










-
Olive (Olea europaea L.) is the second-most important fruit oil crop grown worldwide[1]. Six subspecies have been defined for Olea europaea L: subsp. europaea (diploid) and five non-cultivated subsp. laperrinei (diploid), cuspidata (diploid), guanchica (diploid), maroccana (polyploid 6n), and cerasiformis (polyploid 4n)[2]. The subsp. europaea is represented by two botanical varieties: cultivated olive and wild olive[2]. Olive contains a significant number of bioactive compounds such as secoiridoids, phenolic compounds, and carotenoids. There has been significant attention on the fatty acids of olive fruit and its oil. In addition to ripe olive fruits, the leaves, flowers, and young fruits of olive also contain a range of bioactive components, including polyphenols, organic acids, terpenes, and others. The leaves and flowers of olive are rich in phytochemicals such as rutin and luteolin, which have antioxidant properties[3]. Studies indicate that the leaf and fruit extracts of olive have great therapeutic capacity and beneficial activities that are useful for fighting various pathologies. People in the Middle East make tea from olive leaves, which is widely used to treat coughs, sore throats, fever, and cystitis[4]. Olive leaves can be directly used for stomach and intestinal diseases. Its dried leaves can treat diarrhea and urinary tract infections, and its leaf extract can treat hypertension and bronchial asthma[5].
Modern medical science has also confirmed the efficacy of olive extracts. Olive leaves are valued for their phenolic compounds, triterpenic acid, and flavonoids. Caffeic acid, verbascoside, oleuropein, luteolin 7-O-glucoside, rutin, apigenine 7-O-glucoside, and luteolin 4'-O-glucoside are phenols that have been detected in the leaves[6]. Functional products made from olive leaves are applied in the form of liquid extracts or tablets for anti-diabetes, anti-hypertension, and anti-cold treatments, relieving cardiovascular diseases and fatigue syndrome, and enhancing immunity[7]. Split iridoids, considered to be the chemical taxonomic marker compounds of Oleaceae, are a subclass of cycloalkenyl ethers derived from the cleavage of the cyclopentane ring at the seventh and eighth bonds of the phenol-containing moiety[8]. Oleuropein, one of the cleavage iridoids, is present in the leaves and fruits of olive. It consists of hydroxytyrosol, elenolic acid, and glucose. It is the most abundant phenolic for most olive tree cultivars and has a characteristic bitter taste[9].
The components in olive leaves, flowers, and young fruits have great potential for extended industrial dietary applications. These underutilized leaves, flowers, and fruits could be health-promoting resources. However, they have had limited commercial utility so far because their constituents and contents are unclear. Large amounts of leaf residue are produced during the cultivation of olive. During pruning, the amount of leaf by-products roughly accounts for 25% of the total weight of the pruned residue[10]. The fruit-to-flower ratio is very low in olive, ranging from 5%−6%[11]. This implies that the majority of flowers drop and do not develop into fruits. Additionally, excess flowers and fruits in 'on' years are removed to increase the number of developing flowers by pruning[12]. Presently, commercial applications of olive leaves are mostly limited to animal feed and folk medicine rather than clinical drugs, with application in protecting against chronic conditions such as cardiovascular disease and diabetes[13,14]. Therefore, the current study explored the classifications and characteristics of compounds in tea made from olive leaves, flowers, and fruit. Our findings will provide basic information on the chemical compositions of biomass residues from olive trees, which may help improve their economic potential.
-
Olive cultivars 'O. europaea subsp. europaea var. Arbequina' were planted at the Olive Industry Comprehensive Development Demonstration Base of Qingtian, Zhejiang, China. One to three leaves below the terminal bud, freshly unfolding flowers, and young fruits at 30 d after flowering in the spring of 2023 were sampled. Each sample was taken from at least three olive trees.
Olive tea manufacturing process
-
Olive tissues were fixed at 300 °C for 3 to 8 min. In this step, the color of leaves and young fruits turned to dark green, the color of flower turned to golden yellow, the tissues became soft and raw flavor was disappeared. Afterwards, the fixed tissues were dried at 120 °C for 30 min. Subsequently, they were cooled at room temperature. Finally, they were dried at 80 °C until the moisture content was below 4.00%.
Metabolite detection by UPLC-Q-Orbitrap
-
Two grams of powdered olive tea samples were combined with 10 mL of 70% methanol with an internal standard (0.025 mg/mL of sulfacetamide). The mixture was extracted in an ultrasonic unit (Branson 5510, USA) at 40 °C for 30 min. After extracting at 4 °C in the dark for 2 h, the supernatants were filtered through a 0.22 μm filter membrane and stored at −80 °C until injection. A QC sample was prepared by mixing 100 μL of extracts from all samples.
The composition of the samples was detected using an ultra-high-performance liquid chromatography (UPLC) (Thermo Scientific Dionex Ultimate 3000, USA) - Q - Orbitrap (Thermo Scientific Q Exactive, USA). The column was an Agilent SB-AQ C18 column (1.8 μm, 2.1 mm × 100 mm, USA). Solvent A was water containing 0.1% formic acid, and solvent B was acetonitrile. The injection volume was 2 μL, and the flow rate was 0.3 mL/min. The column temperature was 40 °C. The gradient evolution program was as follows: 0–10 min, 5%–20% B; 10–16 min, 20%–95% B; 15–17 min, 95% B; 17–20 min, 95%–5% B. The ion source was electrospray ionization, and the source temperature was 550 °C; the normalized collision energy was 15, 30, and 60; the isolation window was 4.0 m/z (mass-to-charge ratio); the loop count was 10; the dynamic exclusion was 10.0 s; positive and negative modes with electrospray ionization were operated at 3.50 and 3.20 kV of capillary voltage, respectively; and the temperatures of the drying gas and aux gas were 320 °C and 350 °C, respectively. The first mass range was set between 70 and 1,200 at a resolution of 70,000, and the second mass range was set between 70 and 1200 at a resolution of 17,500. The automatic gain control was 1e5. The QC sample was injected every nine samples.
Quantitative determination of fatty acids by GC
-
The dried fruits were ground into powders. Then 4 mL of isooctane and 340 μL of methanol containing 2 mol/mL of potassium hydroxide were added to 0.200 g of powers. They were standing for 30 min after entirely mixing. Four milliliters of saturated NaCl water were added and standing for 30 min. The supernatant was filtered with a 0.22 μm of microporous membrane and stored at −80 °C for gas chromatogram (GC) analysis. The fatty acids were aligned to standards.
