,258 9 12.976 103-26-4 2-Propenoic acid,3-phenyl-,methyl ester Esters C10H10O2 1,389 1,380 10 14.88 131-11-3 Dimethyl phthalate Esters C10H10O4 1,456 1,466 11 16.174 629-62-9 Pentadecane Alkanes C15H32 1,500 1,500 12 16.664 128-37-0 Butylated hydroxytoluene Phenols C15H24O 1,513 1,513 13 19.877 544-76-3 Hexadecane Alkanes C16H34 1,600 1,601 14 24.137 629-78-7 Heptadecane Alkanes C17H36 1,699 1,700 15 31.517 84-74-2 Dibutyl phthalate Esters C16H22O4 1,964 1,907 16 33.398 646-31-1 Tetracosane Alkanes C24H50 2,400 2,400 Comparison of volatile compounds content in different cultivars of herbaceous peony during the half opening stage
Alkane compounds
-
As illustrated in Fig. 2, alkane compounds were undetected in 30 cultivars, including P. lactiflora 'Hushui Dangxia', P. lactiflora 'Tuopan Jinhua', P. lactiflora 'Qiaoling', P. lactiflora 'Yinlong Hanzhu', and P. lactiflora 'Yanlihong'. Among the 100 herbaceous peony cultivars, the highest concentration of alkane compounds was observed in P. lactiflora 'Heizijin' (10.66 ± 2.01 μg·g−1), with the range of alkane compounds concentration spanning from 0.00 to 10.66 μg·g−1.
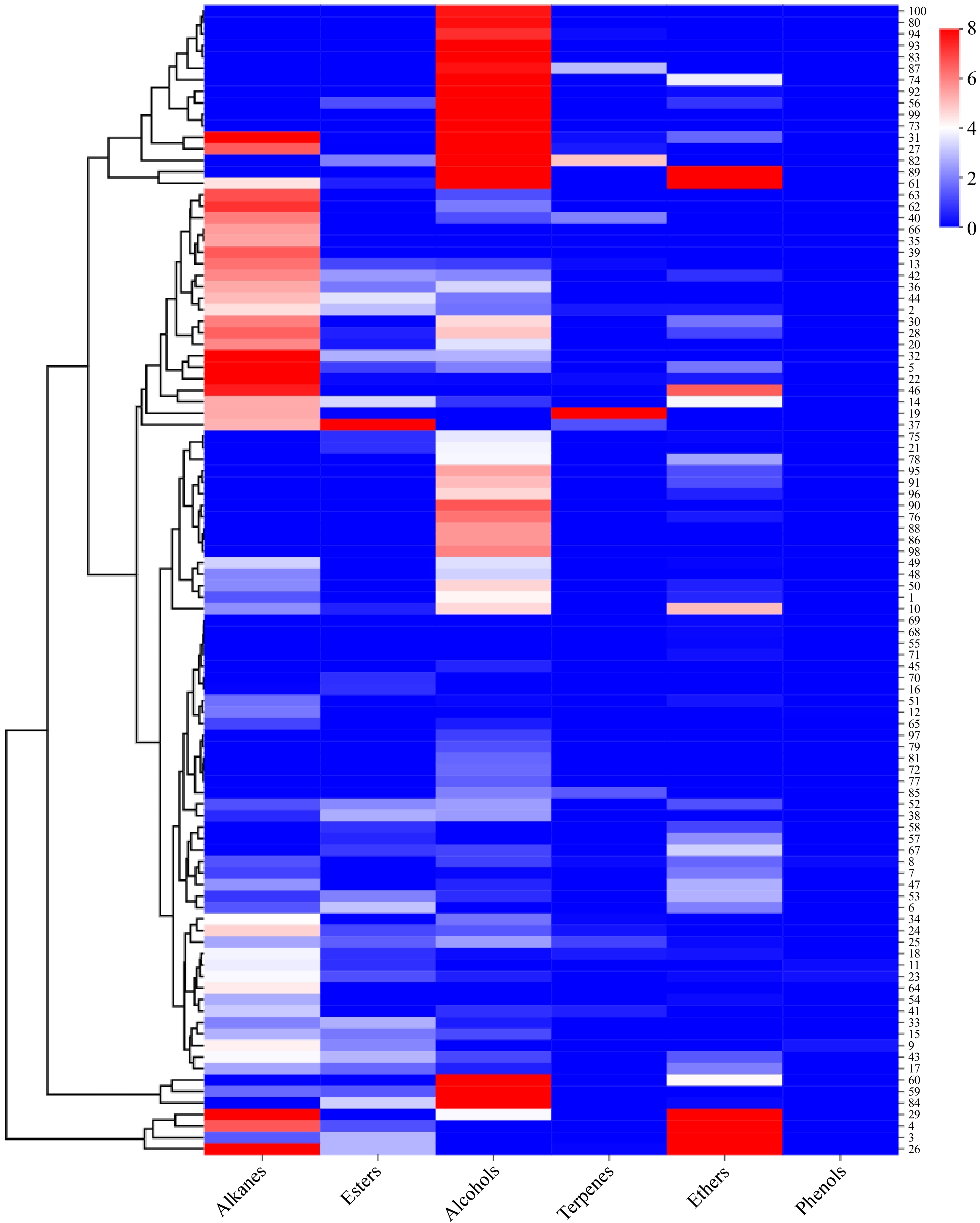
Figure 2.