Column: HP-88 (Aglient Technologies, USA, 30 m × 250 μm × 0.2 μm); Initial temperature: 70 °C, 1 min; Rate 1: 70 °C, 1 min. Rate 2: 120 °C, 7.5 min. Rate 3: 230 °C, 46 min; injection Volume: 1 μL; split ration: 25:1; split flow: 1.5 mL/min; temperature: 250 °C; FID detector temperature: 270 °C; H2 flow: 35 mL/min; air flow: 400 mL/min; N2 flow: 30 mL/min.
Data processing
-
The standard database was established in the software mzValut based on the name, mass-to-charge ratio, and file location of the standards. The secondary mass spectrometry files of compounds were placed into the software and aligned to the standard. The mass weight, retention time, and secondary mass spectrometry of the rest compounds were aligned to the compounds in public databases, including Kyoto Encyclopedia of Genes and Genomes (KEGG) (
www.kegg.jp ) and PlantCyc (www.plantcyc.org ). The compounds were quantified based on the peak area of the first mass spectrometry and checked against an internal standard. A tangent line at the peak top point was drew and the area was calculated between the tangent line and background line. The absolute quantitation of fatty acids was calculated based on standard curve.Data analysis
-
Scree plots, principal component analysis (PCA) and partial least squares-discriminant analysis (PLS-DA) based on the metabolites were produced using the R (www.r-project.org) package ggplot2. The samples were divided into several groups based on the PCA. A Venn diagram was analyzed and visualized using the package VennDiagram. Metabolites in every two groups with fold change > 2 and false discovery rate (FDR) < 0.05 were regarded as differentially accumulated metabolites (DAMs) using the package DESeq. The volcano plots were plotted using the package ggplot2 according to the DAMs. Fold changes in the relative contents of metabolites were calculated according to the formula: variability = maximum/minimum. The PCC between the content of two compounds was calculated based on the method 'pearson' in the package corrplot. The contents of compounds with PCC > 0.8 and FDR < 0.05 were used to construct correlation networks using Cytoscape 3.9.1. The KEGG enrichment of the DAMs was conducted using the package clusterProfiler, dplyr, and ggplot2.
-
The compound compositions in tea made from the leaves, flowers, and young fruits of olive were determined and annotated through secondary mass spectrometry comparison. Three strategies were performed to annotate detected compounds. Firstly, the retention time, parent ions and secondary fragments of compounds were aligned to those in the standard database; Secondly, the parent ions and secondary fragments of the rest compounds were aligned to those in the public database; Lastly, for the substances which could not be compared in the standard or public database, annotations were made according to the mass spectrometry information reported in the literature. A total of 607 metabolites were identified via this method, which could be classified into 20 groups. The top three types were organic acids, amino acids and their derivatives, and esters (Fig. 1a). In order to explore the metabolic variance among the teas made from the three different tissues, PCA, and PLS-DA were performed based on the metabolite content. As described in the score plots (Fig. 1b), the first two principal components (PCs) accounted for the majority of the separation in the data. PC1 and PC2 accounted for 38.70% and 22.40% of the variation, respectively (Fig. 1c). The quality control (QC) samples were distributed in the center and the other samples scattered around them, indicating that the detector was stable (Fig. 1c). Additionally, PLS-DA also exhibited the same results (Fig. 1d). The PCA and PLS-DA suggested obvious differences in the constituents and contents of the metabolites among the teas made from the leaves, flowers, and fruits, which requires further analysis.
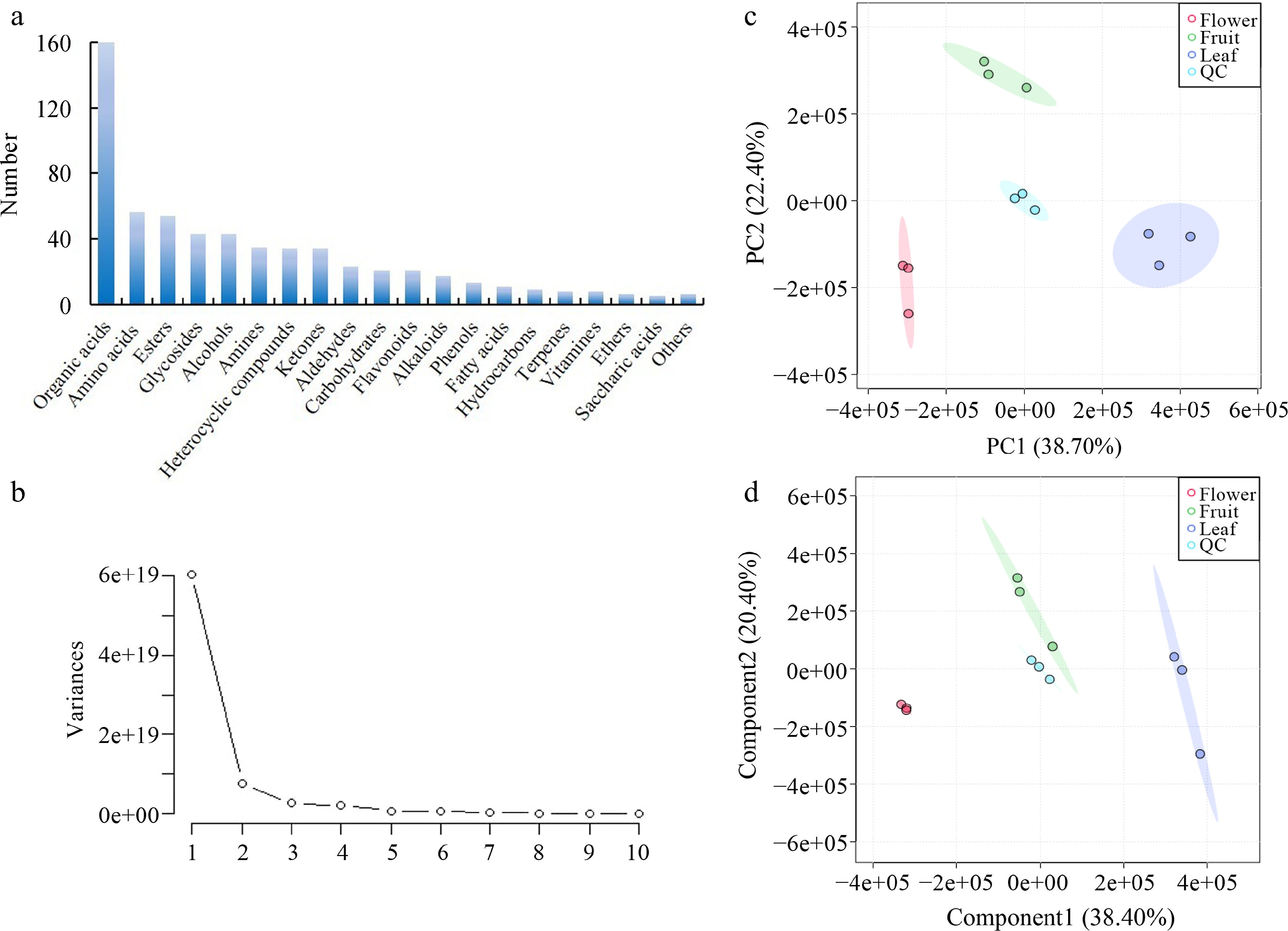
Figure 1.
Overview of the metabolites in three types of tea made from olive leaves, flowers, and fruits. (a) Classification of the metabolites; (b) scree plot of the metabolites; (c) PCA plot of the metabolites; and (d) PLS-DA plot of the metabolites.
Differentially accumulated metabolites
-
The differentially accumulated metabolites (DAMs) were analyzed to further compare the tissue diversity. As shown in Fig. 2a, both common and unique metabolites were found among the different sample types. Specifically, the leaf vs flower, leaf vs fruit, and flower vs fruit comparisons shared 129 common DAMs. In detail, 252 DAMs were found between leaf vs flower and leaf vs fruit; a total of 245 DAMs were found between leaf vs flower and flower vs fruit; and a total of 170 DAMs were found between flower vs fruit and leaf vs fruit. Volcano plots were drawn to visualize the variation between the three types of olive tea. There were 190 and 208 up- and down-regulated DAMs between the leaf and floral tea (Fig. 2b), 160 and 152 up- and down-regulated DAMs between the leaf and fruit tea (Fig. 2c), and 167 and 135 up- and down-regulated DAMs between the flower and fruit tea (Fig. 2d).
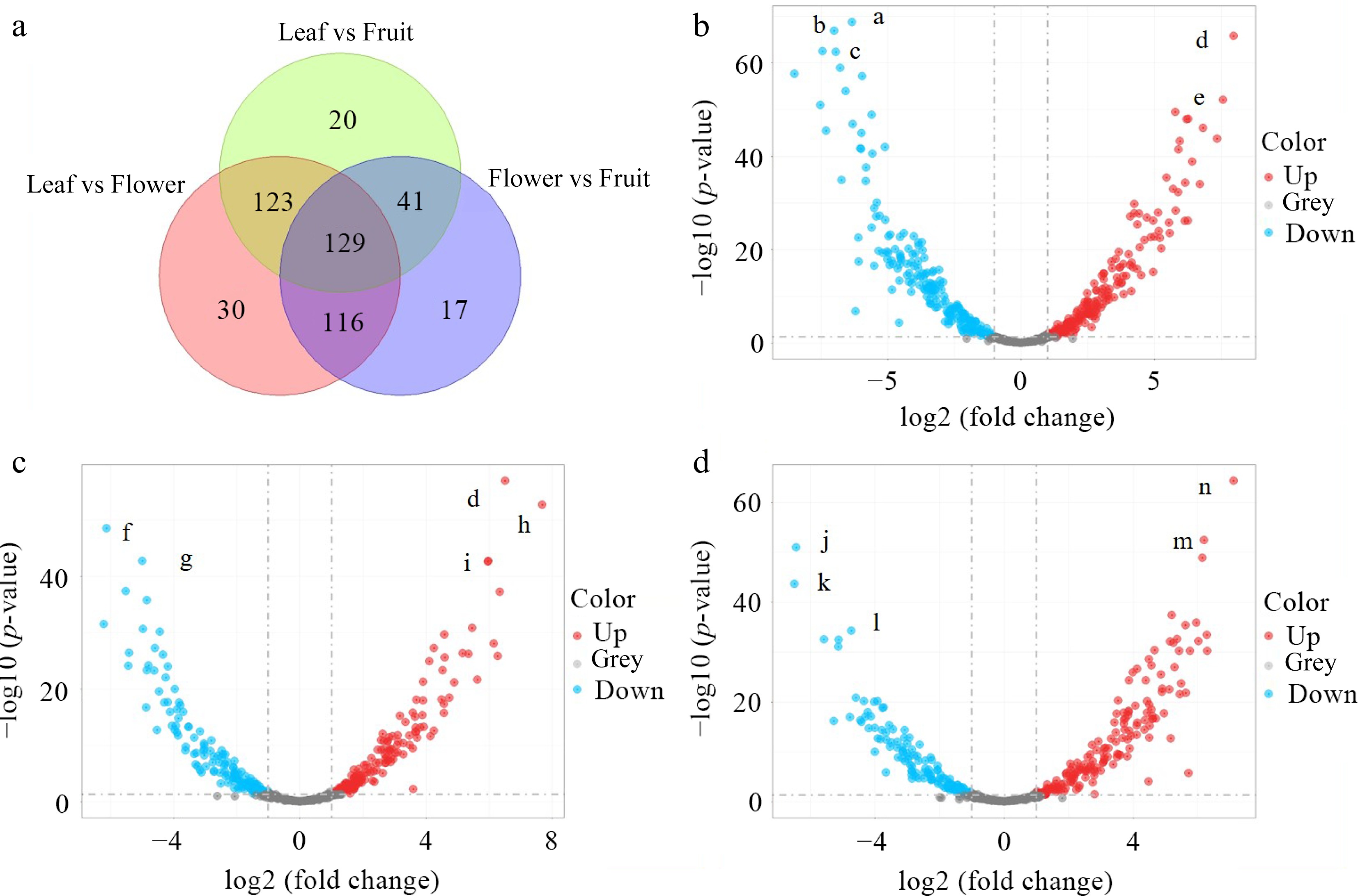
Figure 2.
DAMs among the teas made from the three tissues. (a) Venn diagram of metabolites; (b) volcano plots of DAMs between the leaf tea and floral tea; (c) volcano plots of DAMs between the leaf tea and fruit tea; and (d) volcano plots of DAMs between the floral tea and fruit tea. (a, Genipin gentiobioside; b, His-pro; c, Methyl dihydrojasmonate; d, Vitamin C; e, Yatein; f, 4-Allyl-2-methoxyphenyl 6-O-beta-D-xylopyranosyl-beta-D-glucopyranoside; g, 14,18-Dihydroxy-12-oxo-9,13,15-octadecatrienoic acid; h, Leiocarposide; i, Pyrogallol-2-O-glucuronide; j, 2-Amino-5-[2-(4-formylphenyl)hydrazino]-5-oxopentanoic acid; k, Methyl dihydrojasmonate; l, Senkyunolide H; m, Esculin; n, Dhurrin).