Comparative heat map depicting the release of six types of volatile compounds from various herbaceous peony cultivars.
Ester compounds
-
As shown in Fig. 2, ester compounds were discernible in all 44 cultivars of herbaceous peony at the half-opening stage. However, the content of ester compounds was generally not notably high in most cultivars. The highest ester compounds content was observed in P. lactiflora 'Changshouhong' (9.15 ± 0.03 μg·g−1), followed by P. lactiflora 'Zaoyuanhong' (3.55 ± 0.40 μg·g−1), P. lactiflora 'Hongyun Yingri' (3.37 ± 0.11 μg·g−1), and P. lactiflora 'Saifugui' (3.25 ± 0.67 μg·g−1). The ester compounds content among these three cultivars was found to be similar, with a range of 0.00 to 9.15 μg·g−1.
Alcohol compounds
-
As depicted in Fig. 2, the majority of the 100 cultivars of herbaceous peony at the half-opening stage exhibited the presence of alcohol compounds. Only 23 cultivars, including P. lactiflora 'Taohua Huancai', P. lactiflora 'Zhushapan', and P. lactiflora 'Gaoganhong' exhibited no detection. The highest alcohol compounds content was observed in P. lactiflora 'Hongfeng' (22.98 ± 3.86 μg·g−1), which was significantly higher than that of other herbaceous peony cultivars. Subsequently, P. lactiflora 'Wandai Shengse' (16.23 ± 2.28 μg·g−1) exhibited the second-highest alcohol compounds content, with a range of 0.00 to 22.98 μg·g−1.
Terpene compounds
-
As illustrated in Fig. 2, only 19 of the herbaceous peony cultivars exhibited detectable levels of terpene compounds, with significant differences in content (p < 0.05). The highest content was observed in P. lactiflora 'Hongfengyu' (8.19 ± 1.02 μg·g−1), followed by P. lactiflora 'Wandai Shengse' (4.93 ± 0.09 μg·g−1), P. lactiflora 'Jinzan Ciyu' (2.92 ± 1.75 μg·g−1), P. lactiflora 'Dabanhong' (0.07 ± 0.13 μg·g−1), P. lactiflora 'Jinbian Hongge' (0.14 ± 0.23 μg·g−1), and P. lactiflora 'Mozi Hanjin' (0.16 ± 0.28 μg·g−1), among others. The range of terpene compounds content was found to vary from 0.00 to 8.19 μg·g−1.
Ether compounds
-
The analysis of 50 herbaceous peony cultivars revealed the presence of ether compounds in all samples, with notable variations in their content (p < 0.05). The highest content of ether compounds was observed in P. lactiflora 'Dabanhong' (22.84 ± 2.15 μg·g−1), followed by P. lactiflora 'Taohua Yingcai' (19.53 ± 2.44 μg·g−1). The lowest levels were observed in P. lactiflora 'Danfeng' (0.06 ± 0.11μg·g−1), P. lactiflora 'Ziling' (0.15 ± 0.26 μg·g−1), and P. lactiflora 'Huolian Jingang' (0.12 ± 0.21 μg·g−1). The range of ether compounds content was observed to vary from 0.00 to 22.84 μg·g−1.
Phenol compounds
-
The analysis revealed that only five herbaceous peony cultivars exhibited discernible levels of phenol compounds, namely P. lactiflora 'Jinbian Hongge' (0.15 ± 0.05 μg·g−1), P. lactiflora 'Zhaoyanghong' (0.34 ± 0.02 μg·g−1). The remaining cultivars exhibited lower levels of phenol compounds, with the lowest concentration observed in P. lactiflora 'Hongrongqiu' (0.17 ± 0.03 μg·g−1), followed by P. lactiflora 'Xueyuan Honghua' (0.01 ± 0.02 μg·g−1), and P. lactiflora 'Ziling' (0.27 ± 0.05 μg·g−1). The five cultivars exhibited notably lower levels of phenol compounds, with values consistently below 1 μg·g−1. The remaining cultivars were found to be devoid of phenol compounds.