The top-20 DAMs in the tea made from two tissues were further explored. The contents of proline (o338), gly-phe (o405), and 2-phytyl-1,4-dihydroxynaphthalene (o539) in the floral tea were more than 172 times higher than that in the leaf tea, while the contents of 2-phytyl-1,4-dihydroxynaphthalene (o359), vitamin C (o167), and yateino (397) in the leaf tea were more than 163 times higher than that in the floral tea (Fig. 3a). The contents of 1,5-octadien-3-one (o256), 4-amino-3-hydroxybenzoic acid (o213), and 3-(3,4-dihydroxyphenyl)-2,7,8-trihydroxy-1,4-dibenzofurandione (o423) in the fruit tea were more than 45 times higher than that in the leaf tea, while the contents of vitamin C (o167), leiocarposide (o332), and pyrogallol-2-O-glucuronide (o169) in the leaf tea were more than 81 times higher than that in the fruit tea (Fig. 3b). The content of trans-methyl dihydrojasmonate (o359), dihydroquercetin (o423), and esculin (o285) in the fruit tea were more than 48 higher than that in the floral tea, while the content of 2-amino-5-[2-(4-formylphenyl) hydrazino]-5-oxopentanoic acid (o174), dhurrin (o394), and palmitelaidic acid methyl ester (o529) in the floral tea were more than 78 times higher than that in the fruit tea (Fig. 3c).
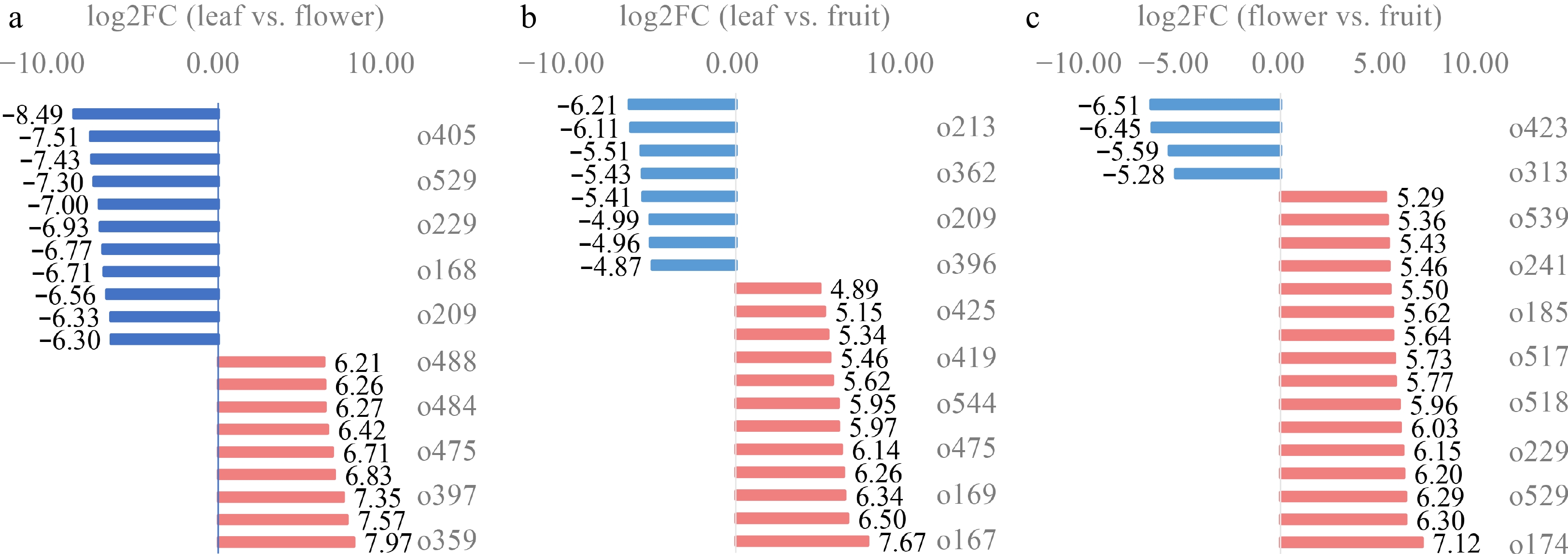
Figure 3.
Fold changes in the top-20 DAMs. (a) The fold change between the leaf tea and floral tea; (b) the fold change between the leaf tea and fruit tea; and (c) the fold change between the floral tea and fruit tea.
Network of common DAMs
-
A total of 129 DAMs were enriched into KEGG pathways. As described in Fig. 4a, most of them were in the amino acid metabolism pathway, including alanine, aspartate and glutamate metabolism, tyrosine metabolism, and butanoate metabolism. To further investigate the relationship between these DAMs, a network based on Pearson's correlation coefficient (PCC) was constructed. As described in Fig. 4b, His-pro (o209), (–)-trans-methyl dihydrojasmonate (o359), Gly-Phe (o405), and 14,18-dihydroxy-12-oxo-9,13,15-octadecatrienoic acid (o541) were in the center of the network, indicating they were the most closely-related metabolites. (–)-Trans-methyl dihydrojasmonate is a methyl jasmonate analogue with stable chemical properties. It is widely used in cosmetics and perfume because of its unique fragrance and safety based on risk assessment[15]. It also has anti-tumor pharmacological activity in the medical field[16]. It was closely connected with 46 DAMs (Fig. 4b). His-pro (o209) and Gly-Phe (o405) are dimers of amino acids. Furthermore, methyl dihydrojasmonate, which has a powerful sweet-floral, jasmine-like, somewhat fruity odor, is an ingredient used in many fragrance mixtures[17]. (–)-Trans-methyl dihydrojasmonate (o359) was simultaneously connected with another three subgroups, revealing that it is the DAM with greatest influence, and its content was highest in the leaf tea (Fig. 4c). His-pro (o209), Gly-Phe (o405) and 4,18-dihydroxy-12-oxo-9,13,15-octadecatrienoic acid (o541) were highest in the floral tea and lowest in the leaf tea (Fig. 4c).
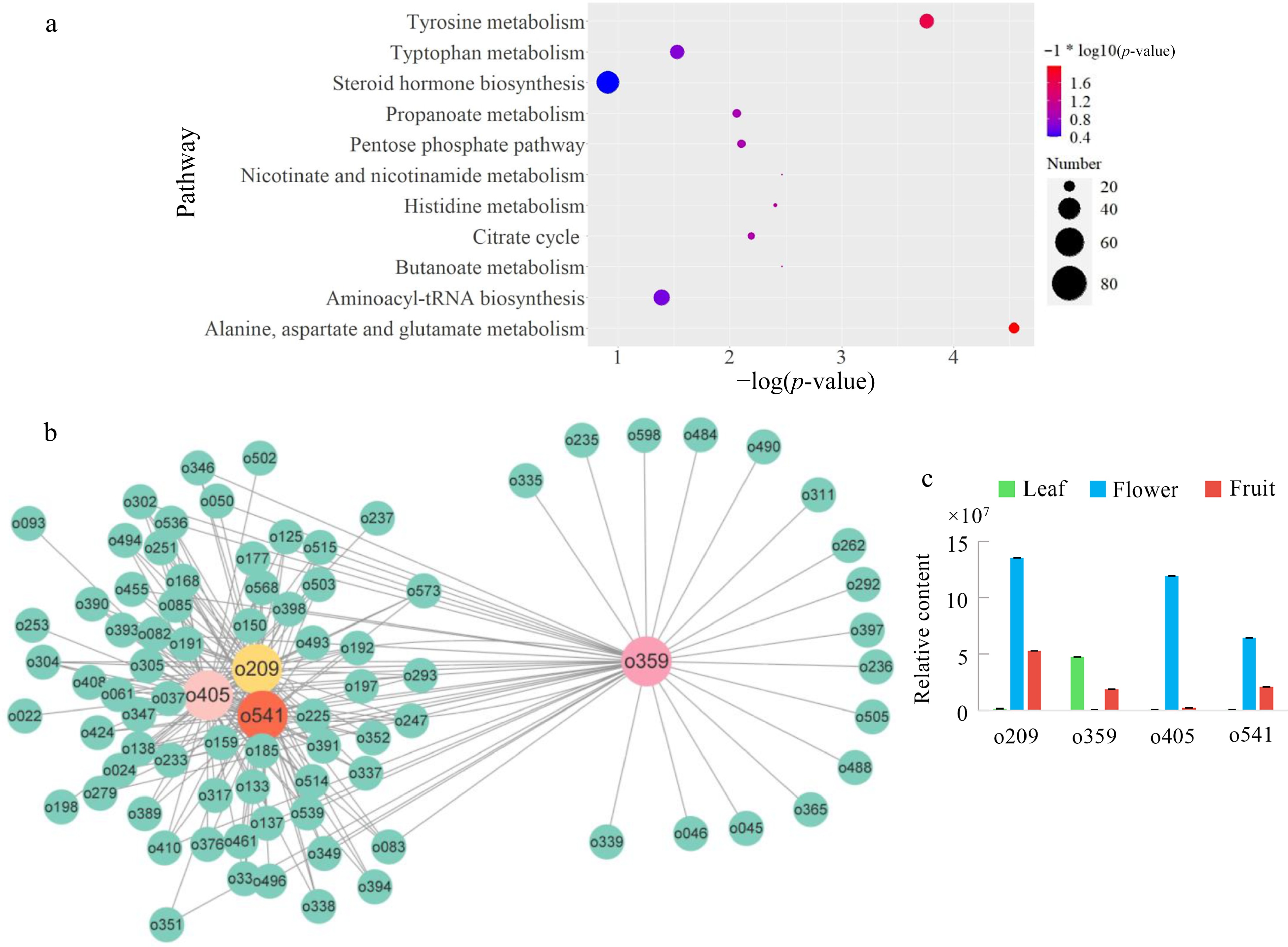
Figure 4.
Common DAMs between the three issues. (a) KEGG enrichment of common DAMs; (b) An interactive network of common DAMs; (c) Comparison of the contents of center DAMs. (o209, His-pro; o405, Gly-Phe; o541, 4,18-dihydroxy-12-oxo-9,13,15-octadecatrienoic acid).
Variation in terpenes and glycosides in olive teas made from the three tissues
-
The flavor and taste of leaves, flowers, and fruits are usually determined by terpenes. To explore the variation in terpenes in the three types of olive tea, the contents of terpene monomers were subsequently compared. A total of eight terpenes were identified in olive, four of which were DAMs between different tissues. As presented in Fig. 5a–d, the content of α-farnesene, 1,2,3,4-tetramethyl-1,3-cyclopentadiene, 3,4-dihydrocadalene, and α-farnesene was remarkably higher in the leaf tea than in the floral tea and fruit tea, while the content of anthumin was significantly higher in the fruit tea than in the leaf tea and floral tea. Farnesene is synthesized from the precursor farnesyl pyrophosphate. The latter is produced via the mevalonate pathway or the 2-C-methyl-D-erythritol-4-phosphate pathway[18]. It belongs to the sesquiterpene family with applications as a fragrance, and is also a precursor for the synthesis of vitamin E and K1[19], which is of great economic value in medicine, cosmetics, condiments, and bioenergy. Farnesene is one of the pheromones released by aphids when exploited in agricultural production, and aphids exposed to a farnesene environment will suffer abnormal growth and reproduction[18]. Here, α-farnesene mainly accumulated in the leaf tea, which may help in the protection of olive against certain biotic stresses.