An analysis was conducted on the total release of aroma components in different herbaceous peony cultivars
-
The analysis of the 16 volatile compounds detected revealed that, aside from alkanes such as nonane, the remaining 10 compounds from five classes all exhibited characteristic aromas, as detailed in Table 3. These aromatic compounds were present in the majority of samples, with concentrations exceeding 0.01 μg·g−1. Of particular note is the detection of benzene,1,4-dimethoxy-, in the majority of samples, with relatively high concentrations observed (Fig. 3).
Table 3. Characteristics of aroma compounds.
No. Compound name Odor characteristics 1 (Z)-β-ocimene The scent of grass and flowers is accompanied by the aroma of orange blossom oil[37] 2 Phenylethyl alcohol Sweet rose-like fragrance[38] 3 Benzene,1,4-dimethoxy- The fragrance of cloves[39] 4 Citronellol Has a sweet rose aroma[40] 5 Nerol There is a sweet rose fragrance[41] 6 Acetic acid, 2-phenylethyl ester There is a reminiscent of honey-like floral fragrance[42] 7 Methyl cinnamate Sweet smelling fragrance[43] 8 Dimethyl phthalate The substance emits a delicate fragrance[44] 9 Butylated hydroxytoluene The presence of a carbonic acid taste can
influence the aroma of wine[45]10 Dibutyl phthalate The substance emits a delicate fragrance[46] 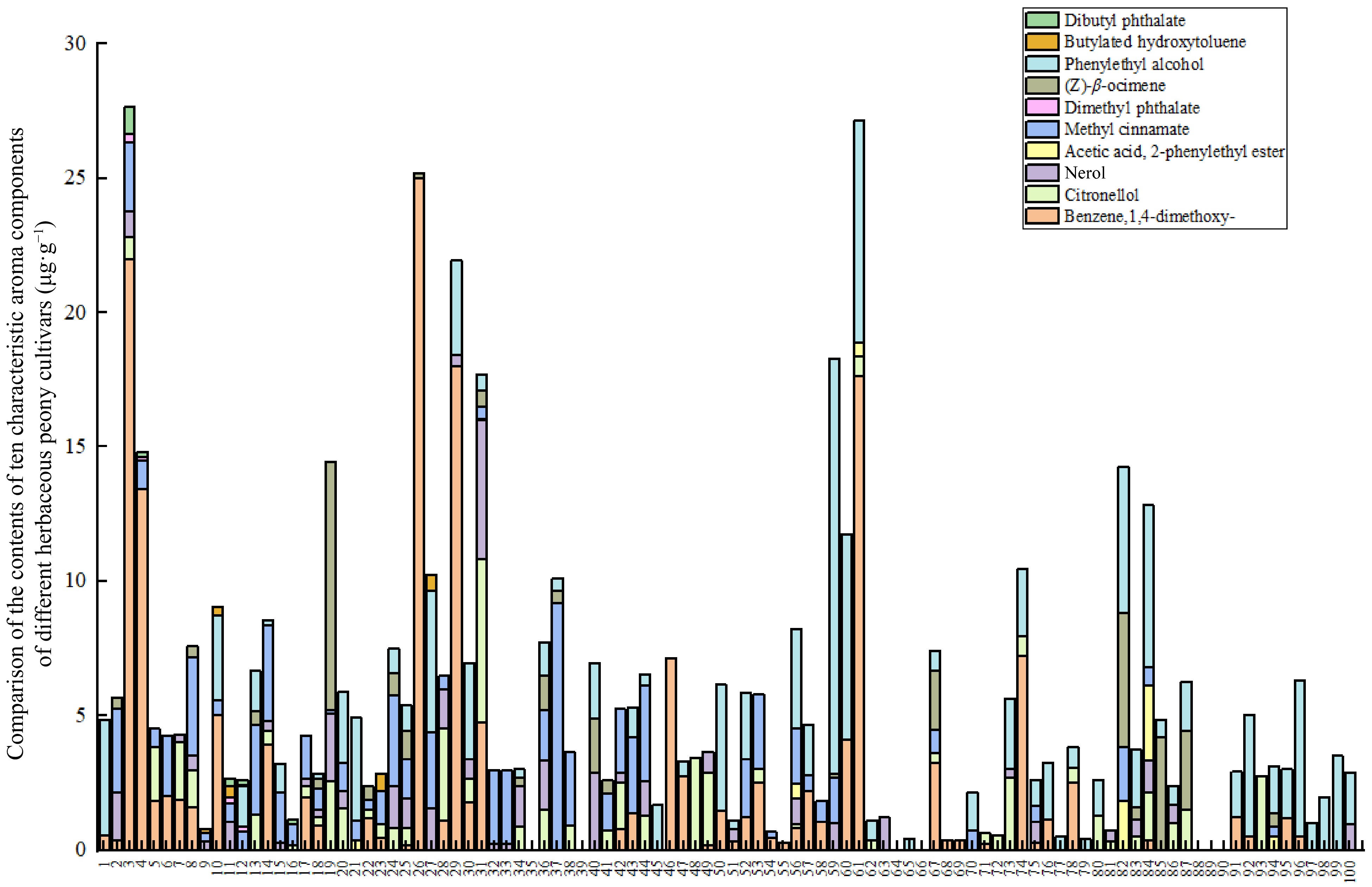
Figure 3.