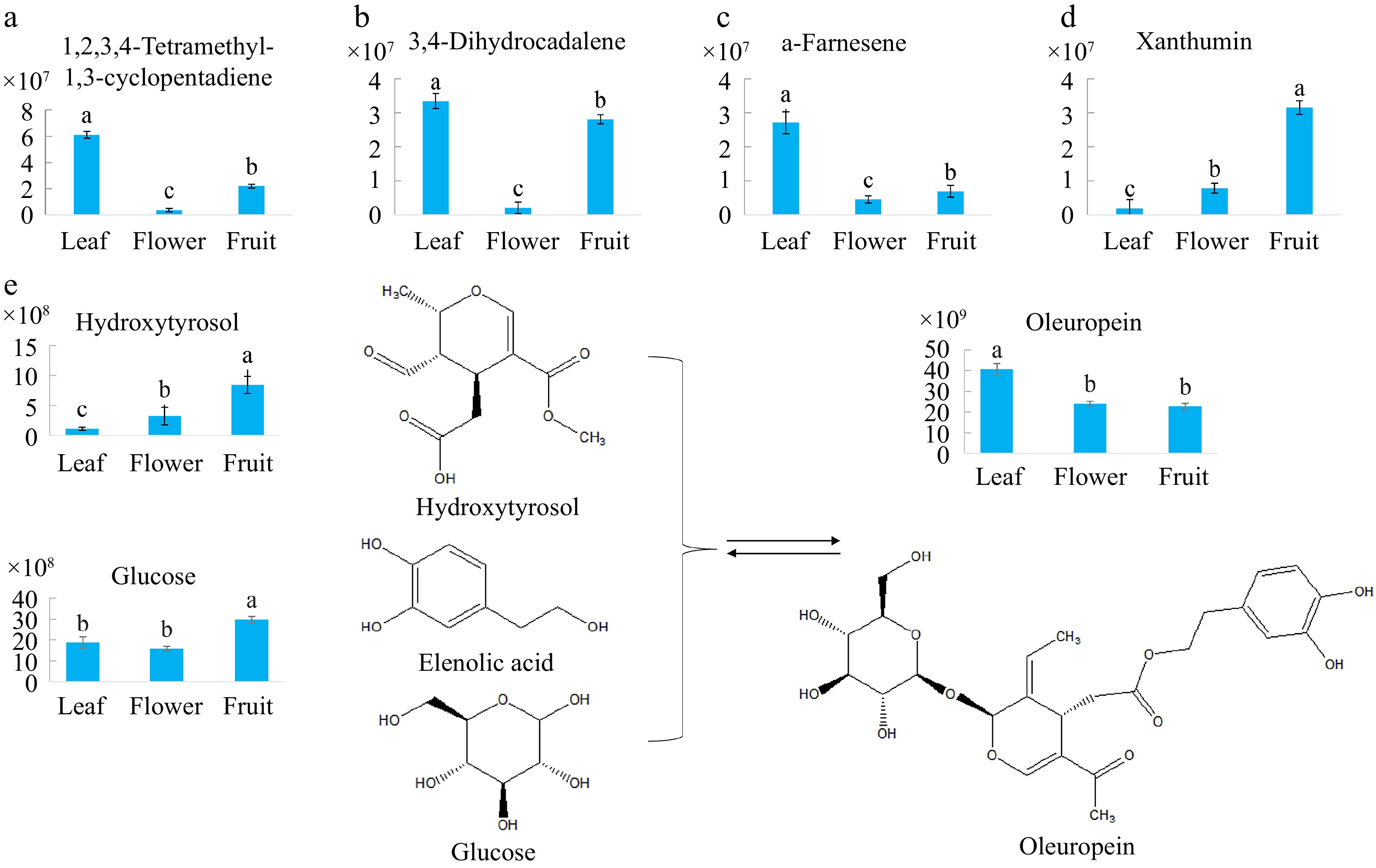
Figure 5.
Comparisons of the contents of representative terpenes and glycosides in olive tea made from the three tissues. (a) 1,2,3,4-Tetramethyl-1,3-cyclopentadiene; (b) 3,4-Dihydrocadalene; (c) α-farnesene; (d) Xanthumin; (e) The principal components in the oleuropein metabolic pathway. Bars with the same lowercase letters are not significantly different based on the least significant difference test.
In addition to terpenes, glycosides are another group of compounds that contribute to the flavor and taste of olive products. There were 13 differentially accumulated hexosides among the three tissues (Table 1), ascorbyl glucoside, leiocarposide, phloridzin, acanthoside B, and chryso-obtusin glucoside accumulated obviously in the leaf tea. Genipin gentiobioside, rutinose, baimaside, quercetin-3β-D-glucoside, dhurrin, and 4-oxo-2-phenyl-4H-chromen-3-yl 6-O-beta-D-xylopyranosyl-beta-D-glucopyranoside significantly accumulated in the floral tea. Only abietin and 4-allyl-2-methoxyphenyl 6-O-beta-D-xylopyranosyl-beta-D-glucopyranoside markedly accumulated in the fruit tea. Additionally, two of them were flavonoid glycosides, namely baimaside (o390) and quercetin-3β-D-glucoside (o391). The content of baimaside and quercetin-3β-d-glucoside was highest in the floral tea (Table 1).
Table 1. The differentially accumulated glycosides in the olive tea made from three tissues.
Name Formular Peak area Leaf Flower Fruit Ascorbylglucoside C12H18O11 6E+08 4E+07 2E+08 Leiocarposide C27H34O16 4E+07 3E+06 601326 Phloridzin C21H24O10 2E+07 5E+06 691518 Acanthoside B C28H36O13 3E+07 3E+06 1E+07 Chryso-obtusinglucoside C25H28O12 2E+07 4E+06 9E+06 Genipingentiobioside C23H34O15 7E+07 6E+09 5E+08 Rutinose C12H22O10 7E+05 3E+08 1E+07 Baimaside C27H30O17 2E+08 1E+10 7E+08 Quercetin-3β-D-glucoside C21H20O12 2E+07 9E+08 5E+07 Dhurrin C14H17NO7 5E+05 2E+07 395706 4-Oxo-2-phenyl-4H-chromen-3-yl 6-O-beta-D-xylopyranosyl-beta-D-glucopyranoside C26H28O12 2E+06 2E+07 4E+06 Abietin C16H22O8 2E+07 8E+06 4E+07 4-Allyl-2-methoxyphenyl 6-O-beta-D-xylopyranosyl-beta-D-glucopyranoside C21H30O11 3E+05 1E+06 1E+07 Oleuropein is a compound with a natural split iridoid skeleton in olive and is synthesized from hydroxytyrosol, elenolic acid, and glucose. It is organoleptically characterized by a strong bitterness and exists in the leaves, roots, stems, fruits, and kernels of olive[20]. It can ameliorate diabetes by decreasing oxidative stress when treating diabetes complications[20]. Oleuropein improves mitochondrial function by activating nuclear factor E2-related factor-mediated signaling pathways, protects the paraventricular nucleus of the hypothalamus from oxidative stress, and reduces the expression of renin-angiotensin, thereby lowering blood pressure[21]. In the current study, the contents of oleuropein in the leaf, flower, and fruit tea were compared. The result showed that the oleuropein content was highest in the leaf tea (Fig. 5e), which is consistent with Jensen et al.[8]. On the contrary, hydroxytyrosol and glucose, two precursors of oleuropein, accumulated the most in the fruit tea (Fig. 5e). Same as oleuropein, hydroxytyrosol is a typical phenol in olive and is synthesized in the phenylpropanoid pathway[22]. Hydroxytyrosol generally offers health benefits in terms of antioxidation, anti-inflammation, and resisting neurological disorders[23,24]. Phenols possess antioxidation capacity. In the present study, a total of 44 phenolic compounds were detected in the floral tea (Supplemental Table S1). As a polyphenol, the antioxidation function of hydroxytyrosol relies on its ability to inhibit free radicals such as superoxide anion by donating hydrogen atoms from hydroxyl groups.
Variation in fatty acids of olive tea made from the three tissues
-
The composition of fatty acids in olive were special compared to other oil plants. During the manufacturing process, fatty acids were more stable than other compounds. Therefore, the absolute contents of 13 fatty acids in three kinds of olive tea were quantified. As described in Fig. 6a, oleic acid, linoleic acid and palmitic acid were the top three fatty acids with the highest content, whose contents in the dry weight of fruit tea were greater than 2.8%. The content of all these fatty acids were dramatically higher in fruit tea than that of leaf tea and floral tea (Fig. 6a). Among them, oleic acid and linoleic acid were unsaturated fatty acids. The rest of fatty acids, including palmitoleic acid, heptadecanoic acid, heptadecenoic acid, stearic acid, linolenic acid, arachidic acid, arachidonic acid, behenic acid and tetrachloroic acid, widely varied in olive tea made from three tissues as well (Fig. 6b). Except for nutmeg acid, heptadecenoic acid and tetrachloroic acid, other fatty acids mainly accumulated in fruit tea (Fig. 6b). Additionally, the majority of fatty acids accumulated in fruit tea, while heptadecenoic acid mainly concentrated in leaf and floral tea (Fig. 6b). Fatty acids play an important role in flavor of food[25]. And the specific effect of their compositions on aroma and taste requires further study.
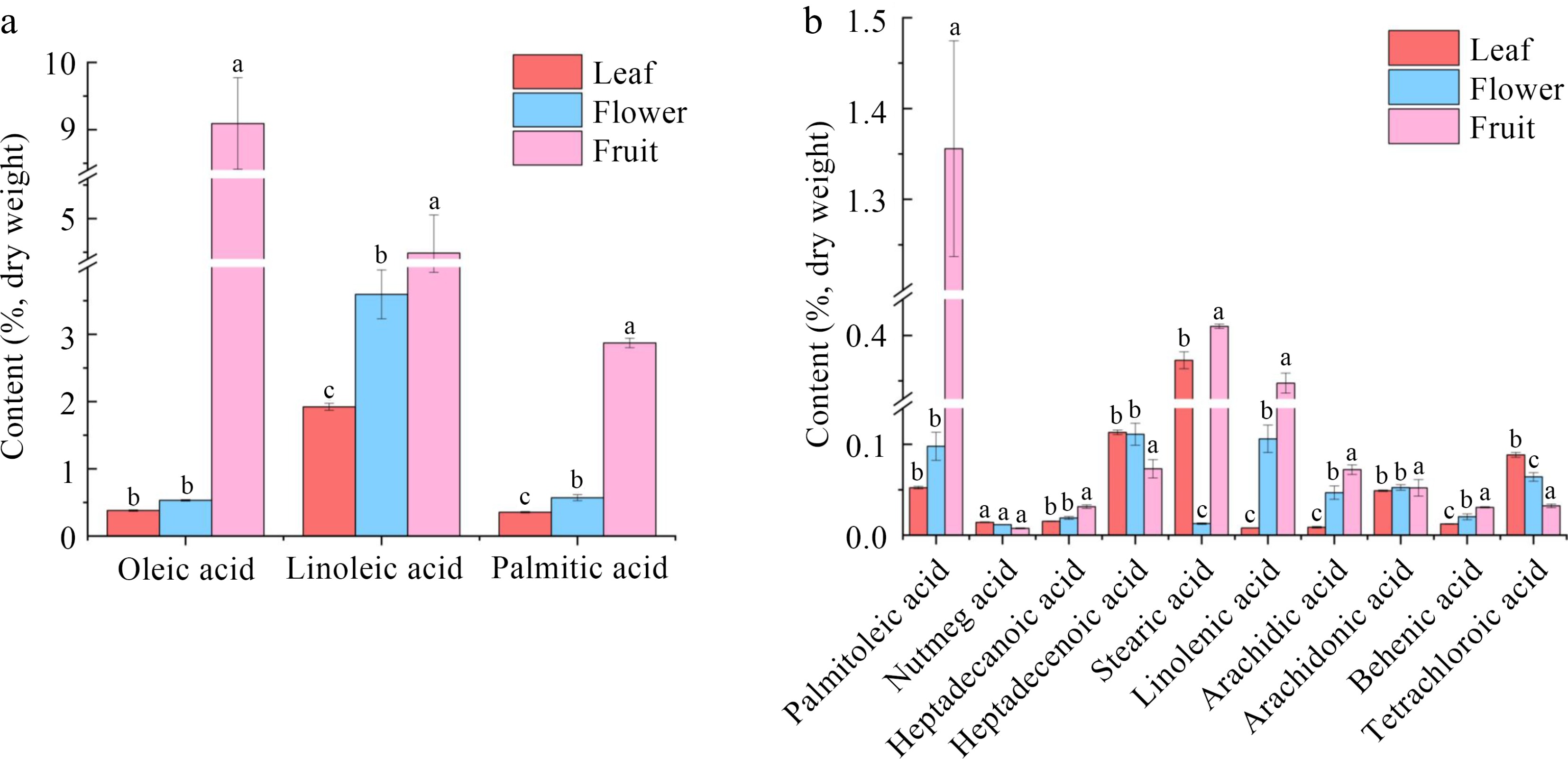
Figure 6.
Absolute quantitation of fatty acids in tea made from the three tissues. (a) Top three fatty acids with the highest content; (b) The rest of the fatty acids.
-
Olive leaves and flowers are usually abandoned as residues of olive groves. However, they possess different chemicals that could be used to produce natural products. In the present study, a total of 607 metabolites were detected in tea made from the leaves, flowers, and young fruits of olive (Supplemental Table S1), which were divided into 20 groups. Organic acids, amino acids and their derivatives, and esters were the most diverse compounds (Fig. 1a). Few studies have focused on the active components of olive flowers. Four phenolic groups, including secoiridoids, flavonoids, simple phenols, and cinammic acid derives, were detected in the olive flowers[26]. Hydroxytyrosol, hydroxytyrosol glucoside, lignans-pinoresinol, 1-acetoxypinoresinol, luteolin diglucoside, rutin, luteolin glucoside, luteolin rutinoside, diosmin, apigenin rutinoside, luteolin, taxifolin, apigenin-7-O-glucoside, chrysoeriol-7-O-glucoside, quercetin, diosmetin, and apigenin, and mainly oleuropein, ligstroside, oleuropein aglycone, oleuropein glucoside, acteoside, and isoacteoside, were present in the flowers[27]. The highest content of secoiridoids has been detected in unripe olive fruit extract, whereas the highest content of flavonoids has been detected in the flower buds[28]. Floral bud extracts generally show higher phenolic contents compared to the open flowers, young leaves, aged leaves, green fruit, and mature fruit[27]. In olive, flavonoids are the main phenolic class, and rutin is the dominant compound[26]. The content of rutin was higher in the floral tea than in the leaf tea and fruit tea (Supplemental Table S1). In addition, rutinose was identified in the floral tea.