Content of characteristic aroma compounds in herbaceous peony cultivars.
Cluster analysis of aromatic components in various herbaceous peony cultivars
-
A data matrix of dimensions 100 × 10 was constructed, representing the content of 10 aromatic compounds in 100 herbaceous peony cultivars as variables. A cluster heatmap was generated using the microbiome analysis platform, as illustrated in Fig. 4. In light of the clustering results and a comprehensive consideration of the major aromatic components, the 100 herbaceous peony cultivars are ultimately classified into two groups (Table 4). The first group of herbaceous peony cultivars is distinguished by a marked prevalence of benzene,1,4-dimethoxy-, with markedly elevated levels in comparison to other cultivars. This gives rise to a pronounced clove scent, indicative of a clove floral type. This initial classification is based on the presence of specific compounds and is therefore applicable to only five cultivars. The cultivars in question are P. lactiflora 'Taohua Huancai', P. lactiflora 'Xishifen', P. lactiflora 'Dabanhong', P. lactiflora 'Fumantang', and P. lactiflora 'Zhushapan'. The second group generally exhibits lower levels of aromatic compounds, resulting in milder scents that may be characterized as a light floral type. The second group comprises 95 cultivars, including representative cultivars such as P. lactiflora 'Meiju', P. lactiflora 'Shaonvfen', P. lactiflora 'Fenmian Taohua', P. lactiflora 'Fenling Hongzhu', and P. lactiflora 'Guohuo', among others.
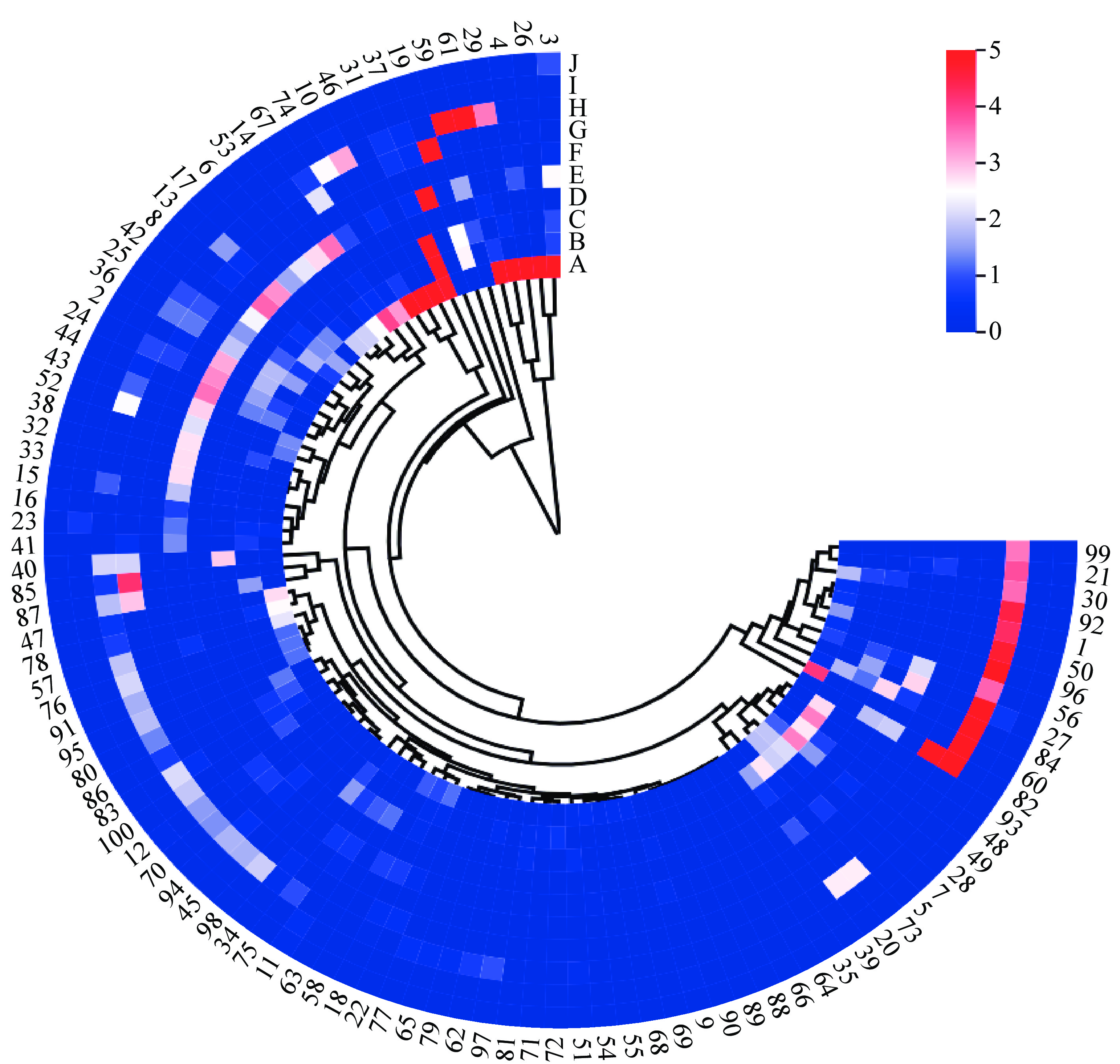
Figure 4.
Heat map showing the clustering analysis of 100 herbaceous peony cultivars. A-Benzene,1,4-dimethoxy-, B-Citronellol, C-Nerol, D-Acetic acid, 2-phenylethyl ester, E-Methyl cinnamate, F-Dimethyl phthalate, G-(Z)-β-ocimene, H-Phenylethyl alcohol, I-Butylated hydroxytoluene, J-Dibutyl phthalate. The numbers 1−100 correspond to the cultivar names listed in Table 1.
Table 4. Cluster analysis of characteristic aroma components in different herbaceous peony cultivars.
Groups Herbaceous peony cultivars 1 'Taohua Huancai', 'Xishifen', 'Dabanhong', 'Fumantang', and 'Zhushapan' 2 'Liantaizi', 'Hushui Dangxia', 'Shaifugui', 'Hongfeng', 'Wandai Shengse', 'Zhaoyuanfen', 'Wawamian', 'Lanju', 'Shuanghonglou', 'Fenling Hongzhu', 'Guohuo', 'Fenmian Taohua', 'Yinlong Tanhai', 'Chaoshihong', 'Shaonvfen', 'Meiju', 'Huolian Jingang', 'Meiguihong', 'Chilong Huancai', 'Yinlong Hanzhu', 'Yanlihong', 'Zhaoyanghong', 'Yinxian Xiuhongpao', 'Fenchi Dicui', 'Xueyuan Hongxing', 'Fenfurong', 'Linglongyu', 'Xiangyang Qihua', 'Hongrongqiu', 'Huguang Shise', 'Yanzhihong', 'Duoyezi', 'Mozijin', 'Guifei Chacui', 'Ziling', 'Zixia Yingxue', 'Zixiuqiu', 'Jinzan Ciyu', 'Meirenmian', 'Zifengyu', 'Jinshanhong', 'Hongyan Lushuang', 'Hongguanfang', 'Jindaiwei', 'Canglong', 'Tuopan Jinhua', 'Huolian Chijin', 'Fengchao Chuyu', 'Hongyuqiu', 'Xueyuan Hongxing', 'Qiaoling', 'Dahongpao', 'Qundiehui', 'Tuanye Jinqiu', 'Dafugui', 'Taoranzui', 'Yanzhi Dianyu', 'Tongquechun', 'Ziyanshuang', 'Gaoganfen', 'Fenpan Jinxing', 'Fenkui', 'Lantian Piaoxiang', 'Zifeng Zhaoyang', 'Xingguang Canlan', 'Hongyan Feishuang', 'Biahuazi', 'Taohuafen', 'Danfeng', 'Hongfengyu', 'Fenzilou', 'Yanzi Xiangyang', 'Zaoyuanhong', 'Luhong', 