Glycosides are the final form of rutin in plants and greatly determine their medicinal functions[29]. Rutinose is a promising non-polymeric additive for stabilizing amorphous drug formulations[30]. Rutin is composed of a hydrophobic flavonol skeleton (quercetin) and hydrophilic glucose. α-Glucosyl rutin is synthesized via the glycosylation of the sugar group of rutin and has been used as a functional food additive[31]. Glycosylation is an efficient way to decrease the solubility and increase the stability of flavonoids, thus modulating their bioactivities. In addition to flavonoid glycosides, other differential accumulated glycosides were also detected (Table 1). The aglycones were organic acid, phenol, and alcohol. The sugar donors mainly included glucose, rhamnose, galactose, xylose, arabinose, glucuronic acid, and apiose. The majority of sugars was hexose. The types and structures of hexose need to be further investigated through infrared spectroscopy and nuclear magnetic resonance.
A total of 11 fatty acids were identified, including common fatty acids such as octadecenoic acid and octadecatetraenoic acid (Supplemental Table S1). Except for 11-methyl-dodecenoic acid, other fatty acids evidently accumulated in the young fruit. It is likely that in the early fruit development stage, fatty acid biosynthesis occurs in the leaf, and most of the fatty acids are then transported into the fruits. Six dominant components, namely palmitic acid (C16:0), hexadecenoic acid (C16:1), stearic acid (C18:0), oleic acid (C18:1), linoleic acid (C18:2), and linolenic acid (C18:3), possess over 60% of the total fatty acids in the fruit at 50 d after flowering, and fatty acid degradation is highly active at the late developmental stages[28]. By comparison, there are six main fatty acids in olive oil: palmitic acid, palm oleic acid, stearic acid, oleic acid, linoleic acid, and linolenic acid[32]. This suggests that the composition of fatty acids is quite different between young and mature fruits. However, palmitic acid, hexadecenoic acid, stearic acid, linoleic acid, and linolenic acid were not detected in the young fruit tea in this experiment. This indicates that with maturation, significant transformation of fatty acids occurs. In addition, palmitic acid, oleic acid, linoleic acid, and oxidative stability differ significantly according to the region and cultivar, and therefore could be used as markers to distinguish the oil production region and cultivar[33]. 14,18-Dihydroxy-12-oxo-9,13,15-octadecatrienoic acid (o541), a polyunsaturated fatty acid, was in the center of the network (Fig. 5a). It was most abundant in the floral tea and was only present at minute amounts in the leaf tea. It improves the nutritive value of flowers and their by-products, and it may be converted into other types of fatty acids in the fruit as well; an aspect that deserves further research.
-
A total of 607 compounds were detected in tea made from the leaves, flowers, and young fruits of olive. The content and composition of metabolites in the olive tea made from the three tissues varied widely, and 129 common DAMs distinguished the olive teas. After further analysis, it was found that the great majority of compounds were related to the amino acid metabolism pathway, including alanine, aspartate and glutamate metabolism, tyrosine metabolism, and butanoate metabolism. Furthermore, 1,2,3,4-tetramethyl-1,3-cyclopentadiene, 3,4-dihydrocadalene, α-farnesene, and xanthumin are terpenes that likely contribute to the flavor of the leaves and flowers. Forty-four phenolic compounds were present in the flowers, most of which were flavonoids. The content of oleuropein, a characteristic functional ingredient, was highest in the leaf tea. In summary, the leaves, flowers, and young fruits of olive have great potential economic value, and thus further study of their health functions is warranted.
-
The authors confirm contribution to the paper as follows: study conception and design, funding aquisition, manuscript revision: Shen G, Zhu S; analysis and interpretation of results: Jiang C, Hu W; draft manuscript preparation: Jiang C; data analysis: Chen L, Lu H; data curation: Niu E, Wang W. All authors reviewed the results and approved the final version of the manuscript.
-
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
This work was supported by grants of the Key Research and Development Program of Zhejiang Province (2021C02002), the Key Scientific and Technological Grant of Zhejiang for Breeding New Agricultural Varieties (2021C02072-5). We thank LetPub (www.letpub.com) for its linguistic assistance during the preparation of this manuscript.
-
The authors declare that they have no conflict of interest.
- Supplemental Table S1 Compounds identified in tea made from the leaves, flowers and young fruits of olive.
- Copyright: © 2024 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Jiang C, Hu W, Chen L, Lu H, Niu E, et al. 2024. Comparative metabolite profiling reveals signatures of tea made from the leaves, flowers, and young fruits of olive (Olea europaea L.). Beverage Plant Research 4: e025 doi: 10.48130/bpr-0024-0014 

Comparative metabolite profiling reveals signatures of tea made from the leaves, flowers, and young fruits of olive (Olea europaea L.)
- Received: 02 January 2024
- Revised: 22 February 2024
- Accepted: 07 March 2024
- Published online: 04 July 2024
Abstract: Olive trees contain valuable bioactive compounds that are beneficial to the human body. Most studies have investigated the bioactive components of mature olive fruits. Much of the biomass from olive leaves, flowers, and young fruits is discarded every year because it is unclear if it can be utilized for its bioactive components. In the present study, the leaves, flowers, and young fruits of olive were made into tea, and their compositions were analyzed through high-performance liquid chromatography mass spectrometry. There were 44 phenolic compounds detected in the floral tea, most of which were flavonoids. Based on 607 components, the olive teas made from the three tissues were quite distinctive. There were 129 common differentially accumulated metabolites, which were mainly associated with the amino acid metabolism pathway. Additionally, terpenes and glycosides were abundant in the leaf and floral tea. The content of oleuropein was highest in the leaf tea, while the contents of fatty acids were highest in fruit tea. The current study indicates that the leaves, flowers, and young fruits of olive have great utilization value and deserve further investigation.