'Yahong', 'Luxihong', 'Furong Jinhua', 'Jinbian Hongge', 'Wulong Tanhai', 'Zhongshenghua', 'Zifurong', 'Hongyan Zhengshuang', 'Gaoganhong', 'Heixiuqiu', 'Hongling Chijin', 'Hongyun Yingri', 'Changshouhong', 'Fencuiqiu', 'Qingwen', 'Hongpan Jinqiu', 'Zijin Daipao', 'Biandihong', 'Fenqiu', 'Hangbaishao' and 'Fenzhuangyuan' Partial Least Squares Discriminant Analysis (PLS-DA)
-
Following the clustering of 100 cultivars into two groups, a partial least squares discriminant analysis (PLS-DA) was conducted on the content of 10 aroma compounds in the 100 cultivars using Metaboanalyst software. The results of the analysis are presented in Fig. 5. The PLS model for aroma compounds demonstrated satisfactory reliability, as evidenced by R2 and Q2 values of 0.702 and 0.598, respectively. Moreover, the PLS-DA results demonstrated variations in the profile of aroma compounds between the two groups of cultivars (Fig. 5a). The application of a VIP criterion greater than 1 identified a differentiating component (Fig. 5b). The VIP values in the PLS-DA model provided further insight into the contribution of each component to the model, with components having a value of VIP > 1 being considered significant. For instance, benzene,1,4-dimethoxy-, exhibited a VIP value of 3.153 and was identified as a principal component accountable for the discrepancies among herbaceous peony cultivars (Fig. 5b), corroborating the findings of the clustering analysis. It can therefore be posited that benzene,1,4-dimethoxy- is a characteristic aroma component of these herbaceous peony cultivars.
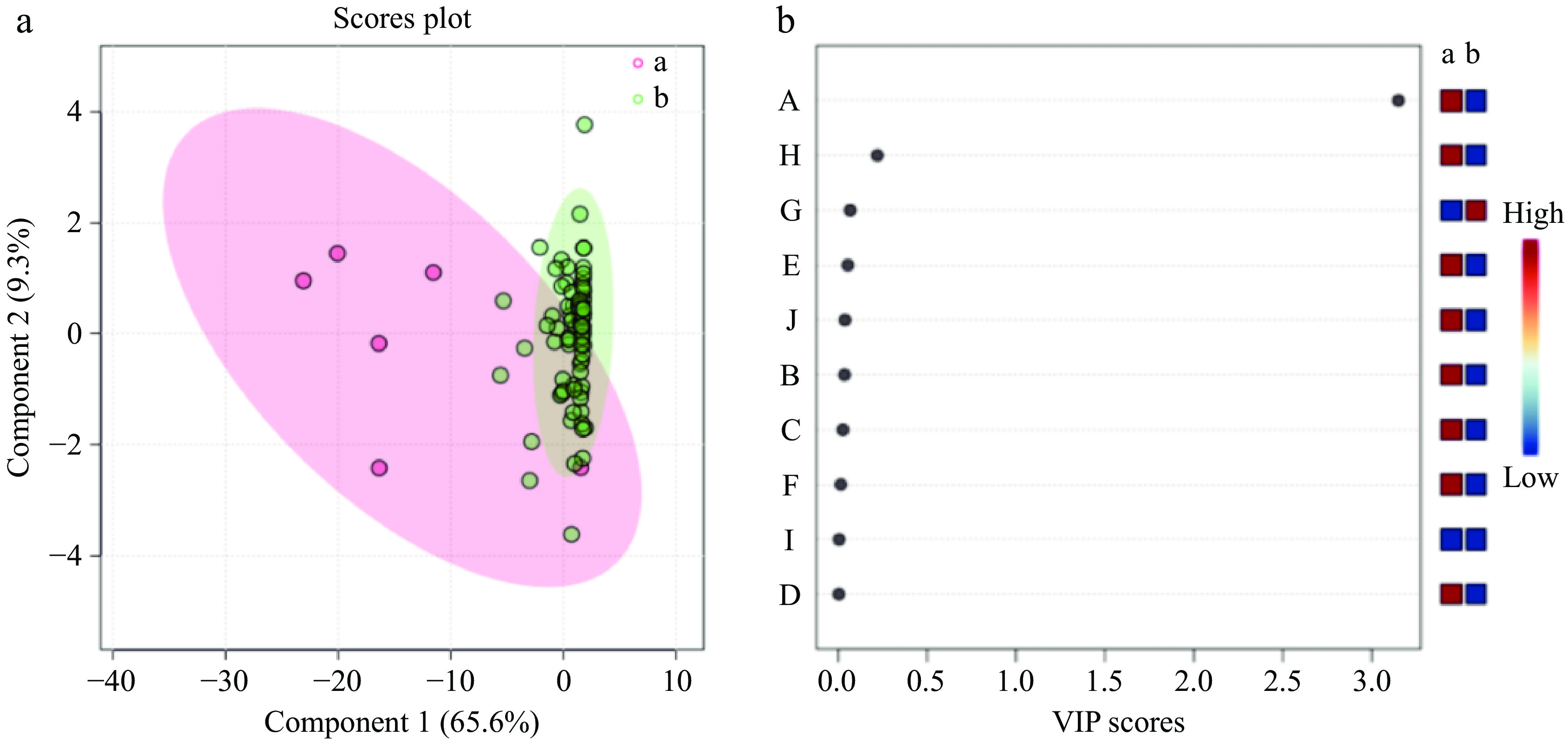
Figure 5.
PLS-DA scores of 100 herbaceous peony cultivars under two cluster groups.
Variables A and B represent the first and second categories, respectively. The specific variables include A-Benzene,1,4-dimethoxy-, B-Citronellol, C-Nerol, D-Acetic acid, 2-phenylethyl ester, E-Methyl cinnamate, F-Dimethyl phthalate, G-(Z)-β-ocimene, H-Phenylethyl alcohol, I-Butylated hydroxytoluene, J-Dibutyl phthalate.
-
The present study comprises a comprehensive identification and analysis of the volatile constituents present in 100 herbaceous peony cultivars during the half-opening stage. The findings indicated that alkanes, alcohols, and ethers were the most prevalent volatile compounds, with benzene,1,4-dimethoxy- was identified as the distinctive aromatic components.
One such molecule is benzene,1,4-dimethoxy-, a methoxylated aromatic volatile compound that is known to elicit physiological and behavioral responses in a diverse range of insect pollinators. It serves as a principal floral volatile in a number of plant species belonging to diverse genera, including Salix, Lithophragma, Nelumbo, Catasetum, Allium, and Fragaria[47]. Wang et al.[40] identified the common floral component, benzene,1,4-dimethoxy-, in all eight herbaceous peony cultivars. Furthermore, Kimani et al.[32] identified 95 volatile organic compounds in 24 herbaceous peony cultivars, including benzene,1,4-dimethoxy-, which is a phenolic methyl ether containing a benzene skeleton but not derived from aromatic amino acids. Rather, it is a member of a particular chemical class that is responsible for the olfactory characteristics of specific plant varieties. The types and contents of volatile components of herbaceous peonies may be associated with the sampling method, sampling location and time. Additionally, the types and contents of volatile compounds in plants may be influenced by different planting environmental conditions[48].
In recent years, there has been a growing emphasis on the natural floral volatiles present in herbaceous peonies, with the fragrance components demonstrating a diverse range of applications in the fields of healthcare, perfumes, and cosmetics[49]. Floral scent represents a significant component of plant volatiles, which are primarily composed of terpenes, aromatic hydrocarbons, fatty acids, and their derivatives, as well as sulfur and nitrogen-containing compounds[27,50]. These compounds are taxonomically categorized into three primary classes, contingent upon their biogenic origins, namely fatty acid derivatives, phenylpropanoids/benzenoids, and terpenoids[51]. In the present study, the volatile components of the 100 cultivars of herbaceous peony were predominantly identified as alkanes, esters, and alcohols. The most abundant type of compound was identified as alkanes. The available evidence suggests that straight-chain alkanes represent the primary constituents of plant leaf wax[52]. These waxes are not exclusive to leaves but may also be found on other plant organs, including flowers and fruit surfaces[53]. This indicates that wax layers may cover the surfaces of the majority of herbaceous peony cultivars. Alcohols play a significant role in the fragrance industry, serving as essential raw materials for synthetic fragrances and as an indispensable component in perfumery[54]. The presence of abundant ether compounds results in the production of pleasant floral and fruity aromas, while simultaneously enhancing the richness, typicality, and complexity of plant fragrances[55].
However, due to the constraints of the existing literature, some volatile components, such as specific alkanes, have not yet been conclusively identified as fragrance components. Further research is required to ascertain whether these components contribute to the fragrance of herbaceous species. Alkane compounds have relatively high thresholds[56] and make minimal contributions to the overall scent[28]. Accordingly, the analysis of fragrance compounds excludes the contributions made by nonane, decane, pentadecane, hexadecane, heptadecane, and tetracosane.
-
This study employed dynamic headspace bag adsorption of live plant materials and gas chromatography-mass spectrometry (GC-MS) analysis techniques to identify a total of 16 volatile components in 100 herbaceous peony cultivars at the half-opening stage[57]. The components were primarily categorized into six major groups: alkanes, esters, alcohols, terpenes, ethers, and phenols. The predominant volatile compounds were alkanes, alcohols, and ethers, while benzene,1,4-dimethoxy- was identified as the main aromatic component. Significant variations in the total content of the main aromatic components were observed among the different herbaceous peony cultivars at the half-opening stage. In particular, P. lactiflora 'Taohua Huancai', P. lactiflora 'Xishifen', P. lactiflora 'Dabanhong', P. lactiflora 'Fumantang', and P. lactiflora 'Zhushapan' exhibited the highest content of aromatic components, resulting in a more intense floral fragrance. The intensity and characteristics of the aroma exhibited notable variation among different herbaceous peony cultivars, attributable to differences in the quantity and composition of the aromatic components. This is a crucial indicator for evaluating the quality of herbaceous peony. This study provides a theoretical foundation for understanding the formation and regulation mechanisms of herbaceous peony aroma characteristics, while also offering technical support for accelerating industrial development and utilization of herbaceous peony aromas.
This research was funded by the Science and Technology Innovation Talents in Universities of Henan Province (Grant No. 22HASTIT036) and the Project of Henan Province Traditional Chinese Medicine Industry Technology System (Grant No. 2024-24).
-
The authors confirm contribution to the paper as follows: study conceptualization, reviewing, editing and funding acquisition: Guo L; material preparation: Wang A, Luo Y, Niu T, Zhao X, Gao K; data curation: Wang A, Luo Y, Niu T, Wang S; draft manuscript preparation: Wang A, Luo Y; manuscript reviewing and editing: Hou X. All authors reviewed the results and approved the final version of the manuscript.
-
All data generated or analyzed during this study are included in this published article.
-
The authors declare that they have no conflict of interest.
-
# Authors contributed equally: Aixin Wang, Yasang Luo
- Copyright: © 2024 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Wang A, Luo Y, Niu T, Gao K, Wang S, et al. 2024. Identification and content analysis of volatile components in 100 cultivars of Chinese herbaceous peony. Ornamental Plant Research 4: e032 doi: 10.48130/opr-0024-0029 

Identification and content analysis of volatile components in 100 cultivars of Chinese herbaceous peony
- Received: 02 July 2024
- Revised: 11 September 2024
- Accepted: 12 October 2024
- Published online: 11 December 2024
Abstract: Herbaceous peony (Paeonia lactiflora Pall.) is a well-known and traditional flower in China, occupying a significant position in Chinese traditional culture. The floral scent of the herbaceous peony however remains relatively understudied. The objective of this study was to investigate the floral composition of herbaceous peony by collecting and identifying floral volatiles from 100 cultivars, including P. lactiflora 'Hangbaishao', P. lactiflora 'Hongrongqiu', P. lactiflora 'Biandihong', P. lactiflora 'Zijin Daipao', P. lactiflora 'Zixia Yingxue', and P. lactiflora 'Fenchi Dicui'. The volatile compounds were collected using the dynamic headspace technique and identified through gas chromatography-mass spectrometry (GC-MS). The results demonstrated qualitative and quantitative variations in the floral fragrances emitted by the 100 cultivars, with a total of 16 volatiles belonging to six categories (six alkanes, three alcohols and esters, two terpenes, as well as one each of ether and phenol) being identified. However, it is notable that not all volatile categories were emitted by every cultivar. Moreover, while some compounds were present in all 100 herbaceous peony cultivars, others were exclusive to specific cultivars. The screening revealed that ten of the 16 identified flower volatile compounds exhibited unique floral components. It is noteworthy that benzene,1,4-dimethoxy-, was identified as the most prominent compound in several cultivars, including P. lactiflora 'Taohua Huancai', P. lactiflora 'Xishifen', P. lactiflora 'Dabanhong', P. lactiflora 'Fumantang', and P. lactiflora 'Zhushapan'. Furthermore, the clustering classification results demonstrated that benzene,1,4-dimethoxy-, exhibited the highest variable importance in projection (VIP) value of 3.153, as determined by partial least squares discriminant analysis (PLS-DA).
-
Key words:
- Herbaceous peony /
- Volatile components /
- Aroma compounds /
- Cluster analysis